
Высокие темпы разработки сопряжены с рисками, влияющими на отказоустойчивость и стабильность — особенно если хочется экспериментировать и пробовать разное. Разработчик Маркета Мария Кузнецова рассказала о релизном цикле своей команды от и до, а также о мониторингах и других вещах, позволяющих обновлять сервис со скоростью три релиза в день.

— Всем привет! Я представляю бэкенд-разработку курьерской платформы. Поговорить хочу о том, как нам удается, с одной стороны, двигаться быстро, а, с другой стороны, не потонуть в ворохе и потоке проблем и ошибок.
(...) Сейчас у нас в среднем выкатывается по три релиза в день.

Стек технологий, которые мы используем типичен для Java-приложений Маркета. Мы используем 11-ю Java, Spring, PostgreSQL для хранения данных, Liquibase для накатывания миграций и Quartz для регулярных Cron-задач. Конечно, у нас реализовано много интеграций с внутренними сервисами.
Начать я хочу с того, как у нас устроен процесс релиза.
С самого начала проекта мы живем в парадигме trunk-based development. Чтобы код попал в продакшен, нужно поставить пул-реквест и пройти код-ревью. Причем в пул-реквесте запускаются также и прикоммитные проверки, в первую очередь это юнит-тесты и функциональные тесты.
Среды у нас сейчас только две — продакшен и тестинг. Когда код-ревью пройдено и код попал в trunk, запускается вот такой релизный пайплайн.

Дальше я покажу все шаги подробнее.

Начинается сборка релиза. На этапе сборки релиза опять прогоняются тесты. Про то, как мы пишем тесты, говорил Андрей, и в нашей команде мы разделяем этот подход. Релиз собрался, и дальше начинается сам процесс его выкатки. На слайде представлены сразу два шага — процесс попадания в тестинг и шаг проверки.

Все сервисы Маркета, за очень редким исключением, имеют минимум два инстанса, минимум один в каждом дата-центре. Раскатка релиза происходит поэтапно. Вначале один инстанс, или процент, если инстансов много, потом все остальные. Если вначале что-то идет не так, выкатка дальше не пойдет, релиз останавливается и нужно идти разбираться.
Всё, релиз раскатили. Идёт шаг проверки. По сути мы заменили ручной регресс тестирования на интеграционные тесты, но также добавили нагрузочные тесты. Самое главное: на каждом шаге мы пытаемся выявить проблему и не допустить, чтобы плохой код попал в продакшен.
Конечно, у нас есть ограничения при выкатке релиза. Парадигма trunk-based development диктует то, что не должно быть долго живущих feature branches, и получается так, что в trunk может оказаться незаконченная функциональность.
Никто не отменял обратную совместимость между соседними релизами. Но тут нам немножко попроще. Наши пользователи — курьеры, мы поддерживаем для них мобильное приложение. И можем курьерам форсированно обновлять версию мобильного приложения, поэтому обратную совместимость нам тоже нужно поддерживать ограниченное время. Оно задается тем, сколько мобильных приложений мы сейчас поддерживаем. Обычно только два последних, все остальные невалидны.
При чем здесь кот Шредингера? Часто новая функциональность в продакшене должна и работать, и не работать одновременно: для каких-то пользователей должна быть включена, а для других все должно работать по-старому. Можно было бы, конечно, поднять отдельный инстанс, бэкенд с новой функциональностью, пустить туда какую-то часть пользователей, а остальных оставить на старых.
Но такой подход звучит дорого.
Поэтому мы пришли к тому, что стали использовать feature toggles. Toggles с английского переводится как переключатель, и это в точности описывает его предназначение.
Можно выкатить код и пока не использовать его в продашкене, например, ждать поддержки фронтенда или же дальше его реализовывать.
Нам очень важно уметь включать-выключать функциональность по отмашке от коллег. Поэтому свой toggles мы сложили в базу.
Поскольку функциональность не всегда нужно сразу включать на всех пользователей, сделали feature toggles на пользователя и тоже положили их в базу. Так мы можем точечно включать функциональность, и это дает возможность провести эксперименты. Например, мы делали новую функциональность под кодовым названием «Звонки». Это напоминание курьеру о том, что у него скоро доставка. (...) Такая функциональность сильно перестраивала процесс работы курьера, и нам было важно проверить, как процесс летит в реальном времени, в реальной жизни.
По первым результатам эксперимента мы поняли, что после звонка курьеру некуда записать комментарии от пользователя. Поэтому срочно добавили комментарии и возможность работы с ними. И дальше уже пользователей в эксперимент добавляли только с этой функциональностью. С помощью feature toggles у нас сделана выкатка на процент пользователей. Мы храним версию и требуем от курьера, чтобы у него была установлена именно она. В противном случае просим его обновиться.

Конечно, у такого подхода есть минусы. Toggles скапливаются, и здесь ничего не остается, кроме как их убирать. Также увеличивается сложность тестов, потому что проверять свой код нужно во всех режимах работы toggles. Кроме того, toggles лежат в базе, поэтому получается лишний поход в БД. Здесь ничего не остается, кроме как поставить кэш. Какие плюсы мы за это получаем?

Мы получаем возможность спокойно жить в парадигме trunk based development. Также можем проводить точечные эксперименты на пользователях.
Я уже приводила пример со звонками. Мы поддерживаем не просто изменение кода — зачастую это изменение бизнес-процессов. Нам нужно проверять еще и то, насколько готов офлайн, как хорошо мы донесли это до курьеров, что мы от них хотим.
Мобильное приложение обычно тоже раскатывается не сразу на всех пользователей, а вначале на какой-то процент из них. И мы можем получить такую ситуацию, что в зависимости от пользователя бэкенд должен иметь разную логику. Это не только изменения в API, но и именно изменения в бизнес-логике. Toggles нам тоже помогают решить такую задачу.
Остался вопрос про деградацию. Мы обслуживаем офлайн-процесс, и в случае любых проблем с ПО нам нужно сделать так, чтобы самая важная часть функциональности работала. Чтобы курьеры могли выдать посылку, выбить чек и понять, куда ехать дальше.
А вот если, например, у нас возникли проблемы с фото посылки, можно отключить эту функциональность, разобраться с проблемой, устранить ее и включить обратно.
Выкатили релиз, включили функциональность. Казалось бы, наша работа закончена, можно расслабиться. Но нет, начинается самое интересное. Мы должны понимать, что происходит в продакшене прямо сейчас, и находить проблемы раньше, чем они начнут мешать нашим пользователям.
Поэтому дальше я хочу поговорить о метриках и мониторингах. Сразу скажу: в этой части мы не будем обсуждать, какие системы сбора и визуализации метрик использовать. Для этого есть опенсорс-решения. У себя для сбора метрик мы используем Graphite и, как и для мониторингов, внутреннюю систему.
Какую информацию мы собираем? На слайд я выписала формальное определение метрик и мониторинга.

Но предлагаю рассмотреть, что это такое, на примере.

Метрика обычно представляется как график, он описывает какой-то параметр нашей системы. А мониторинг — это событие, превышение заданного ранее порога и какое-то действие, которое необходимо предпринять при превышении порога.
Какие могут быть действия? Конечно, самое важное — уведомить ответственных: написать в мессенджер или позвонить. Реже — запустить процесс откатки последнего релиза. У себя в проекте мы такой вариант не используем. Еще есть вариант мониторинга, который мы называем «загорается лампочка». Произошло интересующее нас событие, и оно отобразилось в интерфейсе мониторинга. Дальше тоже происходит действие — уведомить ответственных или еще что-то.

Мы говорим про Java-приложение, а оно должно быть где-то запущено, будь то контейнеры или железные машины. Ресурсы и в том, и в другом случае для нас конечны, нам нужно понимать, как мы их используем. Наши приложения мы запускаем во внутреннем облаке, облако нам предоставляет всю подобную информацию. Информацию о ресурсах стоит собирать не только на контейнерах, где живет ваше приложение, но и там, где работает ваше хранилище.
На слайде пример, как нам в базе перестало хватать CPU.
Окей, у нас Java-приложение, и, конечно, стоит собирать информацию о состоянии JVM.

Мы используем Spring, поэтому для решения такой задачи хорошо подходит библиотека Spring Boot Actuator. Она добавляет endpoint в ваше приложение, и к этому endpoint можно обратиться по http и получить необходимую информацию о памяти или что-то еще. Окей, приложение запущено. Дальше оно вообще работает или нет? Что с ним происходит? Можно отправлять запросы в это приложение или нет?
Такие вещи нужно понимать не только нам, но и балансеру. Для этого мы добавляем в приложение контроллер с двумя методами — Ping и Monitoring. Рассмотрим вначале Ping. Он отвечает на вопросы, живо ли приложение, можно ли отправлять на него запросы. И отвечает он это в первую очередь не нам, но балансеру. Но мы же используем этот метод для мониторинга того, живо приложение или нет.
Метод Monitoring дает нам возможность получать сообщения о неполадках в системе. Например, не удалось загрузить знания, с которыми работает приложение, или не удалось их обновить. Или же процесс по распределению заказов между курьерами закончился ошибкой.
Мониторинги строятся на системе статусов и приоритетов между ними. Событие мониторинга в минимальном варианте описывается именем, временем, до которого действует мониторинг, но и статусом. По истечении этого времени мониторинг считается пройденным, погашенным и переходит в статус «ok».
Получается такой простейший интерфейс мониторинга. Добавить или обновить событие и вернуть текущее состояние мониторинга в оговоренном формате.
У нас есть клиент — мобильное приложение, нужно понимать, как качественно мы отвечаем клиенту и какая вообще нагрузка на нас идет. Поэтому стоит собирать RPS, тайминги и пятисотки.
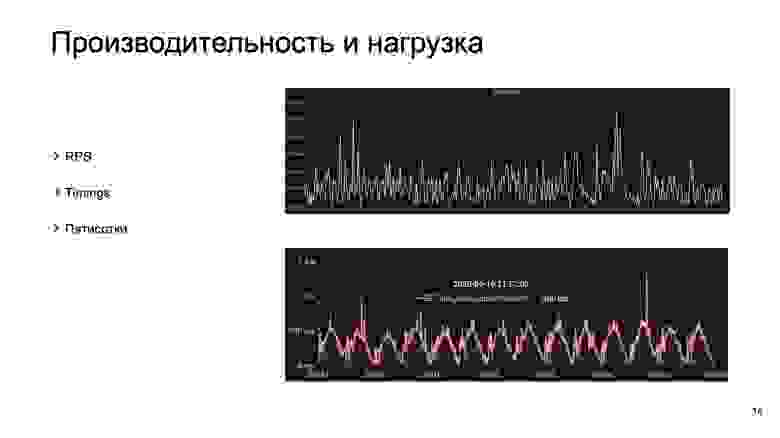
Как мерить RPS, понятно из названия. Стоит отметить, что хорошо смотреть как общий RPS по приложению, так и по отдельным методам API. А вот с двумя остальными — с таймингами и пятисотками — все не так понятно. В каждый момент времени может быть много запросов и, соответственно, много времен ответов. Всю эту информацию нужно агрегировать. Для этого хорошо подходят перцентили. Этот термин пришел к нам из статистики.
Чтобы рассказать, что это такое, на слайде есть нижний график, на нем выделена точка в 400 мс. Это график 99 перцентиля какого-то метода из нашего API. Что значат эти 400 мс? Что в этот момент 99% запросов отрабатывали не хуже 400 мс.
Остались пятисотки. Не стоит мерить просто количество пятисоток, потому что не будет понятен масштаб. Стоит мерить долю или процент. Но собирать можно не только пятисотые коды ответа, но и любые другие коды, которые вам могут быть интересны.
Как мы собираем RPS, тайминги и пятисотки? Когда запрос оказался у нас в инфраструктуру, он попадает на L7 balancer. А дальше он не сразу попадает в приложение, перед этим есть nginx.

А вот уже из nginx он попадает в приложение. У nginx есть access.log, в который можно собирать всю необходимую информацию. Это коды ответа, время ответа и сам запрос.

Часто, когда возникают проблемы с временем ответа или пятисотки, стоит посмотреть, что в это время было с хранилищем.
У нас PostgreSQL, поэтому мы именно его мониторим и смотрим. Мы строим все эти графики не сами — они нам предоставляются облаком, в котором развернута наша база. Что у нас есть? Количество запросов, транзакций, лаг репликации, среднее время транзакции и так далее. На самом деле на этих графиках представлен факап, который у нас произошел.

Вообще-то мы работаем с реальным процессом, и он нам тоже диктует, на что нам нужно посмотреть. Регистрацию нежелательных событий мы уже рассматривали, для этого хорошо подходит метод Monitoring, он был ранее.
Осталась статистика по хранилищу. Хранилище вообще может многое рассказать о состоянии нашей системы. Можно считать показатели: как, например, количество заказов за день, так и просто попадание в интервал доставки. Можно искать противоречия статусной модели. Так мы отслеживаем чеки, с которыми возникли проблемы.
Но далеко не всегда на такие мониторинги должна реагировать разработка. Очень часто на них вначале нужна реакция бизнеса. Вообще задача получения статистики по хранилищу выходит однотипной. Нужно сходить в базу, рассчитать статистику, а результат записать в key-value-лог. Поэтому мы сделали обертку для таких задач.
Сложили в базу такую тройку: уникальный ключ для метрики, сам запрос, в котором можно эту метрику посчитать, и Cron-выражение, когда считать. То есть в базе получилась тройка: ключ — запрос — cron expression. А над всей этой тройкой сделали Cron-задачу, которая достает ее из хранилища и добавляет к общему пулу Cron-задач. Дальше эта задача выполняется.
Итого, что мы получаем?
И, конечно, давайте будем писать код без багов, тогда у нас вообще все будет хорошо. На этом у меня все.
— Всем привет! Я представляю бэкенд-разработку курьерской платформы. Поговорить хочу о том, как нам удается, с одной стороны, двигаться быстро, а, с другой стороны, не потонуть в ворохе и потоке проблем и ошибок.
(...) Сейчас у нас в среднем выкатывается по три релиза в день.

Стек технологий, которые мы используем типичен для Java-приложений Маркета. Мы используем 11-ю Java, Spring, PostgreSQL для хранения данных, Liquibase для накатывания миграций и Quartz для регулярных Cron-задач. Конечно, у нас реализовано много интеграций с внутренними сервисами.
Начать я хочу с того, как у нас устроен процесс релиза.
1. Релизы
С самого начала проекта мы живем в парадигме trunk-based development. Чтобы код попал в продакшен, нужно поставить пул-реквест и пройти код-ревью. Причем в пул-реквесте запускаются также и прикоммитные проверки, в первую очередь это юнит-тесты и функциональные тесты.
Среды у нас сейчас только две — продакшен и тестинг. Когда код-ревью пройдено и код попал в trunk, запускается вот такой релизный пайплайн.
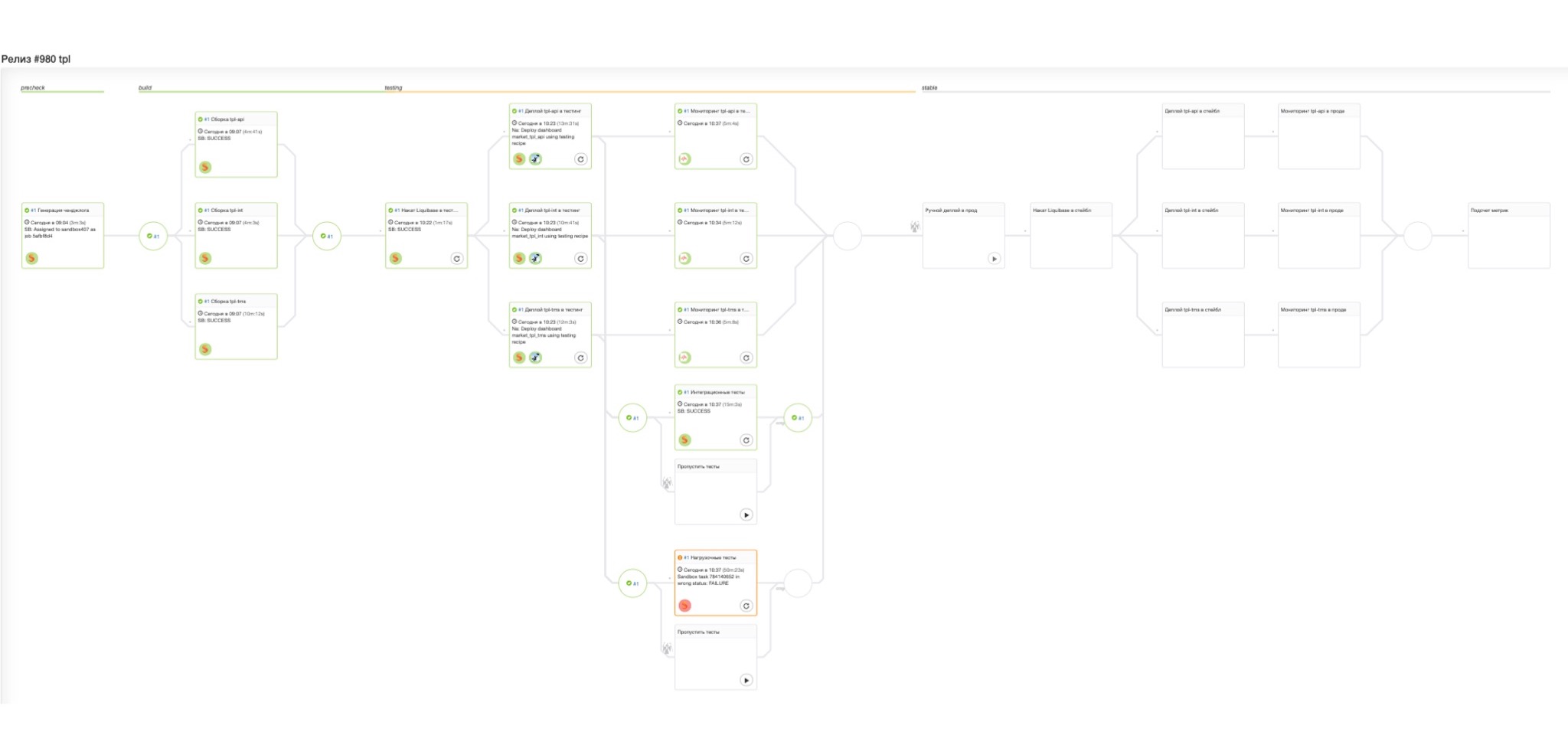
Дальше я покажу все шаги подробнее.
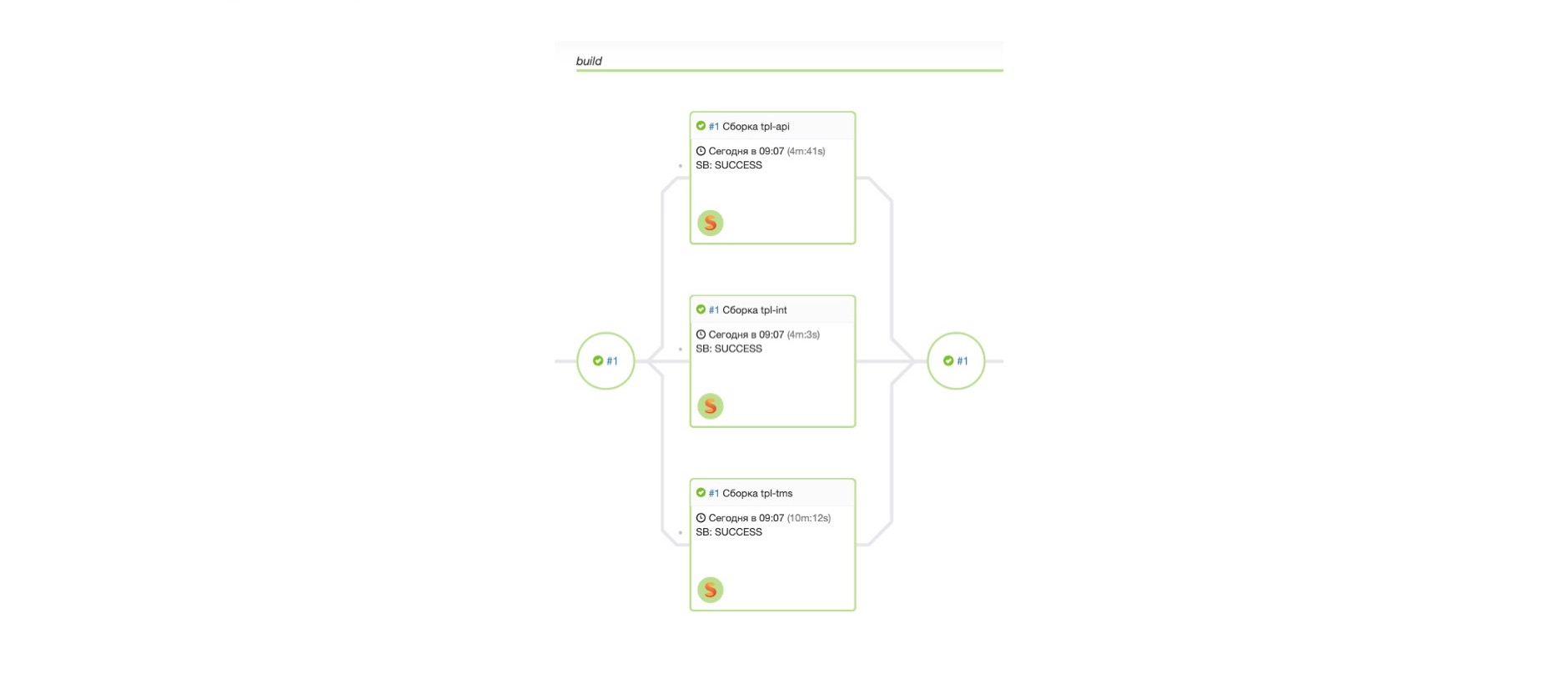
Начинается сборка релиза. На этапе сборки релиза опять прогоняются тесты. Про то, как мы пишем тесты, говорил Андрей, и в нашей команде мы разделяем этот подход. Релиз собрался, и дальше начинается сам процесс его выкатки. На слайде представлены сразу два шага — процесс попадания в тестинг и шаг проверки.

Все сервисы Маркета, за очень редким исключением, имеют минимум два инстанса, минимум один в каждом дата-центре. Раскатка релиза происходит поэтапно. Вначале один инстанс, или процент, если инстансов много, потом все остальные. Если вначале что-то идет не так, выкатка дальше не пойдет, релиз останавливается и нужно идти разбираться.
Всё, релиз раскатили. Идёт шаг проверки. По сути мы заменили ручной регресс тестирования на интеграционные тесты, но также добавили нагрузочные тесты. Самое главное: на каждом шаге мы пытаемся выявить проблему и не допустить, чтобы плохой код попал в продакшен.
Конечно, у нас есть ограничения при выкатке релиза. Парадигма trunk-based development диктует то, что не должно быть долго живущих feature branches, и получается так, что в trunk может оказаться незаконченная функциональность.
Никто не отменял обратную совместимость между соседними релизами. Но тут нам немножко попроще. Наши пользователи — курьеры, мы поддерживаем для них мобильное приложение. И можем курьерам форсированно обновлять версию мобильного приложения, поэтому обратную совместимость нам тоже нужно поддерживать ограниченное время. Оно задается тем, сколько мобильных приложений мы сейчас поддерживаем. Обычно только два последних, все остальные невалидны.
При чем здесь кот Шредингера? Часто новая функциональность в продакшене должна и работать, и не работать одновременно: для каких-то пользователей должна быть включена, а для других все должно работать по-старому. Можно было бы, конечно, поднять отдельный инстанс, бэкенд с новой функциональностью, пустить туда какую-то часть пользователей, а остальных оставить на старых.
Но такой подход звучит дорого.
2. Feature toggles
Поэтому мы пришли к тому, что стали использовать feature toggles. Toggles с английского переводится как переключатель, и это в точности описывает его предназначение.
if (configurationService.isBooleanEnabled(NEW_FEATURE_ENABLED)) {
//new feature here
} else {
//old logic
}Можно выкатить код и пока не использовать его в продашкене, например, ждать поддержки фронтенда или же дальше его реализовывать.
Нам очень важно уметь включать-выключать функциональность по отмашке от коллег. Поэтому свой toggles мы сложили в базу.
public class User {
private Map<String, UserProperty> properties = new HashMap<>();
String getPropertyValue(String key) {
UserPropertyEntity userProperty = properties.get(key);
return userProperty == null ? null : userProperty.getValue();
}
}Поскольку функциональность не всегда нужно сразу включать на всех пользователей, сделали feature toggles на пользователя и тоже положили их в базу. Так мы можем точечно включать функциональность, и это дает возможность провести эксперименты. Например, мы делали новую функциональность под кодовым названием «Звонки». Это напоминание курьеру о том, что у него скоро доставка. (...) Такая функциональность сильно перестраивала процесс работы курьера, и нам было важно проверить, как процесс летит в реальном времени, в реальной жизни.
По первым результатам эксперимента мы поняли, что после звонка курьеру некуда записать комментарии от пользователя. Поэтому срочно добавили комментарии и возможность работы с ними. И дальше уже пользователей в эксперимент добавляли только с этой функциональностью. С помощью feature toggles у нас сделана выкатка на процент пользователей. Мы храним версию и требуем от курьера, чтобы у него была установлена именно она. В противном случае просим его обновиться.

Конечно, у такого подхода есть минусы. Toggles скапливаются, и здесь ничего не остается, кроме как их убирать. Также увеличивается сложность тестов, потому что проверять свой код нужно во всех режимах работы toggles. Кроме того, toggles лежат в базе, поэтому получается лишний поход в БД. Здесь ничего не остается, кроме как поставить кэш. Какие плюсы мы за это получаем?

Мы получаем возможность спокойно жить в парадигме trunk based development. Также можем проводить точечные эксперименты на пользователях.
Я уже приводила пример со звонками. Мы поддерживаем не просто изменение кода — зачастую это изменение бизнес-процессов. Нам нужно проверять еще и то, насколько готов офлайн, как хорошо мы донесли это до курьеров, что мы от них хотим.
Мобильное приложение обычно тоже раскатывается не сразу на всех пользователей, а вначале на какой-то процент из них. И мы можем получить такую ситуацию, что в зависимости от пользователя бэкенд должен иметь разную логику. Это не только изменения в API, но и именно изменения в бизнес-логике. Toggles нам тоже помогают решить такую задачу.
Остался вопрос про деградацию. Мы обслуживаем офлайн-процесс, и в случае любых проблем с ПО нам нужно сделать так, чтобы самая важная часть функциональности работала. Чтобы курьеры могли выдать посылку, выбить чек и понять, куда ехать дальше.
А вот если, например, у нас возникли проблемы с фото посылки, можно отключить эту функциональность, разобраться с проблемой, устранить ее и включить обратно.
Выкатили релиз, включили функциональность. Казалось бы, наша работа закончена, можно расслабиться. Но нет, начинается самое интересное. Мы должны понимать, что происходит в продакшене прямо сейчас, и находить проблемы раньше, чем они начнут мешать нашим пользователям.
3. Метрики и мониторинги
Поэтому дальше я хочу поговорить о метриках и мониторингах. Сразу скажу: в этой части мы не будем обсуждать, какие системы сбора и визуализации метрик использовать. Для этого есть опенсорс-решения. У себя для сбора метрик мы используем Graphite и, как и для мониторингов, внутреннюю систему.
Какую информацию мы собираем? На слайд я выписала формальное определение метрик и мониторинга.

Но предлагаю рассмотреть, что это такое, на примере.
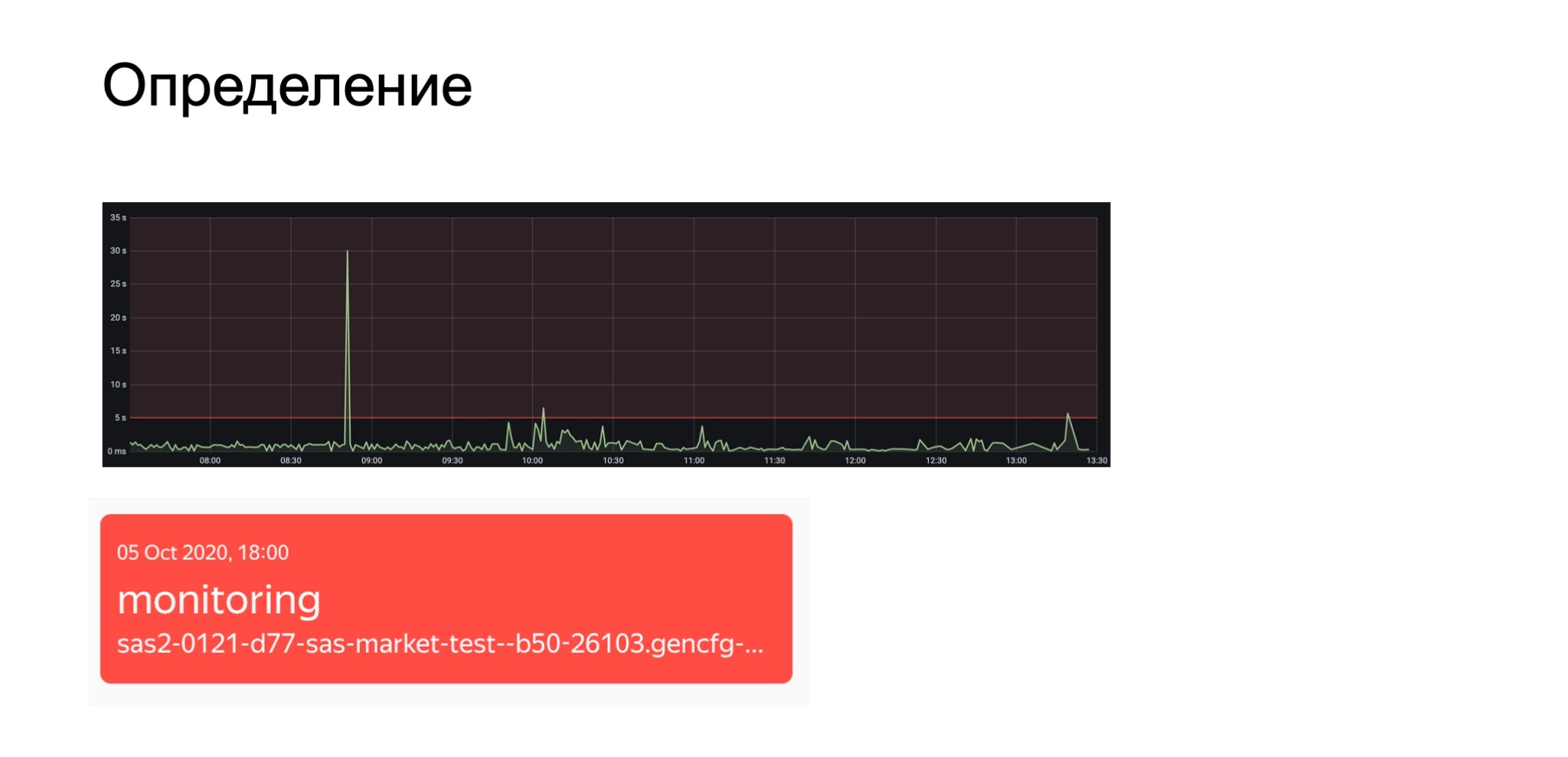
Метрика обычно представляется как график, он описывает какой-то параметр нашей системы. А мониторинг — это событие, превышение заданного ранее порога и какое-то действие, которое необходимо предпринять при превышении порога.
Какие могут быть действия? Конечно, самое важное — уведомить ответственных: написать в мессенджер или позвонить. Реже — запустить процесс откатки последнего релиза. У себя в проекте мы такой вариант не используем. Еще есть вариант мониторинга, который мы называем «загорается лампочка». Произошло интересующее нас событие, и оно отобразилось в интерфейсе мониторинга. Дальше тоже происходит действие — уведомить ответственных или еще что-то.

Мы говорим про Java-приложение, а оно должно быть где-то запущено, будь то контейнеры или железные машины. Ресурсы и в том, и в другом случае для нас конечны, нам нужно понимать, как мы их используем. Наши приложения мы запускаем во внутреннем облаке, облако нам предоставляет всю подобную информацию. Информацию о ресурсах стоит собирать не только на контейнерах, где живет ваше приложение, но и там, где работает ваше хранилище.
На слайде пример, как нам в базе перестало хватать CPU.
Окей, у нас Java-приложение, и, конечно, стоит собирать информацию о состоянии JVM.
Мы используем Spring, поэтому для решения такой задачи хорошо подходит библиотека Spring Boot Actuator. Она добавляет endpoint в ваше приложение, и к этому endpoint можно обратиться по http и получить необходимую информацию о памяти или что-то еще. Окей, приложение запущено. Дальше оно вообще работает или нет? Что с ним происходит? Можно отправлять запросы в это приложение или нет?
@RestController
@RequiredArgsConstructor
public class MonitoringController {
private final ComplexMonitoring generalMonitoring;
private final ComplexMonitoring pingMonitoring;
@RequestMapping(value = "/ping")
public String ping() {
return pingMonitoring.getResult();
}
@RequestMapping(value = "/monitoring")
public String monitoring() {
return generalMonitoring.getResult();
}
}Такие вещи нужно понимать не только нам, но и балансеру. Для этого мы добавляем в приложение контроллер с двумя методами — Ping и Monitoring. Рассмотрим вначале Ping. Он отвечает на вопросы, живо ли приложение, можно ли отправлять на него запросы. И отвечает он это в первую очередь не нам, но балансеру. Но мы же используем этот метод для мониторинга того, живо приложение или нет.
Метод Monitoring дает нам возможность получать сообщения о неполадках в системе. Например, не удалось загрузить знания, с которыми работает приложение, или не удалось их обновить. Или же процесс по распределению заказов между курьерами закончился ошибкой.
public enum MonitoringStatus {
OK,
WARNING,
CRITICAL;
}
@RequiredArgsConstructor
public class MonitoringEvent {
private final String name;
private volatile long validTill;
private volatile MonitoringStatus status;
}Мониторинги строятся на системе статусов и приоритетов между ними. Событие мониторинга в минимальном варианте описывается именем, временем, до которого действует мониторинг, но и статусом. По истечении этого времени мониторинг считается пройденным, погашенным и переходит в статус «ok».
public interface ComplexMonitoring {
void addTemporary(String name, MonitoringStatus status, long validTillMilis);
Result getResult(); //тут можно делать проверку для статусов в MonitoringEvent
} Получается такой простейший интерфейс мониторинга. Добавить или обновить событие и вернуть текущее состояние мониторинга в оговоренном формате.
У нас есть клиент — мобильное приложение, нужно понимать, как качественно мы отвечаем клиенту и какая вообще нагрузка на нас идет. Поэтому стоит собирать RPS, тайминги и пятисотки.
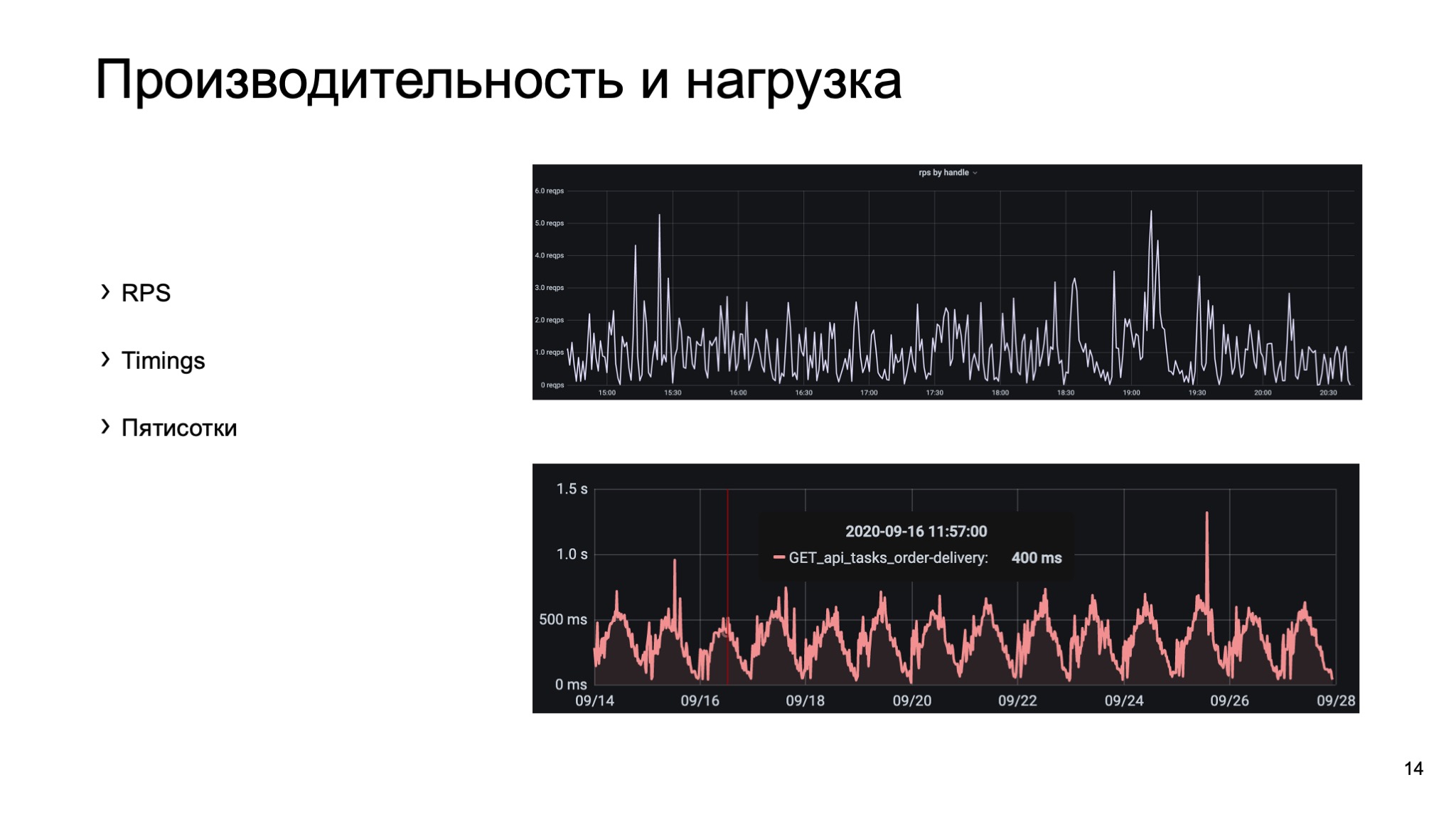
Как мерить RPS, понятно из названия. Стоит отметить, что хорошо смотреть как общий RPS по приложению, так и по отдельным методам API. А вот с двумя остальными — с таймингами и пятисотками — все не так понятно. В каждый момент времени может быть много запросов и, соответственно, много времен ответов. Всю эту информацию нужно агрегировать. Для этого хорошо подходят перцентили. Этот термин пришел к нам из статистики.
Чтобы рассказать, что это такое, на слайде есть нижний график, на нем выделена точка в 400 мс. Это график 99 перцентиля какого-то метода из нашего API. Что значат эти 400 мс? Что в этот момент 99% запросов отрабатывали не хуже 400 мс.
Остались пятисотки. Не стоит мерить просто количество пятисоток, потому что не будет понятен масштаб. Стоит мерить долю или процент. Но собирать можно не только пятисотые коды ответа, но и любые другие коды, которые вам могут быть интересны.
Как мы собираем RPS, тайминги и пятисотки? Когда запрос оказался у нас в инфраструктуру, он попадает на L7 balancer. А дальше он не сразу попадает в приложение, перед этим есть nginx.
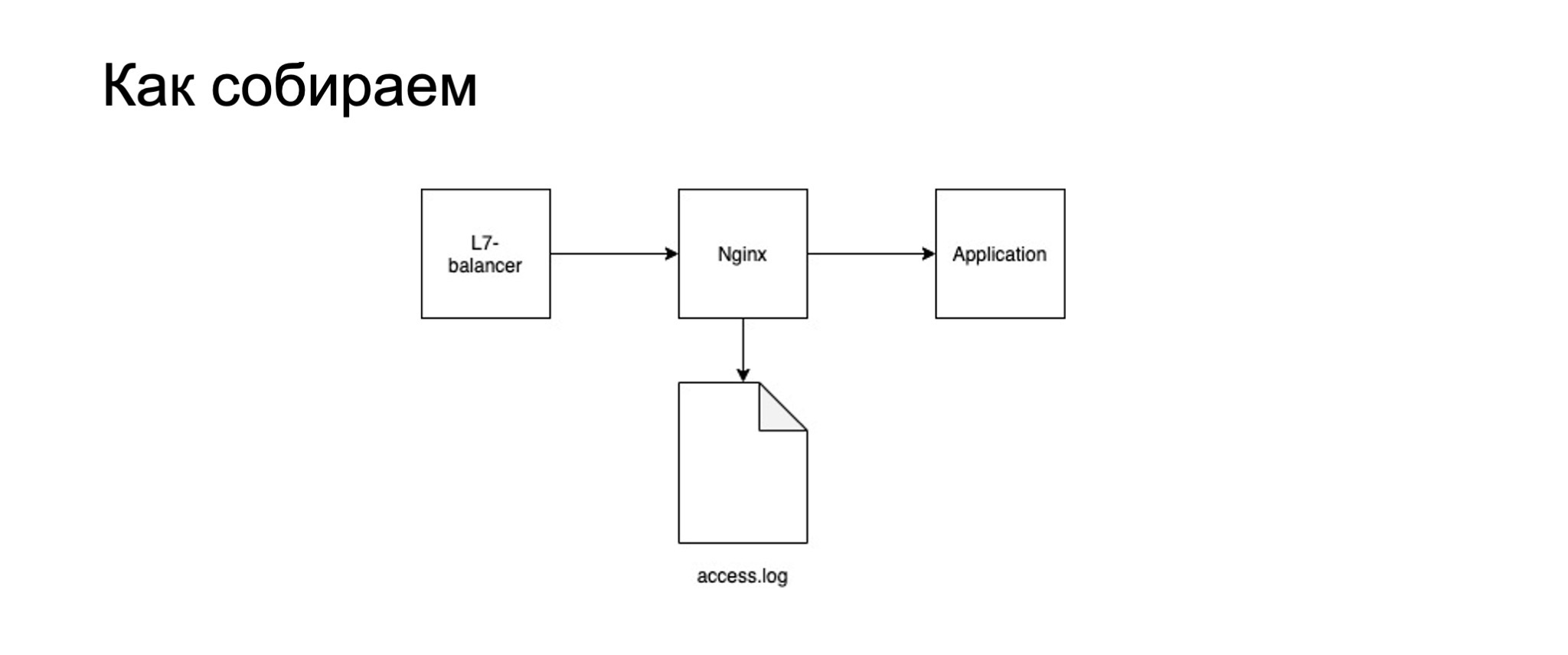
А вот уже из nginx он попадает в приложение. У nginx есть access.log, в который можно собирать всю необходимую информацию. Это коды ответа, время ответа и сам запрос.
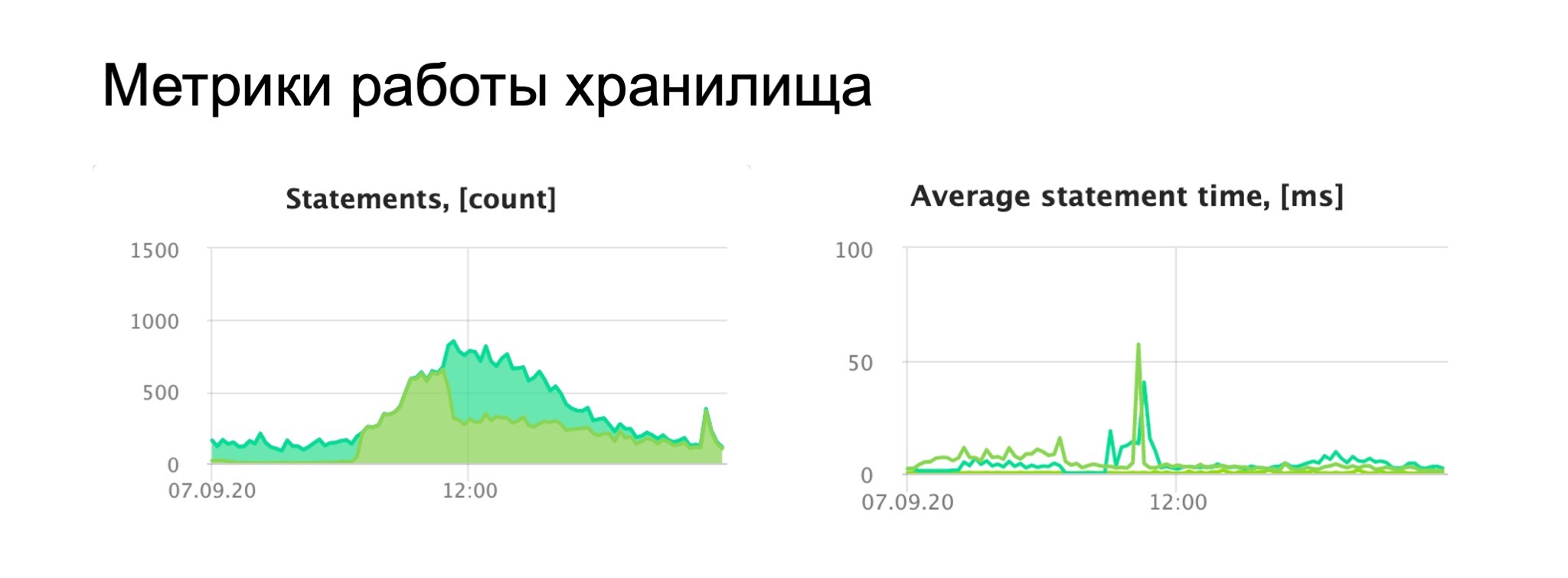
Часто, когда возникают проблемы с временем ответа или пятисотки, стоит посмотреть, что в это время было с хранилищем.
У нас PostgreSQL, поэтому мы именно его мониторим и смотрим. Мы строим все эти графики не сами — они нам предоставляются облаком, в котором развернута наша база. Что у нас есть? Количество запросов, транзакций, лаг репликации, среднее время транзакции и так далее. На самом деле на этих графиках представлен факап, который у нас произошел.

Вообще-то мы работаем с реальным процессом, и он нам тоже диктует, на что нам нужно посмотреть. Регистрацию нежелательных событий мы уже рассматривали, для этого хорошо подходит метод Monitoring, он был ранее.
Осталась статистика по хранилищу. Хранилище вообще может многое рассказать о состоянии нашей системы. Можно считать показатели: как, например, количество заказов за день, так и просто попадание в интервал доставки. Можно искать противоречия статусной модели. Так мы отслеживаем чеки, с которыми возникли проблемы.
public class MetricQueryRealJobExecutor {
private static final RowMapper<Metric> METRIC_ROW_MAPPER = BeanPropertyRowMapper.newInstance(Metric.class);
private final JdbcTemplate jdbcTemplate;
public void doJob(MetricQuery task) {
List<Metric> metrics = jdbcTemplate.query(task.getQuery(), METRIC_ROW_MAPPER);
metrics.forEach(metric -> KEY_VALUE_LOG.info(KeyValueLogFormat.format(metric))
);
}
@Data
private static class Metric {
private String key;
private double value;
}
} Но далеко не всегда на такие мониторинги должна реагировать разработка. Очень часто на них вначале нужна реакция бизнеса. Вообще задача получения статистики по хранилищу выходит однотипной. Нужно сходить в базу, рассчитать статистику, а результат записать в key-value-лог. Поэтому мы сделали обертку для таких задач.
Сложили в базу такую тройку: уникальный ключ для метрики, сам запрос, в котором можно эту метрику посчитать, и Cron-выражение, когда считать. То есть в базе получилась тройка: ключ — запрос — cron expression. А над всей этой тройкой сделали Cron-задачу, которая достает ее из хранилища и добавляет к общему пулу Cron-задач. Дальше эта задача выполняется.
Итого, что мы получаем?
- Плохой код не должен попадать в продакшен, для этого мы ставим всевозможные преграды: тесты, стрельбы, мониторинги. Задача без тестов не считается сделанной. Лучше заниматься оптимизацией работы тестов, чем получить проблему в продакшене.
- Feature toggles помогают нам управлять логикой работы бэкенда, а мы, в свою очередь, можем легко управлять toggles, и их плюсы все-таки перевешивают минусы.
- Мы должны уметь быстро обнаруживать проблему, в идеале — раньше, чем ее заметят наши пользователи. Но ее мало обнаружить, нужно еще ее интерпретировать. Поэтому собирайте много метрик о состоянии системы. Это помогает в поиске проблемы.
И, конечно, давайте будем писать код без багов, тогда у нас вообще все будет хорошо. На этом у меня все.
