
Хеш-таблицы — это королевы структур данных. Нигде не сломано так много копий, как на оптимизации хеш-таблиц. В докладе я рассказал ещё об одной хеш-таблице, которая используется в ClickHouse. Вы увидите, что zero-cost abstractions в современном С++ оправдывают себя и как с помощью небольших трюков получить разнообразные структуры данных из общей кодовой базы. На основе общих строительных блоков можно построить быстроочищаемую хеш-таблицу, несколько видов LRU-кешей, lookup-таблицы без хешей, хеш-таблицы для строк и т. п. Я показал, как получить максимальную производительность на конкретных сценариях и не ошибиться при её тестировании. В моём докладе — самая мякотка низкоуровневых оптимизаций. В общем, то, что мы любим.
— Для начала мы обсудим, зачем нужны хеш-таблицы, где их можно использовать в базах данных и как сделать их оптимальными. Затем посмотрим бенчмарки различных хеш-таблиц в интернете и разбёремся, как делать их правильно. В конце посмотрим на C++-обертку над идеальной хеш-таблицей в ClickHouse.
Все знают, что ClickHouse не тормозит, но не все знают, почему. Самая важная часть в ClickHouse — это GROUP BY. Чтобы делать GROUP BY оптимально, мы складываем все данные в хеш-таблицу. У нас около 40 различных оптимизаций операций GROUP BY, но каждая из них под собой так или иначе использует высокооптимизированную хеш-таблицу.
Если сказать, что у нас одна хеш-таблица, это будет не совсем верно. У нас их очень много, мы написали настоящий фреймворк для хеш-таблиц. Также хеш-таблицы у нас используются в JOIN и в операции SELECT DISTINCT.

Хеш-таблица — это структура данных, которая обеспечивает константные операции в среднем: insert, lookup и удаление, если оно вам нужно. В наших сценариях агрегации данных GROUP BY удаление нас не очень интересует.
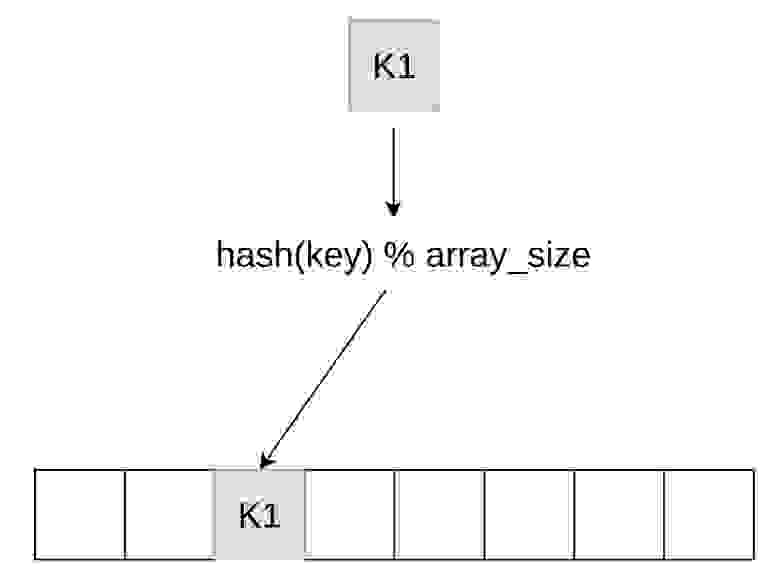
Посмотрим на картинку. Все знают, как хеш-таблица устроена, например, из курса университета. Мы берем некий ключ, который хотим положить, берем хеш-функцию, хешируем этот ключ, выбираем в массиве какой-нибудь слот по остатку от деления и кладем ключ в этот слот.
Таблица состоит из очень многих маленьких компонентов, это очень сложная структура данных. Каждый из этих компонентов очень важен, ошибка в любом из них сделает вашу таблицу неэффективной, она будет тормозить и не приносить вам zero-cost. Хеш-таблица состоит из хеш-функции, способа разрешения коллизий, политики ресайза и разных возможностей размещения ее ячеек в памяти.
Начнем с выбора хеш-функции. Это очень важный элемент, и многие уже на нем допускают ошибку. Кажется, как можно допустить ошибку с выбором, ведь так просто воспользоваться какой-либо хеш-функцией. Но я приведу основные проблемы и грабли.
В первую очередь, для целочисленных типов довольно часто многие используют хеш-функцию identity. Это неправильно, так как распределение реальных данных не такое и у вас будет множество коллизий. Еще не стоит использовать хеш-функции для строк, для чисел, так как они будут тормозить, компилятор не производит inline-подстановку сложных хеш-функций, например функций типа City Hash. Также не стоит использовать различные криптографические хеш-функции, если вас не атакуют злоумышленники. Предположим, пропускная способность вычисления функции Sip Hash — 1 ГБ/с, а функции City Hash — около 10 ГБ/с. Значит, пропускная способность вашей таблицы будет ограничена сверху 1 ГБ/с.
Кроме того, не стоит использовать устаревшие хеш-функции, например FNV1a, потому что они медленные и имеют плохое распределение относительно конкурентов. FNV1a используется в стандартной библиотеке GCC. Это устаревшая хеш-функция, на GitHub есть репозиторий SMHasher с тестами разных хеш-функций. Там видно, что эта хеш-функция не проходит никакие серьезные тесты.
Теперь я расскажу, какие хеш-функции используются в ClickHouse. По умолчанию используются плохие хеш-функции, они дают плохое распределение, но хороши для хеш-таблиц. Например, для целочисленных типов мы используем CRC-32C, эта хеш-функция занимает очень мало времени процессора, выполняется очень быстро и представляет собой две инструкции. Для строк мы используем свою кастомную хеш-функцию, построенную на CRC-32C. Если не использовать ее, можно использовать что-нибудь стандартное — City Hash.
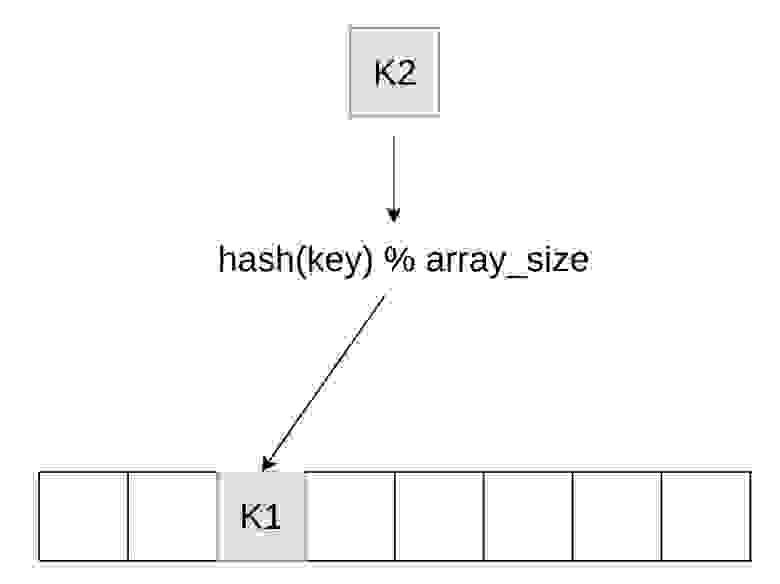
Поговорим про разрешения коллизий. В любой хеш-таблице по парадоксу дня рождения будет возникать ситуация, что один и тот же ключ попадает в один и тот же слот. Предположим, мы вставили ключ К1 и он попал в третий слот таблицы. Теперь мы пытаемся вставлять ключ К2, и получилось, что по остатку от деления он попадает в тот же слот. Нужно придумать, что с ним делать дальше. Есть несколько способов разрешения такой ситуации.
Первый способ — использовать chaining. То есть ячейка таблицы будет использовать список или массив, и мы будем класть следующий ключ в эту же ячейку, используя нижележащую структуру данных.
Есть другой способ — использовать метод открытой адресации. В данном случае мы кладем ключ в один из следующих слотов таблицы.
Есть и более сложные способы, например Cuckoo hashing или two way hashing. У них есть проблема: обычно они сложны в реализации, требуют дополнительных фетчей из памяти и обычно тормозят. К примеру, даже много кода на hot path очень сильно замедляет lookup в хеш-таблице.
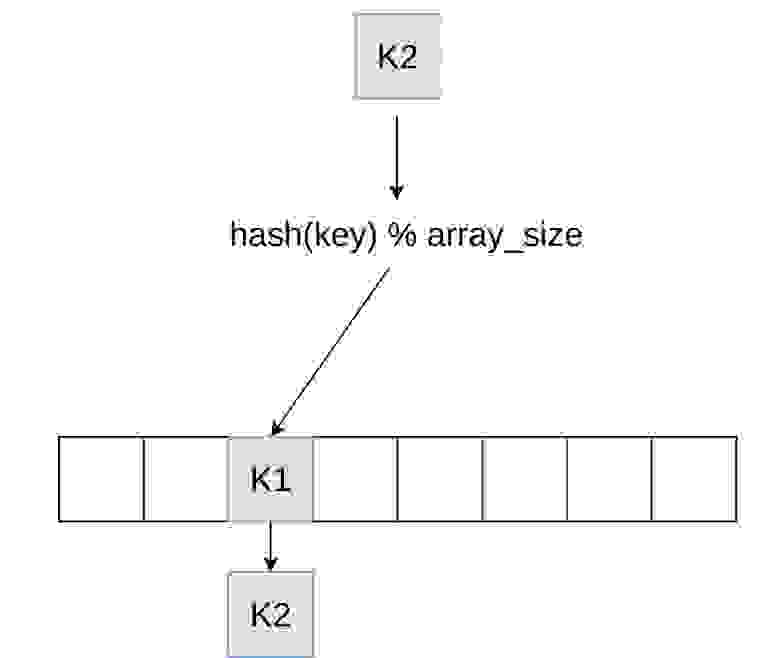
Начнем с самого простого метода — метода цепочек. Мы пытаемся положить второй ключ в ячейку с первым ключом. Под ним мы будем использовать список, кладем его в этот список, а затем при поиске будем проверять каждый ключ в списке.
Такой способ используется в std::unordered_map. Почему этот способ не эффективен? Он не кеш-локален, будет тормозить. Его эффективность в том, что он будет работать во всех случаях, не сильно привередлив к хеш-функции, будет работать даже с высоким loot factor. Но, к сожалению, он будет очень сильно нагружать аллокатор, так как даже вызов какой-либо функции на hot path lookup в хеш-таблице — это очень дорого.
Во всех современных хеш-таблицах используется метод открытой адресации.
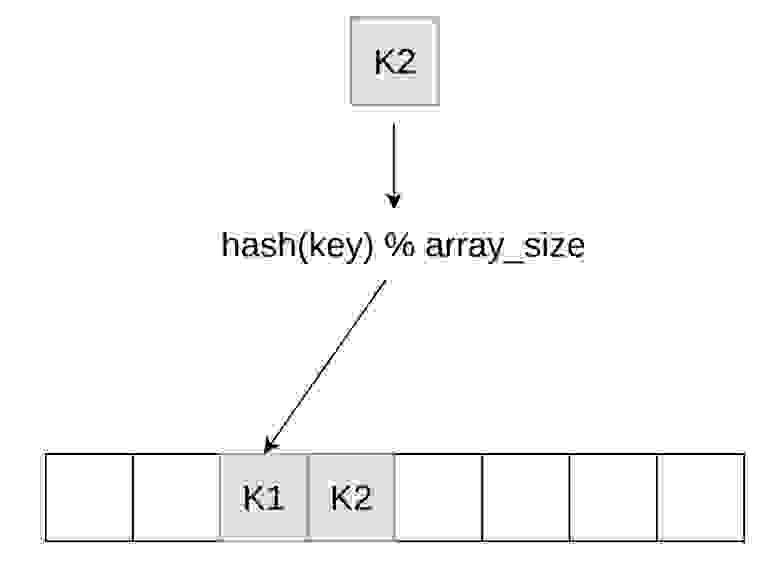
Сегодня в докладе я буду говорить про три хеш-таблицы, на которые стоит обратить внимание. Две из них — это Google Flat Hash Map и Google Abseil Hash Map. Abseil — один из новый фреймворков Google, в котором коллеги используют несколько иной подход для хеш таблиц. Также мы будем говорить про таблицу в ClickHouse. И все эти таблицы используют метод открытой адресации. Что он из себя представляет? Когда второй ключ ложится и попадает в тот же слот, что и первый, мы кладем его в один из следующих слотов в массиве.
Выбор следующего слота зависит от многих факторов. Могут быть линейные пробы, то есть мы выбираем следующий слот. Могут быть квадратичные пробы, тогда выбираем следующий слот с мультипликатором 2 — один, два, четыре, восемь и так далее. Это дает идеальную кеш-локальность, так как в процессоре данные забираются кеш-линиями, и может получиться так, что за один lookup будет всего один fetch из памяти. Минусы этого способа: для него нужна идеальная хеш-функция, которая подходит под ваши данные.
Представим, что мы выбрали не очень хорошую хеш-функцию. Легко предположить, что будут возникать моменты, когда такие кластеры в таком массиве начнут склеиваться между собой, и возникнет ситуация, когда мы начинаем проверять ключи, не относящиеся к ключу, который мы ищем. Еще такой способ плохо подходит для больших объектов, потому что они убьют всю кеш-локальность, а данный способ эффективен как раз за счет своей кеш-локальности. Что тогда делать? Мы сериализуем большие объекты в какое-нибудь место и храним в таблице указатели на них.
Очень важная вещь — ресайз. Для начала нужно определиться, во сколько раз ресайзить. Есть два способа. Первый — ресайзить по степеням двойки. Способ хорош тем, что на на lookup таблицы должно тратиться минимальное время, она должна происходить за наносекунды, если таблица попадает в кеш. Но если вы используете не степень двойки, будет происходить деление, а это очень дорого. При использовании в качестве размера степени двойки можно получить довольно быстрое деление, код перед вами. Также есть более теоретическое обоснование использовать степень, близкую к степени двойки, но простое число. Минус в том, что нужно придумать, как избежать деления. Для этого мы, например, можем использовать какой-нибудь constant switch или библиотеку типа libdivide.
Теперь про load factor. У нас и во всех хеш-таблицах Google, кроме Abseil Hash Map, используется load factor 0,5. Это хороший load factor, его можно использовать в своих таблицах. В Abseil Sale Hash Map используется load factor около 0,9.
Самое интересное — способ размещения ячеек в памяти. Здесь происходит довольно много важных решений, чтобы ваша таблица не тормозила.
Зачем нужен способ размещения в памяти? Как только человек впервые начинает пытаться написать свою open addressing-хеш-таблицу, он сталкивается с такой ситуацией. Представьте: вы пишите код и пытаетесь вставить и обработать ситуацию, когда у вас второй ключ попадает в первый и происходит коллизия. Нужно придумать, что делать дальше.
В первую очередь у нас будет цикл по ячейкам, и нужно решить, пустая ли это ячейка, стоит ли в нее записывать, вдруг эта ячейка удалена. Необходимо поддерживать все эти методы.
Тут есть несколько вариантов, мы поговорим про все из них. Первый вариант — можно попросить пользователя использовать некоторые значение как null key, tombstone. Значение Null key никогда не может попасть в таблицу, его нет в ваших реальных данных, и мы можем по нему идентифицировать, что ячейка пустая.
Такой способ используется в Google Flat Hash Map. Основной минус способа: мы заставляем клиента думать, ему нужно будет найти какой-то ключ, которого у него нет. Иногда найти ключ просто, иногда сложно, но в целом это портит API. На картинке это примерно видно: есть слоты в таблице и некоторые из них — null key, некоторые — tombstone. То есть мы спокойно можем проверить, что данный слот пустой.
Более продвинутый способ используется у нас в ClickHouse. Мы не держим пустые ячейки в хеш-таблице. У нас есть какое-то значение для пустого элемента, и мы его держим отдельно. Перед вставкой или поиском в хеш-таблице мы сначала проверяем, пустое это значение или нет, и обрабатываем его отдельно. Минус в том, что появляется дополнительный branch, но на практике он незаметен и не влияет на наш перфоманс.
Есть и довольно сложный способ, который используется в самой новой хеш-таблице от Google. Чтобы прийти к этому способу, нужно начать с более простых кейсов. Например, мы хотим где-то держать информацию о том, удалена ячейка или нет, пустая она или нет. Если мы попробуем это записать в хеш-таблицу, то будем тратить дополнительную память. Значит, мы попробуем держать это где-нибудь в другом месте, например в какой-нибудь метадате.
Но так как у нас получается, что нужно всего два бита, то тратить их на эту информацию дорого. Мы можем попробовать целый байт, но что записать в остальные биты? В таблице Google сделано так — верхние 53 бита хеш-функции используются для поиска ячеек с метаданными, и в метаданных лежат нижние биты хеш-функций.
Зачем это может пригодиться? Мы помещаем эти данные в регистры и делаем быструю проверку, стоит ли нам смотреть связанные с ними ячейки — например, используя AVX-инструкции.
Если вы решите посмотреть, какая таблица самая лучшая, то в интернете каждый второй написал свою самую быструю хеш-таблицу. Если начинать копать глубже, то это не так. Во многих бенчмарках не рассматриваются довольно важные вещи, не используются какие-либо конкретные сценарии и непонятно, быстрая это таблица или нет.
Каковы основные проблемы с бенчмарками? Их часто делают не на реальных данных, а на случайных числах. Распределение случайных чисел не соответствует реальным данным. Также довольно часто не рассматривается какой-нибудь определенный сценарий. Так же часто не показывают код бенчмарков, то есть бенчмарки есть, различного рода графики есть, можно всё посмотреть, но код не найти, то есть повторить данный бенчмарк невозможно.
Как надо делать бенчмарки? Их надо делать на реальных данных и на реальных сценариях. В ClickHouse реальный сценарий — агрегация данных, а сами данные мы берем из Яндекс.Метрики, скачать их можно у нас на сайте.
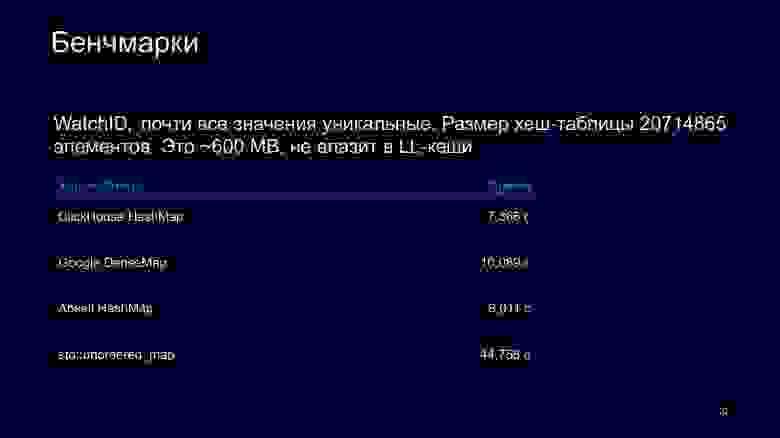
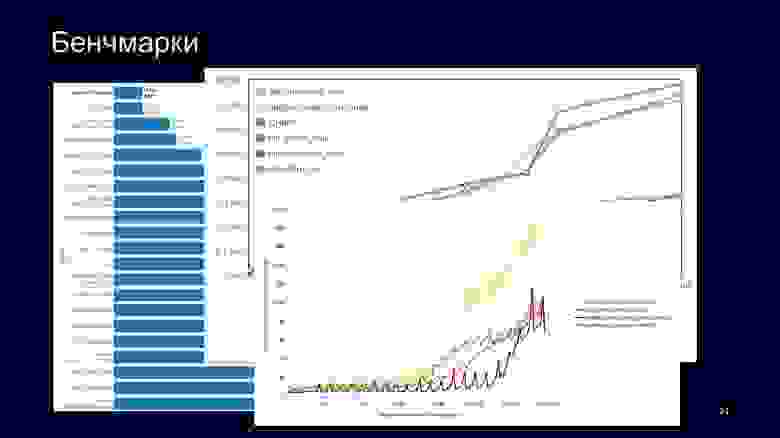
Теперь посмотрим бенчмарки и попробуем проанализировать, как различные решения в дизайне влияют на хеш-таблицы. Есть колонка очереди, это очень много ключей, в данном случае около двух миллионов. Они не помещаются в LL-кеши, занимают около 600 МБ. Значит, мы будем ходить в main memory.
Если посмотрим бенчмарки, увидим, что ClickHouse и таблицы Google намного впереди std::unordered_map. Почему? Потому что, как я уже говорил, std::unordered_map не кеш-локален, конкретно эти данные не помещаются в LL-кеше.
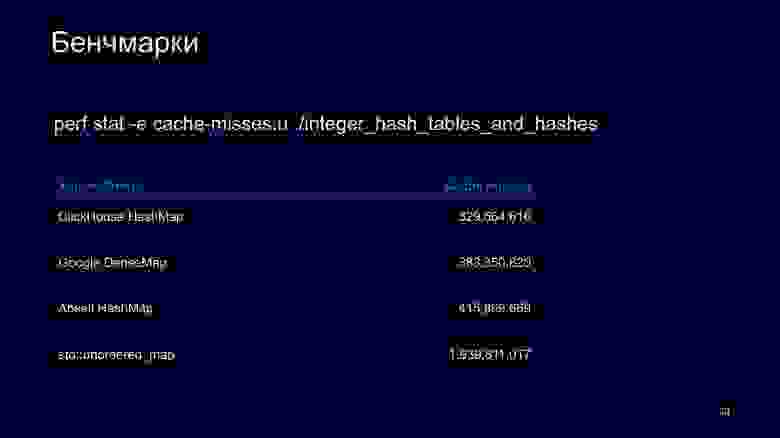
Если мы решим посмотреть это через perf stat, чтобы убедиться в нашем предположении, то увидим, что у std::unordered_map намного больше кеш miss, из-за этого она тормозит.

Источник
Можно также обратиться к числам, которые должны знать все программисты, и увидеть, что поход в main memory занимает намного больше по времени, чем поход в L1- или L2-кеши. Можно предположить: чтобы таблица работала на максимальной скорости, она должны быть кеш-локальна.
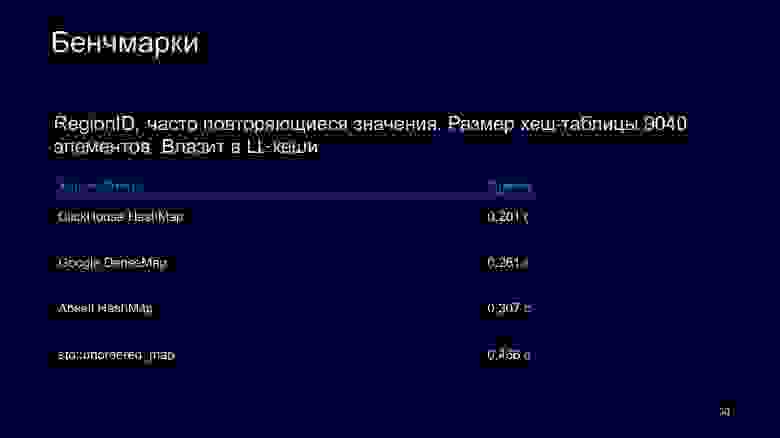
Возьмем немного другой бенчмарк, в котором все данные попадают в кеши. В данном случае мы видим, что std::unordered_map уже не тормозит так сильно.
Мы пока поговорили скорее про алгоритмический дизайн решения. Но чтобы все это классно работало, нужно придумать красивую С++-обертку.
Мы поговорили про различного рода интерфейсы. Наша таблица представляет собой policy base-дизайн, то есть каждый интерфейс — отдельная часть хеш-таблицы. Основные интерфейсы: хеш-функция, Allocator, ячейка, которая является в нашей таблице важным элементом, Grower, то есть интерфейс для политики ресайза, и сама хеш-таблица, которая объединит все эти компоненты вместе.

Начнем с хеша. Это такой же интерфейс, как и std::hash, введенный в С++11, ничего нового.
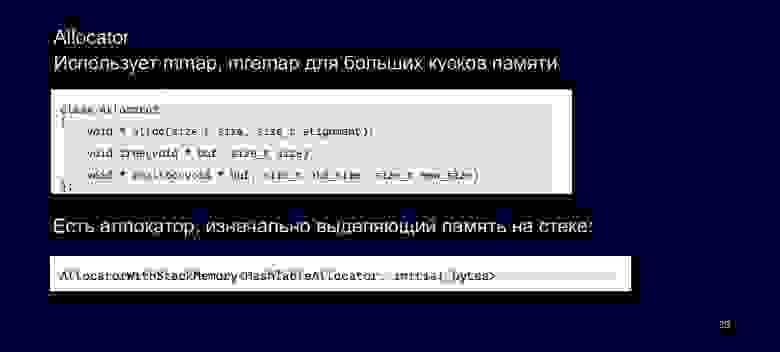
Allocator — немного измененный интерфейс стандартного Allocator, так как наша версия поддерживает realloc. Зачем нам нужен realloc? На Linux для больших таблиц мы используем mmap и mremap, для этого нам нужно предоставить в нашем интерфейсе метод realloc.
Мы также можем задействовать Allocator, который аллоцирует всю память на стеке, когда используем для него кастомную политику.

Ячейка — полноценный элемент нашей хеш-таблицы, можно в нее записать хеш, получить из нее хеш, проверить, пустая ли она. Также ячейка сама может прокинуть информацию в таблицу, то есть она понимает, что находится внутри таблицы, параметризуется ее состоянием.

Про политику ресайза. Эти интерфейсы как раз есть в нашей политике ресайза — получение места в хеш-таблице, движение к следующему элементу, проверка, приведет ли вставка следующего элемента к переполнению таблицы, и сам ресайз. Определим их в коде.

Хеш-таблица объединит все эти интерфейсы в себя и отнаследуется от них. Почему мы в данном случае используем наследование? Потому что хотим, чтобы все было zero-cost, и используем zero based optimization. Если у вас, например, базовый класс не является классом с состоянием, вы не потратите дополнительной памяти на его хранение.

Например, как мы используем zero value storage? Как я говорил, в ClickHouse нулевое значение вырабатывается отдельно и кладется в специальный zero value storage, но это не всегда нужно. Предположим, он нам не нужен, в таком случае zero value storage — специализация, которая ничего не делает, компилятор убирает лишний код, и ничего не тормозит.
Что нам дает возможность передавать кастомную политику ресайза? Кастомная политика ресайза с фиксированным размером и без разрешения хеш-коллизий представляет из себя некое подобие кеша. Используя политику ресайза с шагом, не равным единице, мы можем получить, например, квадратичные пробы, что может быть удобно для проверки различных бенчмарков.

Возможность хранить состояние в ячейке — это когда мы можем сохранять в ячейке некоторую полезную информацию, например значение хеш-функции. Для чего это может быть полезно? Для случая, если мы не хотим пересчитывать хеш-функцию в случае строковых хеш-таблиц.
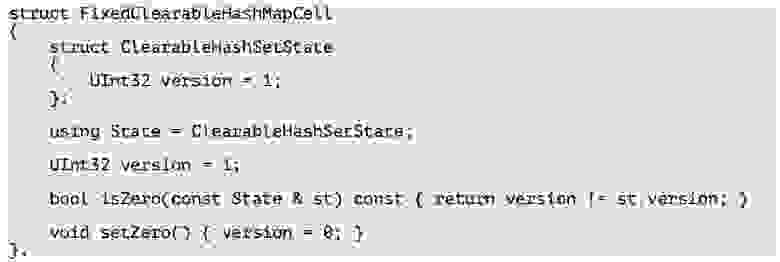
Также мы можем сделать быстро очищаемую хеш-таблицу. Она полезна в том случае, когда у нас есть огромная таблица, мы ее уже наполнили данными и сейчас хотим ее переиспользовать. Если мы попытаемся удалить все ячейки в таблице, то нам нужно будет пробежаться по ней, мы словим множество кеш-промахов и все будет тормозить.
Но мы можем удалить все элементы в таблице, не проходя по ней. В данном случае мы используем в качестве состояния версию таблицы — храним версию и в ячейке, и в самой таблице. В случае проверки, пустая ли это ячейка, мы всего лишь сравниваем версию ячейки и таблицы. Если нам нужно сделать быстрое удаление, мы увеличиваем версию таблицы на единицу.
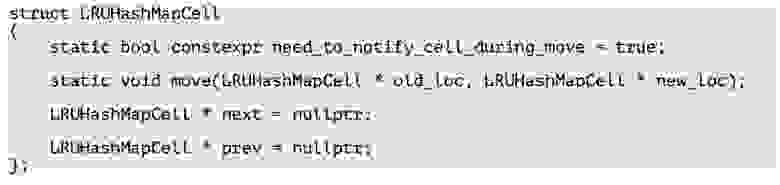
Еще один интересный трюк — LRU Cache. Это реализация политики вытеснения LRU. Обычно он реализуется так: есть список и хеш-таблица, в которой значения — это итератор на данный список. Когда мы обращаемся к определенному ключу, то перекладываем значение в списке — например, в конец списка. Когда список становится полным, мы удаляем элемент из начала списка и в нем будут находиться самые актуальные элементы.
Как я уже сказал, реализация со списком и таблицей не оптимальна, поскольку мы используем два контейнера. В случае с ClickHouse мы придумали, как сделать это в одном контейнере. В ячейке хеш-таблицы мы храним указатель на следующий и предыдущий элемент, и получается, что мы сделали двухсвязный список прямо внутри таблицы.
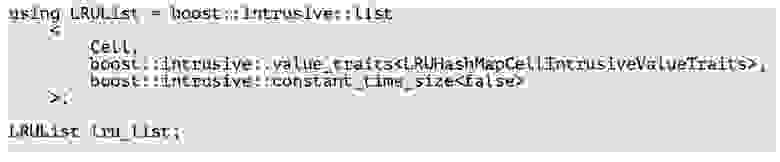
Как мы это сделали? Храним два указателя и воспользовались библиотекой Boost. Весь код библиотеки Boost не прошел цензуру и не поместился на слайде, поэтому я покажу только самое важное. Мы делаем интрузивный список и используем его в качестве списка. Того, что мы объявили указатели на следующий и предыдущий элемент в ячейке, нам достаточно для создания интрузивного списка поверх ячеек.

Про специализированные хеш-таблицы. У нас есть несколько специализированных таблиц под различные сценарии. Например, small table — это хеш-таблица, которая представляет собой массив. Чем она может быть полезна? Она помещается в L1-кеш и представляет собой интерфейс таблицы, если нам нужно реализовать какой-нибудь простенький алгоритм.

Источник
Теперь у нас есть и более интересная хеш-таблица — строковая. Ее нам законтрибьютил аспирант из Китая, это четыре хеш-таблицы под строки разной длины, для которых мы используем разные хеш-функции.

Еще одна очень интересная хеш-таблица — two level, она представляет из себя 256 хеш-таблиц. Зачем такое может быть нужно, если вы не любитель хеш-таблиц? Когда мы, например, делаем операцию GROUP BY, то хотим делать ее во множество потоков. Следовательно, нам нужно заполнять таблицы и затем объединять их. Мы могли бы воспользоваться таблицами lock free, но у нас в команде никто не любит lock free, так что используем two level.
Как это работает? Мы создаем two level в каждом потоке. Например, у нас четыре потока — получается матрица из 256 колонок (таблиц) и четырех строк (потоков). Мы вставляем данные в одну из этих таблиц. Например — делаем распределение по такой формуле, как показано на слайде. Затем, когда нам нужно объединить таблицы, используем минимальную синхронизацию и объединяем их по колонкам. В итоге здесь ничего не тормозит.
Итак, мы написали свой довольно гибкий фреймворк для реализации хеш-таблиц. Из него можно получать структуры под разные сценарии.
Хочу признаться: я очень люблю хеш-таблицы. Тому, у кого получится улучшить наш бенчмарк — например, сделать хеш-таблицу, которая быстрее нашей, — я подарю худи «ClickHouse не тормозит», которой нет даже у меня.
— Для начала мы обсудим, зачем нужны хеш-таблицы, где их можно использовать в базах данных и как сделать их оптимальными. Затем посмотрим бенчмарки различных хеш-таблиц в интернете и разбёремся, как делать их правильно. В конце посмотрим на C++-обертку над идеальной хеш-таблицей в ClickHouse.
Все знают, что ClickHouse не тормозит, но не все знают, почему. Самая важная часть в ClickHouse — это GROUP BY. Чтобы делать GROUP BY оптимально, мы складываем все данные в хеш-таблицу. У нас около 40 различных оптимизаций операций GROUP BY, но каждая из них под собой так или иначе использует высокооптимизированную хеш-таблицу.
Если сказать, что у нас одна хеш-таблица, это будет не совсем верно. У нас их очень много, мы написали настоящий фреймворк для хеш-таблиц. Также хеш-таблицы у нас используются в JOIN и в операции SELECT DISTINCT.

Хеш-таблица — это структура данных, которая обеспечивает константные операции в среднем: insert, lookup и удаление, если оно вам нужно. В наших сценариях агрегации данных GROUP BY удаление нас не очень интересует.

Посмотрим на картинку. Все знают, как хеш-таблица устроена, например, из курса университета. Мы берем некий ключ, который хотим положить, берем хеш-функцию, хешируем этот ключ, выбираем в массиве какой-нибудь слот по остатку от деления и кладем ключ в этот слот.
Дизайн хеш-таблицы
Таблица состоит из очень многих маленьких компонентов, это очень сложная структура данных. Каждый из этих компонентов очень важен, ошибка в любом из них сделает вашу таблицу неэффективной, она будет тормозить и не приносить вам zero-cost. Хеш-таблица состоит из хеш-функции, способа разрешения коллизий, политики ресайза и разных возможностей размещения ее ячеек в памяти.
Начнем с выбора хеш-функции. Это очень важный элемент, и многие уже на нем допускают ошибку. Кажется, как можно допустить ошибку с выбором, ведь так просто воспользоваться какой-либо хеш-функцией. Но я приведу основные проблемы и грабли.
В первую очередь, для целочисленных типов довольно часто многие используют хеш-функцию identity. Это неправильно, так как распределение реальных данных не такое и у вас будет множество коллизий. Еще не стоит использовать хеш-функции для строк, для чисел, так как они будут тормозить, компилятор не производит inline-подстановку сложных хеш-функций, например функций типа City Hash. Также не стоит использовать различные криптографические хеш-функции, если вас не атакуют злоумышленники. Предположим, пропускная способность вычисления функции Sip Hash — 1 ГБ/с, а функции City Hash — около 10 ГБ/с. Значит, пропускная способность вашей таблицы будет ограничена сверху 1 ГБ/с.
Кроме того, не стоит использовать устаревшие хеш-функции, например FNV1a, потому что они медленные и имеют плохое распределение относительно конкурентов. FNV1a используется в стандартной библиотеке GCC. Это устаревшая хеш-функция, на GitHub есть репозиторий SMHasher с тестами разных хеш-функций. Там видно, что эта хеш-функция не проходит никакие серьезные тесты.
Теперь я расскажу, какие хеш-функции используются в ClickHouse. По умолчанию используются плохие хеш-функции, они дают плохое распределение, но хороши для хеш-таблиц. Например, для целочисленных типов мы используем CRC-32C, эта хеш-функция занимает очень мало времени процессора, выполняется очень быстро и представляет собой две инструкции. Для строк мы используем свою кастомную хеш-функцию, построенную на CRC-32C. Если не использовать ее, можно использовать что-нибудь стандартное — City Hash.

Поговорим про разрешения коллизий. В любой хеш-таблице по парадоксу дня рождения будет возникать ситуация, что один и тот же ключ попадает в один и тот же слот. Предположим, мы вставили ключ К1 и он попал в третий слот таблицы. Теперь мы пытаемся вставлять ключ К2, и получилось, что по остатку от деления он попадает в тот же слот. Нужно придумать, что с ним делать дальше. Есть несколько способов разрешения такой ситуации.
Первый способ — использовать chaining. То есть ячейка таблицы будет использовать список или массив, и мы будем класть следующий ключ в эту же ячейку, используя нижележащую структуру данных.
Есть другой способ — использовать метод открытой адресации. В данном случае мы кладем ключ в один из следующих слотов таблицы.
Есть и более сложные способы, например Cuckoo hashing или two way hashing. У них есть проблема: обычно они сложны в реализации, требуют дополнительных фетчей из памяти и обычно тормозят. К примеру, даже много кода на hot path очень сильно замедляет lookup в хеш-таблице.

Начнем с самого простого метода — метода цепочек. Мы пытаемся положить второй ключ в ячейку с первым ключом. Под ним мы будем использовать список, кладем его в этот список, а затем при поиске будем проверять каждый ключ в списке.
Такой способ используется в std::unordered_map. Почему этот способ не эффективен? Он не кеш-локален, будет тормозить. Его эффективность в том, что он будет работать во всех случаях, не сильно привередлив к хеш-функции, будет работать даже с высоким loot factor. Но, к сожалению, он будет очень сильно нагружать аллокатор, так как даже вызов какой-либо функции на hot path lookup в хеш-таблице — это очень дорого.
Во всех современных хеш-таблицах используется метод открытой адресации.

Сегодня в докладе я буду говорить про три хеш-таблицы, на которые стоит обратить внимание. Две из них — это Google Flat Hash Map и Google Abseil Hash Map. Abseil — один из новый фреймворков Google, в котором коллеги используют несколько иной подход для хеш таблиц. Также мы будем говорить про таблицу в ClickHouse. И все эти таблицы используют метод открытой адресации. Что он из себя представляет? Когда второй ключ ложится и попадает в тот же слот, что и первый, мы кладем его в один из следующих слотов в массиве.
Выбор следующего слота зависит от многих факторов. Могут быть линейные пробы, то есть мы выбираем следующий слот. Могут быть квадратичные пробы, тогда выбираем следующий слот с мультипликатором 2 — один, два, четыре, восемь и так далее. Это дает идеальную кеш-локальность, так как в процессоре данные забираются кеш-линиями, и может получиться так, что за один lookup будет всего один fetch из памяти. Минусы этого способа: для него нужна идеальная хеш-функция, которая подходит под ваши данные.
Представим, что мы выбрали не очень хорошую хеш-функцию. Легко предположить, что будут возникать моменты, когда такие кластеры в таком массиве начнут склеиваться между собой, и возникнет ситуация, когда мы начинаем проверять ключи, не относящиеся к ключу, который мы ищем. Еще такой способ плохо подходит для больших объектов, потому что они убьют всю кеш-локальность, а данный способ эффективен как раз за счет своей кеш-локальности. Что тогда делать? Мы сериализуем большие объекты в какое-нибудь место и храним в таблице указатели на них.
Очень важная вещь — ресайз. Для начала нужно определиться, во сколько раз ресайзить. Есть два способа. Первый — ресайзить по степеням двойки. Способ хорош тем, что на на lookup таблицы должно тратиться минимальное время, она должна происходить за наносекунды, если таблица попадает в кеш. Но если вы используете не степень двойки, будет происходить деление, а это очень дорого. При использовании в качестве размера степени двойки можно получить довольно быстрое деление, код перед вами. Также есть более теоретическое обоснование использовать степень, близкую к степени двойки, но простое число. Минус в том, что нужно придумать, как избежать деления. Для этого мы, например, можем использовать какой-нибудь constant switch или библиотеку типа libdivide.
Теперь про load factor. У нас и во всех хеш-таблицах Google, кроме Abseil Hash Map, используется load factor 0,5. Это хороший load factor, его можно использовать в своих таблицах. В Abseil Sale Hash Map используется load factor около 0,9.

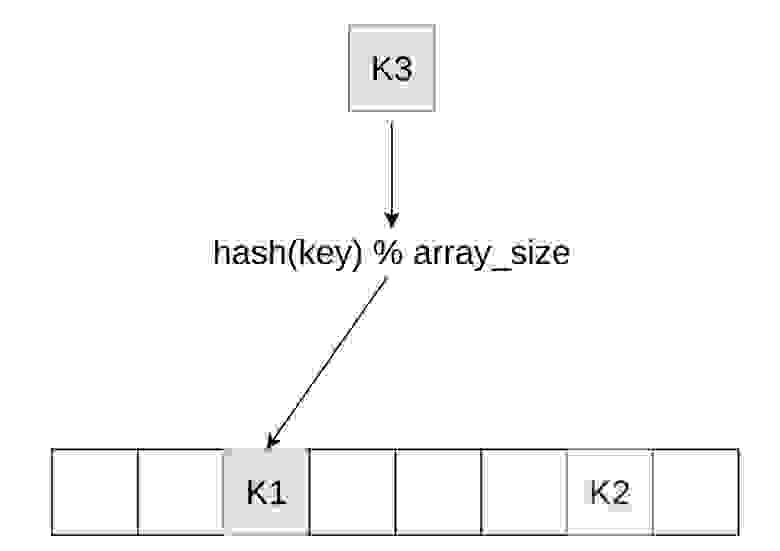
Самое интересное — способ размещения ячеек в памяти. Здесь происходит довольно много важных решений, чтобы ваша таблица не тормозила.
Зачем нужен способ размещения в памяти? Как только человек впервые начинает пытаться написать свою open addressing-хеш-таблицу, он сталкивается с такой ситуацией. Представьте: вы пишите код и пытаетесь вставить и обработать ситуацию, когда у вас второй ключ попадает в первый и происходит коллизия. Нужно придумать, что делать дальше.
В первую очередь у нас будет цикл по ячейкам, и нужно решить, пустая ли это ячейка, стоит ли в нее записывать, вдруг эта ячейка удалена. Необходимо поддерживать все эти методы.

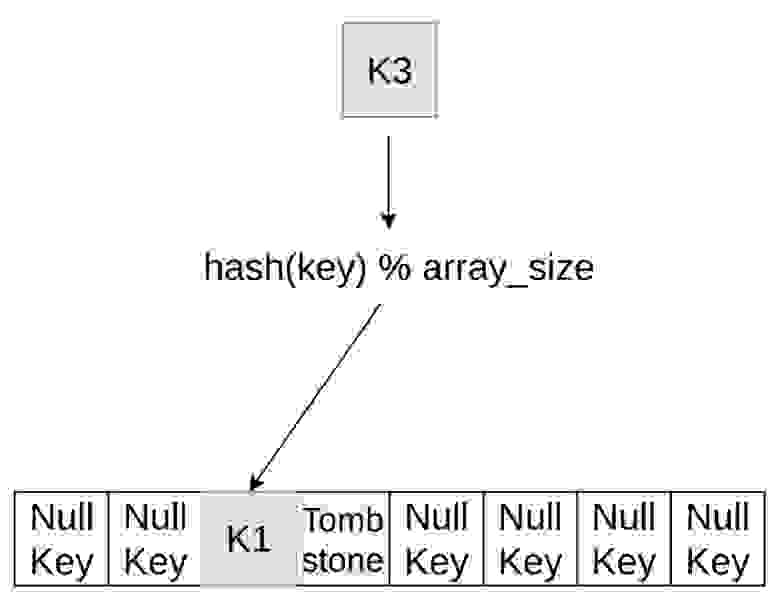
Тут есть несколько вариантов, мы поговорим про все из них. Первый вариант — можно попросить пользователя использовать некоторые значение как null key, tombstone. Значение Null key никогда не может попасть в таблицу, его нет в ваших реальных данных, и мы можем по нему идентифицировать, что ячейка пустая.
Такой способ используется в Google Flat Hash Map. Основной минус способа: мы заставляем клиента думать, ему нужно будет найти какой-то ключ, которого у него нет. Иногда найти ключ просто, иногда сложно, но в целом это портит API. На картинке это примерно видно: есть слоты в таблице и некоторые из них — null key, некоторые — tombstone. То есть мы спокойно можем проверить, что данный слот пустой.

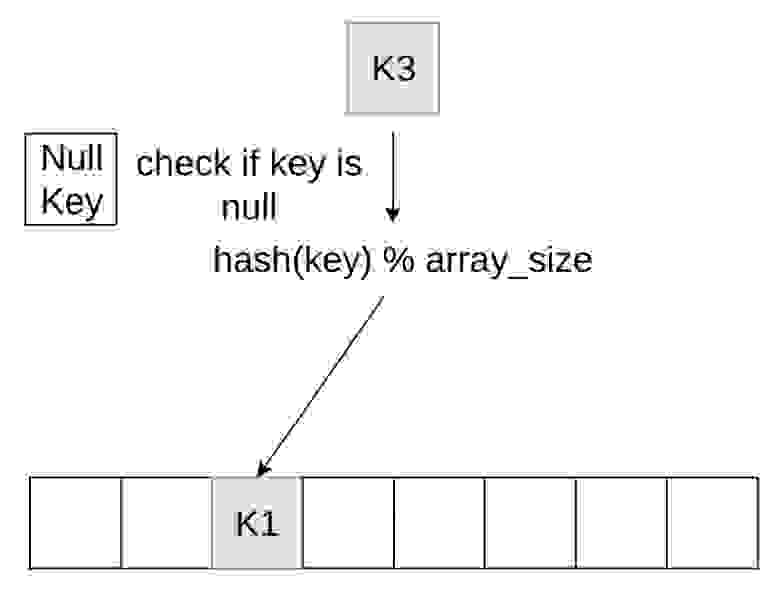
Более продвинутый способ используется у нас в ClickHouse. Мы не держим пустые ячейки в хеш-таблице. У нас есть какое-то значение для пустого элемента, и мы его держим отдельно. Перед вставкой или поиском в хеш-таблице мы сначала проверяем, пустое это значение или нет, и обрабатываем его отдельно. Минус в том, что появляется дополнительный branch, но на практике он незаметен и не влияет на наш перфоманс.

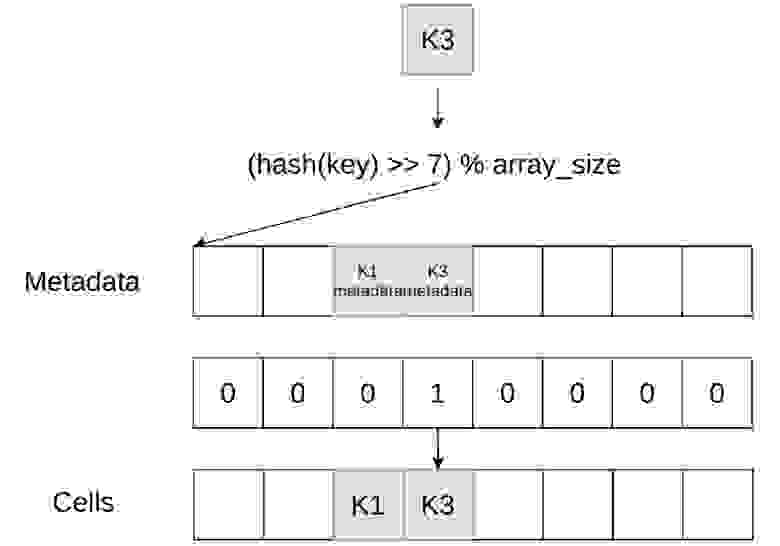
Есть и довольно сложный способ, который используется в самой новой хеш-таблице от Google. Чтобы прийти к этому способу, нужно начать с более простых кейсов. Например, мы хотим где-то держать информацию о том, удалена ячейка или нет, пустая она или нет. Если мы попробуем это записать в хеш-таблицу, то будем тратить дополнительную память. Значит, мы попробуем держать это где-нибудь в другом месте, например в какой-нибудь метадате.
Но так как у нас получается, что нужно всего два бита, то тратить их на эту информацию дорого. Мы можем попробовать целый байт, но что записать в остальные биты? В таблице Google сделано так — верхние 53 бита хеш-функции используются для поиска ячеек с метаданными, и в метаданных лежат нижние биты хеш-функций.
Зачем это может пригодиться? Мы помещаем эти данные в регистры и делаем быструю проверку, стоит ли нам смотреть связанные с ними ячейки — например, используя AVX-инструкции.
Бенчмарки

Если вы решите посмотреть, какая таблица самая лучшая, то в интернете каждый второй написал свою самую быструю хеш-таблицу. Если начинать копать глубже, то это не так. Во многих бенчмарках не рассматриваются довольно важные вещи, не используются какие-либо конкретные сценарии и непонятно, быстрая это таблица или нет.
Каковы основные проблемы с бенчмарками? Их часто делают не на реальных данных, а на случайных числах. Распределение случайных чисел не соответствует реальным данным. Также довольно часто не рассматривается какой-нибудь определенный сценарий. Так же часто не показывают код бенчмарков, то есть бенчмарки есть, различного рода графики есть, можно всё посмотреть, но код не найти, то есть повторить данный бенчмарк невозможно.
Как надо делать бенчмарки? Их надо делать на реальных данных и на реальных сценариях. В ClickHouse реальный сценарий — агрегация данных, а сами данные мы берем из Яндекс.Метрики, скачать их можно у нас на сайте.

Теперь посмотрим бенчмарки и попробуем проанализировать, как различные решения в дизайне влияют на хеш-таблицы. Есть колонка очереди, это очень много ключей, в данном случае около двух миллионов. Они не помещаются в LL-кеши, занимают около 600 МБ. Значит, мы будем ходить в main memory.
Если посмотрим бенчмарки, увидим, что ClickHouse и таблицы Google намного впереди std::unordered_map. Почему? Потому что, как я уже говорил, std::unordered_map не кеш-локален, конкретно эти данные не помещаются в LL-кеше.

Если мы решим посмотреть это через perf stat, чтобы убедиться в нашем предположении, то увидим, что у std::unordered_map намного больше кеш miss, из-за этого она тормозит.

Источник
Можно также обратиться к числам, которые должны знать все программисты, и увидеть, что поход в main memory занимает намного больше по времени, чем поход в L1- или L2-кеши. Можно предположить: чтобы таблица работала на максимальной скорости, она должны быть кеш-локальна.

Возьмем немного другой бенчмарк, в котором все данные попадают в кеши. В данном случае мы видим, что std::unordered_map уже не тормозит так сильно.
С++-дизайн хеш-таблицы
Мы пока поговорили скорее про алгоритмический дизайн решения. Но чтобы все это классно работало, нужно придумать красивую С++-обертку.
Мы поговорили про различного рода интерфейсы. Наша таблица представляет собой policy base-дизайн, то есть каждый интерфейс — отдельная часть хеш-таблицы. Основные интерфейсы: хеш-функция, Allocator, ячейка, которая является в нашей таблице важным элементом, Grower, то есть интерфейс для политики ресайза, и сама хеш-таблица, которая объединит все эти компоненты вместе.

Начнем с хеша. Это такой же интерфейс, как и std::hash, введенный в С++11, ничего нового.

Allocator — немного измененный интерфейс стандартного Allocator, так как наша версия поддерживает realloc. Зачем нам нужен realloc? На Linux для больших таблиц мы используем mmap и mremap, для этого нам нужно предоставить в нашем интерфейсе метод realloc.
Мы также можем задействовать Allocator, который аллоцирует всю память на стеке, когда используем для него кастомную политику.

Ячейка — полноценный элемент нашей хеш-таблицы, можно в нее записать хеш, получить из нее хеш, проверить, пустая ли она. Также ячейка сама может прокинуть информацию в таблицу, то есть она понимает, что находится внутри таблицы, параметризуется ее состоянием.

Про политику ресайза. Эти интерфейсы как раз есть в нашей политике ресайза — получение места в хеш-таблице, движение к следующему элементу, проверка, приведет ли вставка следующего элемента к переполнению таблицы, и сам ресайз. Определим их в коде.

Хеш-таблица объединит все эти интерфейсы в себя и отнаследуется от них. Почему мы в данном случае используем наследование? Потому что хотим, чтобы все было zero-cost, и используем zero based optimization. Если у вас, например, базовый класс не является классом с состоянием, вы не потратите дополнительной памяти на его хранение.

Например, как мы используем zero value storage? Как я говорил, в ClickHouse нулевое значение вырабатывается отдельно и кладется в специальный zero value storage, но это не всегда нужно. Предположим, он нам не нужен, в таком случае zero value storage — специализация, которая ничего не делает, компилятор убирает лишний код, и ничего не тормозит.
Что нам дает возможность передавать кастомную политику ресайза? Кастомная политика ресайза с фиксированным размером и без разрешения хеш-коллизий представляет из себя некое подобие кеша. Используя политику ресайза с шагом, не равным единице, мы можем получить, например, квадратичные пробы, что может быть удобно для проверки различных бенчмарков.

Возможность хранить состояние в ячейке — это когда мы можем сохранять в ячейке некоторую полезную информацию, например значение хеш-функции. Для чего это может быть полезно? Для случая, если мы не хотим пересчитывать хеш-функцию в случае строковых хеш-таблиц.

Также мы можем сделать быстро очищаемую хеш-таблицу. Она полезна в том случае, когда у нас есть огромная таблица, мы ее уже наполнили данными и сейчас хотим ее переиспользовать. Если мы попытаемся удалить все ячейки в таблице, то нам нужно будет пробежаться по ней, мы словим множество кеш-промахов и все будет тормозить.
Но мы можем удалить все элементы в таблице, не проходя по ней. В данном случае мы используем в качестве состояния версию таблицы — храним версию и в ячейке, и в самой таблице. В случае проверки, пустая ли это ячейка, мы всего лишь сравниваем версию ячейки и таблицы. Если нам нужно сделать быстрое удаление, мы увеличиваем версию таблицы на единицу.

Еще один интересный трюк — LRU Cache. Это реализация политики вытеснения LRU. Обычно он реализуется так: есть список и хеш-таблица, в которой значения — это итератор на данный список. Когда мы обращаемся к определенному ключу, то перекладываем значение в списке — например, в конец списка. Когда список становится полным, мы удаляем элемент из начала списка и в нем будут находиться самые актуальные элементы.
Как я уже сказал, реализация со списком и таблицей не оптимальна, поскольку мы используем два контейнера. В случае с ClickHouse мы придумали, как сделать это в одном контейнере. В ячейке хеш-таблицы мы храним указатель на следующий и предыдущий элемент, и получается, что мы сделали двухсвязный список прямо внутри таблицы.

Как мы это сделали? Храним два указателя и воспользовались библиотекой Boost. Весь код библиотеки Boost не прошел цензуру и не поместился на слайде, поэтому я покажу только самое важное. Мы делаем интрузивный список и используем его в качестве списка. Того, что мы объявили указатели на следующий и предыдущий элемент в ячейке, нам достаточно для создания интрузивного списка поверх ячеек.

Про специализированные хеш-таблицы. У нас есть несколько специализированных таблиц под различные сценарии. Например, small table — это хеш-таблица, которая представляет собой массив. Чем она может быть полезна? Она помещается в L1-кеш и представляет собой интерфейс таблицы, если нам нужно реализовать какой-нибудь простенький алгоритм.

Источник
Теперь у нас есть и более интересная хеш-таблица — строковая. Ее нам законтрибьютил аспирант из Китая, это четыре хеш-таблицы под строки разной длины, для которых мы используем разные хеш-функции.

Еще одна очень интересная хеш-таблица — two level, она представляет из себя 256 хеш-таблиц. Зачем такое может быть нужно, если вы не любитель хеш-таблиц? Когда мы, например, делаем операцию GROUP BY, то хотим делать ее во множество потоков. Следовательно, нам нужно заполнять таблицы и затем объединять их. Мы могли бы воспользоваться таблицами lock free, но у нас в команде никто не любит lock free, так что используем two level.
Как это работает? Мы создаем two level в каждом потоке. Например, у нас четыре потока — получается матрица из 256 колонок (таблиц) и четырех строк (потоков). Мы вставляем данные в одну из этих таблиц. Например — делаем распределение по такой формуле, как показано на слайде. Затем, когда нам нужно объединить таблицы, используем минимальную синхронизацию и объединяем их по колонкам. В итоге здесь ничего не тормозит.
Итак, мы написали свой довольно гибкий фреймворк для реализации хеш-таблиц. Из него можно получать структуры под разные сценарии.
Хочу признаться: я очень люблю хеш-таблицы. Тому, у кого получится улучшить наш бенчмарк — например, сделать хеш-таблицу, которая быстрее нашей, — я подарю худи «ClickHouse не тормозит», которой нет даже у меня.
