
Сегодня мы выложили в опенсорс систему управления базами данных YDB — плод многолетнего опыта Яндекса в разработке систем хранения и обработки данных. Исходный код, документация, SDK и все инструменты для работы с базой опубликованы на GitHub под лицензией Apache 2.0. Развернуть базу можно как на собственных, так и на сторонних серверах — в том числе в любых облачных сервисах.

YDB решает задачи в одной из самых критичных областей — позволяет создавать интерактивные приложения, которые можно быстро масштабировать по нагрузке и по объёму данных. Мы разрабатывали её, исходя из ключевых требований к сервисам Яндекса. Во-первых, это катастрофоустойчивость, то есть возможность продолжить работу без деградации при отключении одного из дата-центров. Во-вторых, это масштабируемость на десятки тысяч серверов на чтение и на запись. В-третьих, это строгая консистентность данных.
В посте я расскажу об истории развития технологий баз данных, о том, зачем использовать YDB, как её применяют текущие пользователи и какие плюсы для всех несёт выход в опенсорс. А во второй половине поста поговорим о разных вариантах развёртывания.
В нашей компании YDB используется уже больше пяти лет. На мультитенантных кластерах развёрнуты базы с очень разными нагрузками и паттернами доступа к данным. На практике мы встречаемся с многократным ростом баз данных, ростом объёмов данных с единиц гигабайт до сотен терабайт и ростом нагрузок с тысяч до миллионов RPS. При этом решение задач масштабируемости и отказоустойчивости автоматически осуществляет база, снимая их с разработчиков прикладного кода. Но YDB распространена не только в проектах с высокой нагрузкой. Команды разработки Яндекса сами определяют свой стек в зависимости от задач, аудитории и другой специфики, и многие выбирают YDB за отказоустойчивость, даже если текущие нагрузки невелики. Одна из причин в том, что в случае внезапного роста нагрузок разработчикам будет достаточно добавить ресурсы, не внося изменения в код приложения и не прикладывая усилия к ручному перешардированию базы. Проекты в YDB размещают команды Алисы, Такси, Метрики и других сервисов — сейчас в системе почти 500 проектов.
Широкое распространение YDB внутри Яндекса, популярность в качестве сервиса Яндекс Облака и запросы пользователей cтали для нас хорошим стимулом раскрыть исходный код и сделать базу доступной для свободного использования.
За два последних десятилетия непрерывно растёт использование интернета, в последние годы он начал прочно входить в бытовую сферу. Часы, очки, лампочки, пылесосы — практически все устройства подключены к интернету или подключатся в скором времени. Всё это ведёт к непрерывному росту объёмов хранимых данных и нагрузок, которые БД обрабатывают.
С начала 2000-х вместе с бурным ростом интернета выросла популярность опенсорсных СУБД для OLTP-нагрузок — например, MySQL и PostgreSQL.
Без них или их аналогов сложно представить себе нынешние темпы развития интернета. Даже небольшие стартапы получили возможность работать с возрастающими нагрузками на бесплатных БД. Конечно, существовали тяжёлые коммерческие решения, которые позволяли масштабироваться вертикально, но они были доступны только большим компаниям с соответствующими бюджетами.
К середине 2000-х стали популярны разные виды логического шардирования БД — когда базу шардируют на несколько узлов, исходя из бизнес-логики приложения и его сущностей. Промежуточный слой между приложением и базой или само приложение принимает решение, на каком из узлов БД находятся данные. Но этот распространённый подход приводит к усложнению логики пользовательского приложения и значительно усложняет поддержку множества кластеров. Дополнительные сложности возникают при необходимости выполнить запрос, результат которого выдаёт консистентный результат объединения данных из разных шардов. Эту проблему можно решить за счёт отгрузки данных в отдельную систему или дополнительного усложнения логики приложения, но каждый такой дополнительный шаг только усложняет обслуживаемость системы и делает её менее технологичной. В то же время остаются открытыми такие вопросы, как перешардирование данных при росте нагрузки на конкретный шард. Сложно развить изначально выбранный подход к шардированию при изменившихся бизнес-требованиях к приложению. Нагрузки продолжают расти, а критичность отказов возрастает.
В конце 2000-х набирают популярность NoSQL-решения. Во главе угла становятся проблемы масштабируемости и отказоустойчивовости, в жертву приносится диалект SQL и функциональность join. Приемлемой считается eventual consistency, то есть консистентность в конечном итоге: рано или поздно все реплики во всех зонах доступности или регионах получат консистентный набор данных. Растёт популярность key-value-хранилищ (Redis, AWS DynamoDB), column-family (Cassandra, Hbase) и документных БД (MongoDB, Couchbase).
Мы шли тем же путем, и история развития OLTP СУБД в Яндексе повторяет историю развития операционных БД. Предшественником YDB была СУБД NoSQL (KV), которую мы разрабатывали с 2008 года.
Отсутствие поддержки ACID-транзакций приводит к необходимости самостоятельно их эмулировать. Возрастает сложность прикладного кода, и каждый разработчик фактически вынужден дорабатывать на стороне этого кода функциональность базы — что, во-первых очень сложно, а во-вторых, на большом количестве проектов требует множества костылей и велосипедов в каждом проекте.
Проблема оставалась актуальной. В начале 2010-х появляется новый термин — NewSQL. Про него рассказывают Майкл Стоунбрейкер и Энди Павло, описывая новые требования к OLTP СУБД (точнее, ожидания от такой базы).
NewSQL-базы должны обладать масштабируемостью и отказоустойчивовостью, свойственной NoSQL-системам, но при этом предоставлять ACID-гарантии транзакций и SQL-диалект. Чуть позже термин NewSQL трансформировался — масштабируемые, отказоустойчивые БД с поддержкой SQL и строгой консистентностью стали называть Distributed SQL Databases. Вдохновившись идеей NewSQL, в 2012 году мы сделали первый коммит в YDB.
Рынок СУБД развивается давно, на нём представлено много известных и зрелых продуктов. Давайте разберём, какие преимущества может дать YDB в сравнении с другими базами.
Один из вариантов масштабирования в реляционных базах — ручное шардирование. То есть при разворачивании нужно настроить несколько экземпляров базы и решить, к какому экземпляру обращаться в вашем приложении. Если вам нужен одновременный доступ к данным из нескольких экземпляров БД, вам придется самостоятельно заниматься организацией распределённых транзакций. YDB масштабируется на чтение и запись «из коробки», для этого достаточно добавить больше оборудования в кластер. На практике мы работаем с базами размером в сотни терабайт под нагрузкой в миллионы RPS.
NoSQL-базы очень хорошо масштабируются, но их функциональность ограничена по сравнению с реляционными БД. Например, транзакционное обновление нескольких таблиц с высокой скоростью при помощи SQL-запросов — реальная проблема для NoSQL.
Некоторые из таких систем имеют очень похожие возможности по сравнению с YDB. У YDB, на наш взгляд, следующие плюсы:
Код большинства систем ведущих мировых облачных провайдеров закрыт. Некоторые из этих систем также завязаны на специализированное оборудование. Это лишает клиентов возможности локального развертывания системы и разворачивания в различных облаках. YDB, в свою очередь, работает на стандартном железе, её можно развернуть везде с помощью оператора Kubernetes или вручную.
YDB — ключевой компонент Yandex Cloud. Напомню, что вся облачная платформа построена на гиперконвергентной архитектуре. Это означает, что на одном и том же оборудовании работает слой storage и слой compute, они отделены и независимы друг от друга. На том же оборудовании работает и control plane. YDB обеспечивает уровень хранения данных в Yandex Cloud. Это и слой хранения данных для сетевых дисков, и слой хранения данных и метаданных инфраструктурных и платформенных сервисов. Также есть сервисы, которые сами предоставляют средства для работы с данными и реализованы поверх YDB: Monitoring — сервис для сбора и визуализации метрик приложений; Message Queue — очереди для обмена сообщениями между приложениями; Data Streams — масштабируемый сервис для управления потоками данных в реалтайме; Cloud Logging — предназначен для агрегации и чтения логов.
Команда Алисы решила переехать на YDB, когда готовилась к существенному росту нагрузки и объёмов данных. До переезда использовали другую базу и замечали нежелательные эффекты при переключении мастера между дата-центрами. После длительных регламентных работ отставшие на много часов реплики приходилось бережно возвращать в строй, тратить на них ресурсы девопс-команды. Переехав, команда смогла отказаться от ручного шардирования, получить из коробки строгую консистентность в кластере на три дата-центра и снизить девопс-нагрузку. Сейчас Алиса использует YDB в разных сценариях. Например, хранит в базе контекст для поддержания естественного диалога с пользователем, необходимую информацию для привязки активационных фраз устройств умного дома к их идентификаторам и расположению в доме. Оперативные логи инфраструктурной платформы разработчиков тоже хранятся в YDB.
У Авто.ру микросервисная архитектура. Коллеги пришли в YDB, когда столкнулись с тем, что существующие бэкенды базы для трейсов Jaeger стали очень дорогостоящими с точки зрения обработки количества трейсов на ядро сервера. Для команды YDB это был вызов, и мы реализовали специальный API (BulkUpsert) для записи логов и трейсов и оптимизировали базу для трейсов. Производительность YDB позволила в три раза сэкономить вычислительные ресурсы и писать все трейсы без сэмплинга (нагрузка трейсами на YDB сейчас составляет 500 000 спанов в секунду). Когда YDB зарекомендовала себя как экономичная, эффективная, отказоустойчивая база для хранения трейсов в Авто.ру и Яндекс Недвижимости, её также начали использовать как реляционную базу.
В Метрике анализируются визиты пользователей на сайты. Для этого необходимо хранить историю всех событий и «склеивать» их на лету. Раньше использовалась конвейерная распределённая система — со своим самописным локальным хранилищем и своей логикой репликации и шардирования. По мере роста нагрузки команда Метрики споткнулась о производительность шардов самописного хранилища, а продолжать наращивать количество шардов без принципиального изменения архитектуры было крайне болезненно.
Новым хранилищем визитов (после экспериментов и нагрузочного тестирования) стала YDB: база обеспечивает прозрачную масштабируемость по месту и по нагрузке. Это позволило продолжить наращивать трафик — сейчас база визитов содержит больше 100 терабайт данных и при этом держит нагрузку больше миллиона RPS. Подробнее про этот проект можно будет узнать из доклада Александра Прудаева на ближайшем HighLoad++.
Мы уверены, что бурное развитие технологий, которое мы наблюдаем в последние десятилетия, было бы невозможно без культуры опенсорс. Например, сейчас уже нельзя представить себе интернет без таких БД, как MySQL, PostgreSQL и ClickHouse, веб-серверов Apache и nginx — примеров можно привести множество.
Открытие проекта создаёт интереснейшую для всех win-win-ситуацию. У сообщества, с одной стороны, появляется возможность пользоваться уникальными наработками, в которые Яндекс инвестировал сотни человеко-лет, познакомиться с кодом, свободно запускать и разрабатывать у себя решения на базе YDB. Технологии, позволяющие Яндексу развиваться быстрее, оперативно реагировать на рост нагрузок и масштабироваться, теперь доступны каждому. С другой стороны, сильно увеличится вариативность пользователей, мы сможем получить обратную связь от мирового сообщества и сделать базу ещё лучше. Важно сломать барьер для пользователей, которые заинтересованы в технологии, но останавливаются, опасаясь закрытости и/или невозможности использовать её на своем оборудовании или в своих облаках.
Давайте попробуем самый простой вариант, который можно использовать для локального тестирования или отладки — Docker-контейнер.
По умолчанию в Docker-образе запускается база данных с именем
Загрузите актуальную версию Docker-образа:
Docker-контейнер YDB хранит данные в файловой системе контейнера, разделы которой отражаются на директории в хост-системе. Приведенная ниже команда запуска контейнера создаст файлы в текущей директории, поэтому перед запуском создайте рабочую директорию, и выполняйте запуск из неё.
Запустите YDB Docker-контейнер со следующими параметрами:
Параметры запуска:
С описанием дополнительных параметров запуска Docker-образа YDB можно ознакомиться в документации.
Для выполнения запросов и запуска тестовой нагрузки мы будем использовать консольный клиент YDB.
Установите YDB CLI по инструкции. Для проверки успешности соединения с базой данных выполните запрос к базе в Docker-контейнере:
Параметры запуска:
В результате вы должны увидеть сообщение:
Это значит, что соединение с базой прошло и запрос выполнен успешно.
Ниже — краткая инструкция по использованию синтаксиса YQL. Подробнее с синтаксисом и примерами использования можно познакомиться в документации к YQL.
Создайте таблицу с помощью инструкции CREATE TABLE:
Убедитесь что таблица создалась, с помощью команды получения списка объектов базы

Чтобы посмотреть свойства созданной таблицы, воспользуйтесь командой

Добавьте данные в таблицу с помощью инструкции INSERT INTO:
Прочитайте данные из таблицы с помощью инструкции SELECT:
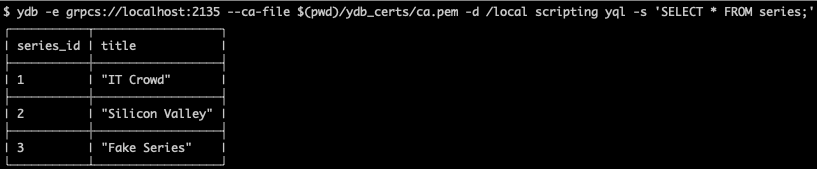
Обновите данные в таблице с помощью инструкции UPDATE:
Удалите данные в таблице с помощью инструкции DELETE:
Удалите таблицу с помощью инструкции DROP TABLE:
Встроенный YDB UI доступен на порту 8765. Перейдите по ссылке http://localhost:8765, чтобы познакомиться с его возможностями.
Для демонстрации работы и нагрузочного тестирования мы интегрировали в функциональность консольного клиента YDB симулятор склада интернет-магазина — создание заказов из нескольких товаров, получение списка заказов по клиенту.
Для начала работы нужно проинициализировать базу данных — создать таблицы и заполнить их данными. Для этого нужно выполнить команду:
Здесь:
Будут созданы таблицы со следующей структурой и настройками:
Остатки:
Заказы:
Позиции:
Запуск нагрузки insertRandomOrder на 10 секунд в 10 потоков с 1000 видов товаров:
Запуск нагрузки submitRandomOrder на 10 секунд в 5 потоков с 1000 видов товаров в заказе:
Запуск нагрузки getRandomCustomerHistory на 5 секунд в 10 потоков:
Пример результатов нагрузки:
Что означают результаты вывода:
После завершения работы с YDB остановите Docker-контейнер:
Мы постарались предоставить максимальную гибкость при использовании YDB. Для локального тестирования или отладки можно использовать Docker-контейнер или запустить кластер в Kubernetes (например, локально при помощи Minikube). Можно самостоятельно сконфигурировать и запустить кластер YDB с помощью подготовленной нами сборки.
Для промышленной эксплуатации мы рекомендуем развернуть YDB с помощью Kubernetes либо воспользоваться полностью управляемым сервисом в Yandex Cloud. И, конечно, вы всегда можете собрать YDB из исходников.
Выход в опенсорс — ни в коем случае не финальная остановка. Для нас это скорее начало пути к тому, чтобы стать одной из лучших баз в мире в своём сегменте. Предстоит серьёзная работа: прямо сейчас мы активно трудимся над расширением аналитических способностей YDB.
В разработке возможность «охлаждения» данных в таблицах YDB для удешевления их хранения. Также мы планируем подготовить драйверы для популярных бенчмарков (таких как TPC-C и YCSB), чтобы предоставить возможность тестировать YDB привычным способом и сравнивать базу с аналогами. Планируем продолжать работу над инструментами экспорта и импорта данных. Будем развивать CDC — генерацию потоков событий об изменениях в БД и механизм записи этих событий в поддерживаемые системы передачи (чтобы получить консистентное состояние при их обработке на «приёмнике»). И, конечно, одним из безусловных приоритетов для нас всегда остаётся повышение эффективности системы и улучшение производительности.
Если у вас возникли вопросы — спрашивайте в комментариях и задавайте их на Stack Overflow с тегом YDB. Узнать больше о возможностях и вариантах использования, познакомиться с документацией, а также загрузить необходимые файлы и инструменты можно на странице ydb.tech.

YDB решает задачи в одной из самых критичных областей — позволяет создавать интерактивные приложения, которые можно быстро масштабировать по нагрузке и по объёму данных. Мы разрабатывали её, исходя из ключевых требований к сервисам Яндекса. Во-первых, это катастрофоустойчивость, то есть возможность продолжить работу без деградации при отключении одного из дата-центров. Во-вторых, это масштабируемость на десятки тысяч серверов на чтение и на запись. В-третьих, это строгая консистентность данных.
В посте я расскажу об истории развития технологий баз данных, о том, зачем использовать YDB, как её применяют текущие пользователи и какие плюсы для всех несёт выход в опенсорс. А во второй половине поста поговорим о разных вариантах развёртывания.
В нашей компании YDB используется уже больше пяти лет. На мультитенантных кластерах развёрнуты базы с очень разными нагрузками и паттернами доступа к данным. На практике мы встречаемся с многократным ростом баз данных, ростом объёмов данных с единиц гигабайт до сотен терабайт и ростом нагрузок с тысяч до миллионов RPS. При этом решение задач масштабируемости и отказоустойчивости автоматически осуществляет база, снимая их с разработчиков прикладного кода. Но YDB распространена не только в проектах с высокой нагрузкой. Команды разработки Яндекса сами определяют свой стек в зависимости от задач, аудитории и другой специфики, и многие выбирают YDB за отказоустойчивость, даже если текущие нагрузки невелики. Одна из причин в том, что в случае внезапного роста нагрузок разработчикам будет достаточно добавить ресурсы, не внося изменения в код приложения и не прикладывая усилия к ручному перешардированию базы. Проекты в YDB размещают команды Алисы, Такси, Метрики и других сервисов — сейчас в системе почти 500 проектов.
Широкое распространение YDB внутри Яндекса, популярность в качестве сервиса Яндекс Облака и запросы пользователей cтали для нас хорошим стимулом раскрыть исходный код и сделать базу доступной для свободного использования.
Немного истории
За два последних десятилетия непрерывно растёт использование интернета, в последние годы он начал прочно входить в бытовую сферу. Часы, очки, лампочки, пылесосы — практически все устройства подключены к интернету или подключатся в скором времени. Всё это ведёт к непрерывному росту объёмов хранимых данных и нагрузок, которые БД обрабатывают.
С начала 2000-х вместе с бурным ростом интернета выросла популярность опенсорсных СУБД для OLTP-нагрузок — например, MySQL и PostgreSQL.
Без них или их аналогов сложно представить себе нынешние темпы развития интернета. Даже небольшие стартапы получили возможность работать с возрастающими нагрузками на бесплатных БД. Конечно, существовали тяжёлые коммерческие решения, которые позволяли масштабироваться вертикально, но они были доступны только большим компаниям с соответствующими бюджетами.
К середине 2000-х стали популярны разные виды логического шардирования БД — когда базу шардируют на несколько узлов, исходя из бизнес-логики приложения и его сущностей. Промежуточный слой между приложением и базой или само приложение принимает решение, на каком из узлов БД находятся данные. Но этот распространённый подход приводит к усложнению логики пользовательского приложения и значительно усложняет поддержку множества кластеров. Дополнительные сложности возникают при необходимости выполнить запрос, результат которого выдаёт консистентный результат объединения данных из разных шардов. Эту проблему можно решить за счёт отгрузки данных в отдельную систему или дополнительного усложнения логики приложения, но каждый такой дополнительный шаг только усложняет обслуживаемость системы и делает её менее технологичной. В то же время остаются открытыми такие вопросы, как перешардирование данных при росте нагрузки на конкретный шард. Сложно развить изначально выбранный подход к шардированию при изменившихся бизнес-требованиях к приложению. Нагрузки продолжают расти, а критичность отказов возрастает.
В конце 2000-х набирают популярность NoSQL-решения. Во главе угла становятся проблемы масштабируемости и отказоустойчивовости, в жертву приносится диалект SQL и функциональность join. Приемлемой считается eventual consistency, то есть консистентность в конечном итоге: рано или поздно все реплики во всех зонах доступности или регионах получат консистентный набор данных. Растёт популярность key-value-хранилищ (Redis, AWS DynamoDB), column-family (Cassandra, Hbase) и документных БД (MongoDB, Couchbase).
Мы шли тем же путем, и история развития OLTP СУБД в Яндексе повторяет историю развития операционных БД. Предшественником YDB была СУБД NoSQL (KV), которую мы разрабатывали с 2008 года.
Отсутствие поддержки ACID-транзакций приводит к необходимости самостоятельно их эмулировать. Возрастает сложность прикладного кода, и каждый разработчик фактически вынужден дорабатывать на стороне этого кода функциональность базы — что, во-первых очень сложно, а во-вторых, на большом количестве проектов требует множества костылей и велосипедов в каждом проекте.
Проблема оставалась актуальной. В начале 2010-х появляется новый термин — NewSQL. Про него рассказывают Майкл Стоунбрейкер и Энди Павло, описывая новые требования к OLTP СУБД (точнее, ожидания от такой базы).
NewSQL-базы должны обладать масштабируемостью и отказоустойчивовостью, свойственной NoSQL-системам, но при этом предоставлять ACID-гарантии транзакций и SQL-диалект. Чуть позже термин NewSQL трансформировался — масштабируемые, отказоустойчивые БД с поддержкой SQL и строгой консистентностью стали называть Distributed SQL Databases. Вдохновившись идеей NewSQL, в 2012 году мы сделали первый коммит в YDB.
Зачем использовать YDB
Рынок СУБД развивается давно, на нём представлено много известных и зрелых продуктов. Давайте разберём, какие преимущества может дать YDB в сравнении с другими базами.
Традиционные (нераспределённые) реляционные СУБД
Один из вариантов масштабирования в реляционных базах — ручное шардирование. То есть при разворачивании нужно настроить несколько экземпляров базы и решить, к какому экземпляру обращаться в вашем приложении. Если вам нужен одновременный доступ к данным из нескольких экземпляров БД, вам придется самостоятельно заниматься организацией распределённых транзакций. YDB масштабируется на чтение и запись «из коробки», для этого достаточно добавить больше оборудования в кластер. На практике мы работаем с базами размером в сотни терабайт под нагрузкой в миллионы RPS.
NoSQL-базы
NoSQL-базы очень хорошо масштабируются, но их функциональность ограничена по сравнению с реляционными БД. Например, транзакционное обновление нескольких таблиц с высокой скоростью при помощи SQL-запросов — реальная проблема для NoSQL.
Опенсорсные базы Distributed SQL
Некоторые из таких систем имеют очень похожие возможности по сравнению с YDB. У YDB, на наш взгляд, следующие плюсы:
- Яндекс как пользователь даёт YDB возможность на практике доказывать все свои свойства — поверх СУБД работает множество сервисов с высокими нагрузками и большими объёмами данных.
- Поверх YDB как платформы мы реализовали системы хранения и обработки данных: хранилище временных рядов, на базе которого построены мониторинги в Яндексе; персистентные очереди, на которых построена шина передачи данных Logbroker; Network Block Store — виртуальные диски для Yandex Cloud.
- YDB может стать экосистемой управления данными, поскольку она даёт возможность использовать механизм федеративных запросов и механизм потоковых запросов на базе YQL.
Проприетарные базы Distributed SQL
Код большинства систем ведущих мировых облачных провайдеров закрыт. Некоторые из этих систем также завязаны на специализированное оборудование. Это лишает клиентов возможности локального развертывания системы и разворачивания в различных облаках. YDB, в свою очередь, работает на стандартном железе, её можно развернуть везде с помощью оператора Kubernetes или вручную.
Опыт наших пользователей
Yandex Cloud
YDB — ключевой компонент Yandex Cloud. Напомню, что вся облачная платформа построена на гиперконвергентной архитектуре. Это означает, что на одном и том же оборудовании работает слой storage и слой compute, они отделены и независимы друг от друга. На том же оборудовании работает и control plane. YDB обеспечивает уровень хранения данных в Yandex Cloud. Это и слой хранения данных для сетевых дисков, и слой хранения данных и метаданных инфраструктурных и платформенных сервисов. Также есть сервисы, которые сами предоставляют средства для работы с данными и реализованы поверх YDB: Monitoring — сервис для сбора и визуализации метрик приложений; Message Queue — очереди для обмена сообщениями между приложениями; Data Streams — масштабируемый сервис для управления потоками данных в реалтайме; Cloud Logging — предназначен для агрегации и чтения логов.
Алиса
Команда Алисы решила переехать на YDB, когда готовилась к существенному росту нагрузки и объёмов данных. До переезда использовали другую базу и замечали нежелательные эффекты при переключении мастера между дата-центрами. После длительных регламентных работ отставшие на много часов реплики приходилось бережно возвращать в строй, тратить на них ресурсы девопс-команды. Переехав, команда смогла отказаться от ручного шардирования, получить из коробки строгую консистентность в кластере на три дата-центра и снизить девопс-нагрузку. Сейчас Алиса использует YDB в разных сценариях. Например, хранит в базе контекст для поддержания естественного диалога с пользователем, необходимую информацию для привязки активационных фраз устройств умного дома к их идентификаторам и расположению в доме. Оперативные логи инфраструктурной платформы разработчиков тоже хранятся в YDB.
Авто.ру
У Авто.ру микросервисная архитектура. Коллеги пришли в YDB, когда столкнулись с тем, что существующие бэкенды базы для трейсов Jaeger стали очень дорогостоящими с точки зрения обработки количества трейсов на ядро сервера. Для команды YDB это был вызов, и мы реализовали специальный API (BulkUpsert) для записи логов и трейсов и оптимизировали базу для трейсов. Производительность YDB позволила в три раза сэкономить вычислительные ресурсы и писать все трейсы без сэмплинга (нагрузка трейсами на YDB сейчас составляет 500 000 спанов в секунду). Когда YDB зарекомендовала себя как экономичная, эффективная, отказоустойчивая база для хранения трейсов в Авто.ру и Яндекс Недвижимости, её также начали использовать как реляционную базу.
Метрика
В Метрике анализируются визиты пользователей на сайты. Для этого необходимо хранить историю всех событий и «склеивать» их на лету. Раньше использовалась конвейерная распределённая система — со своим самописным локальным хранилищем и своей логикой репликации и шардирования. По мере роста нагрузки команда Метрики споткнулась о производительность шардов самописного хранилища, а продолжать наращивать количество шардов без принципиального изменения архитектуры было крайне болезненно.
Новым хранилищем визитов (после экспериментов и нагрузочного тестирования) стала YDB: база обеспечивает прозрачную масштабируемость по месту и по нагрузке. Это позволило продолжить наращивать трафик — сейчас база визитов содержит больше 100 терабайт данных и при этом держит нагрузку больше миллиона RPS. Подробнее про этот проект можно будет узнать из доклада Александра Прудаева на ближайшем HighLoad++.
Почему мы пошли в опенсорс
Мы уверены, что бурное развитие технологий, которое мы наблюдаем в последние десятилетия, было бы невозможно без культуры опенсорс. Например, сейчас уже нельзя представить себе интернет без таких БД, как MySQL, PostgreSQL и ClickHouse, веб-серверов Apache и nginx — примеров можно привести множество.
Открытие проекта создаёт интереснейшую для всех win-win-ситуацию. У сообщества, с одной стороны, появляется возможность пользоваться уникальными наработками, в которые Яндекс инвестировал сотни человеко-лет, познакомиться с кодом, свободно запускать и разрабатывать у себя решения на базе YDB. Технологии, позволяющие Яндексу развиваться быстрее, оперативно реагировать на рост нагрузок и масштабироваться, теперь доступны каждому. С другой стороны, сильно увеличится вариативность пользователей, мы сможем получить обратную связь от мирового сообщества и сделать базу ещё лучше. Важно сломать барьер для пользователей, которые заинтересованы в технологии, но останавливаются, опасаясь закрытости и/или невозможности использовать её на своем оборудовании или в своих облаках.
Как попробовать YDB
Давайте попробуем самый простой вариант, который можно использовать для локального тестирования или отладки — Docker-контейнер.
Работа с Docker-образом YDB
По умолчанию в Docker-образе запускается база данных с именем
/local и используются следующие порты:- Для взаимодействия с YDB API по gRPC без TLS — 2136.
- Для взаимодействия с YDB API по gRPC с поддержкой TLS — 2135. Сертификаты генерируются автоматически. Для использования сертификатов необходимо смонтировать на хост-системе директорию /ydb_cert Docker-контейнера.
- Встроенные средства мониторинга и интроспекции — 8765.
Загрузите актуальную версию Docker-образа:
docker pull cr.yandex/yc/yandex-docker-local-ydb:latestDocker-контейнер YDB хранит данные в файловой системе контейнера, разделы которой отражаются на директории в хост-системе. Приведенная ниже команда запуска контейнера создаст файлы в текущей директории, поэтому перед запуском создайте рабочую директорию, и выполняйте запуск из неё.
Запустите YDB Docker-контейнер со следующими параметрами:
docker run -d \
--rm \
--name ydb-local \
-h localhost \
-p 2135:2135 \
-p 8765:8765 \
-p 2136:2136 \
-v $(pwd)/ydb_certs:/ydb_certs -v $(pwd)/ydb_data:/ydb_data \
-e YDB_DEFAULT_LOG_LEVEL=NOTICE \
-e GRPC_TLS_PORT=2135 \
-e GRPC_PORT=2136 \
-e MON_PORT=8765 \
cr.yandex/yc/yandex-docker-local-ydb:latestПараметры запуска:
- -d — запустить Docker-контейнер в фоновом режиме.
- --rm — удалить контейнер после завершения его работы.
- --name — имя контейнера.
- -h — имя хоста контейнера.
- -p — опубликовать порты контейнера на хост-системе.
- -v — монтировать директории хост-системы в контейнер.
- -e — задать переменные окружения.
С описанием дополнительных параметров запуска Docker-образа YDB можно ознакомиться в документации.
Консольный клиент YDB CLI
Для выполнения запросов и запуска тестовой нагрузки мы будем использовать консольный клиент YDB.
Установите YDB CLI по инструкции. Для проверки успешности соединения с базой данных выполните запрос к базе в Docker-контейнере:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local table query execute -q 'select 1;'Параметры запуска:
- -e — эндпоинт базы данных.
- --ca-file — путь к TLS-сертификату.
- -d — имя базы данных и параметры запроса.
В результате вы должны увидеть сообщение:
┌─────────┐
| column0 |
├─────────┤
| 1 |
└─────────┘Это значит, что соединение с базой прошло и запрос выполнен успешно.
Использование языка запросов YQL
Ниже — краткая инструкция по использованию синтаксиса YQL. Подробнее с синтаксисом и примерами использования можно познакомиться в документации к YQL.
Создайте таблицу с помощью инструкции CREATE TABLE:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'CREATE TABLE series (series_id Uint64, title Utf8, PRIMARY KEY (series_id));'Убедитесь что таблица создалась, с помощью команды получения списка объектов базы
scheme ls:ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scheme ls
Чтобы посмотреть свойства созданной таблицы, воспользуйтесь командой
describe:ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scheme describe series
Добавьте данные в таблицу с помощью инструкции INSERT INTO:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'INSERT INTO series (series_id, title) VALUES (1, "IT Crowd"), (2, "Silicon Valley"), (3, "Fake Series");'Прочитайте данные из таблицы с помощью инструкции SELECT:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'SELECT * FROM series;'
Обновите данные в таблице с помощью инструкции UPDATE:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'UPDATE series SET title="Fake Series Updated" WHERE series_id = 3;'Удалите данные в таблице с помощью инструкции DELETE:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'DELETE FROM series WHERE series_id = 3;'Удалите таблицу с помощью инструкции DROP TABLE:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'DROP TABLE series;'YDB UI — ограничимся скриншотом
Встроенный YDB UI доступен на порту 8765. Перейдите по ссылке http://localhost:8765, чтобы познакомиться с его возможностями.

Запуск тестовой нагрузки YDB Workload
Для демонстрации работы и нагрузочного тестирования мы интегрировали в функциональность консольного клиента YDB симулятор склада интернет-магазина — создание заказов из нескольких товаров, получение списка заказов по клиенту.
Cимулятор склада позволяет запускать пять видов нагрузки
- getCustomerHistory — чтение заданного количества заказов покупателя с id = 10 000. Создаётся нагрузка на чтение одних и тех же строк из разных потоков.
- getRandomCustomerHistory — чтение заданного количества заказов случайно выбранного покупателя. Создаётся нагрузка на чтение из разных потоков.
- insertRandomOrder — создание случайно сгенерированного заказа. Например, клиент создал заказ из двух товаров, но ещё не оплатил его, поэтому остатки товаров не снижаются. В БД записывается информация о заказе и товарах. Создаётся нагрузка на запись и чтение.
- submitRandomOrder — создание и обработка случайно сгенерированного заказа. Например, покупатель создал и оплатил заказ из двух товаров. В БД записывается информация о заказе, товарах, проверяется их наличие и уменьшаются остатки. Создаётся смешанная нагрузка.
- submitSameOrder — создание заказов с одним и тем же набором товаров. Например, все покупатели покупают один и тот же набор (только что вышедший телефон и зарядное устройство). Создаётся нагрузка в виде конкурентного обновления одних и тех же строк в таблице.
Для начала работы нужно проинициализировать базу данных — создать таблицы и заполнить их данными. Для этого нужно выполнить команду:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local workload stock init -p 100 -q 1000 -o 1000Здесь:
- -p — количество видов товаров,
- -q — количество каждого вида товара на складе,
- -o — первоначальное количество заказов в базе.
Будут созданы таблицы со следующей структурой и настройками:
Остатки:
CREATE TABLE `stock`(
product Utf8,
quantity Int64,
PRIMARY KEY(product)
) WITH (
AUTO_PARTITIONING_BY_LOAD = ENABLED,
AUTO_PARTITIONING_MIN_PARTITIONS_COUNT = <min-partitions>
);Заказы:
CREATE TABLE `orders`(
id Uint64,
customer Utf8,
created Datetime,
processed Datetime,
PRIMARY KEY(id),
INDEX ix_cust GLOBAL ON (customer, created)
) WITH (
READ_REPLICAS_SETTINGS = "per_az:1",
AUTO_PARTITIONING_BY_LOAD = ENABLED,
AUTO_PARTITIONING_MIN_PARTITIONS_COUNT = <min-partitions>,
UNIFORM_PARTITIONS = <min-partitions>,
AUTO_PARTITIONING_MAX_PARTITIONS_COUNT = 1000
);Позиции:
CREATE TABLE `orderLines`(
id_order Uint64,
product Utf8,
quantity Int64,
PRIMARY KEY(id_order, product)
) WITH (
AUTO_PARTITIONING_BY_LOAD = ENABLED,
AUTO_PARTITIONING_MIN_PARTITIONS_COUNT = <min-partitions>,
UNIFORM_PARTITIONS = <min-partitions>,
AUTO_PARTITIONING_MAX_PARTITIONS_COUNT = 1000
);
Справка по свойствам таблиц YDB, которые используются в примере
В таблице YDB всегда есть один или несколько столбцов, составляющих первичный ключ (primary key), и она всегда упорядочена по первичному ключу.
Таблица может быть шардирована по диапазонам значений первичного ключа. Разные шарды таблицы могут обслуживаться разными серверами распределённой БД (в том числе расположенными в разных локациях), а также могут независимо друг от друга перемещаться между серверами для перебалансировки или поддержания работоспособности шарда при отказах серверов или сетевого оборудования.
При росте объёма данных, обслуживаемых шардом (как и при росте нагрузки на шард), YDB автоматически разбивает его на два. Разбиение происходит по медианному значению первичного ключа.
Помимо автоматического разделения вы можете создать пустую таблицу с предопределённым количеством шардов. При этом можно вручную задать точные границы разделения ключей по шардам или указать равномерное разделение на предопределённое количество шардов. Тогда границы создадутся по первой компоненте первичного ключа.
Можно определить следующие параметры партиционирования таблицы:
Таблица может быть шардирована по диапазонам значений первичного ключа. Разные шарды таблицы могут обслуживаться разными серверами распределённой БД (в том числе расположенными в разных локациях), а также могут независимо друг от друга перемещаться между серверами для перебалансировки или поддержания работоспособности шарда при отказах серверов или сетевого оборудования.
При росте объёма данных, обслуживаемых шардом (как и при росте нагрузки на шард), YDB автоматически разбивает его на два. Разбиение происходит по медианному значению первичного ключа.
Помимо автоматического разделения вы можете создать пустую таблицу с предопределённым количеством шардов. При этом можно вручную задать точные границы разделения ключей по шардам или указать равномерное разделение на предопределённое количество шардов. Тогда границы создадутся по первой компоненте первичного ключа.
Можно определить следующие параметры партиционирования таблицы:
- AUTO_PARTITIONING_BY_SIZE — режим автоматического партиционирования по размеру партиции. Если размер партиции превысил значение, заданное параметром AUTO_PARTITIONING_PARTITION_SIZE_MB, то она встаёт в очередь на разделение (split). Если суммарный размер двух соседних партиций меньше 50% от значения параметра AUTO_PARTITIONING_PARTITION_SIZE_MB, то они встают в очередь на объединение (merge).
- AUTO_PARTITIONING_PARTITION_SIZE_MB — предпочитаемый размер каждой партиции в мегабайтах.
- AUTO_PARTITIONING_BY_LOAD — режим автоматического партиционирования по нагрузке. Если в течение нескольких десятков секунд шард потребляет более 50% CPU, то он ставится в очередь на разделение (split). Если в течение часа суммарная нагрузка на два соседних шарда утилизировала менее 35% CPU, то они ставятся в очередь на объединение (merge). Выполнение операций разделения или объединения само по себе утилизирует CPU — и занимает время. Поэтому при работе с плавающей нагрузкой рекомендуется вместе с включением этого режима устанавливать отличное от 1 значение параметра минимального количество партиций AUTO_PARTITIONING_MIN_PARTITIONS_COUNT. Тогда спады нагрузки не приведут к снижению количества партиций ниже необходимого, и не будет потребности их заново делить при появлении нагрузки.
- AUTO_PARTITIONING_MIN_PARTITIONS_COUNT — объединение партиций (merge) производится, только если их фактическое количество превышает заданное этим параметром значение.
- AUTO_PARTITIONING_MAX_PARTITIONS_COUNT — разделение партиций (split) производится, только если их количество не превышает заданное этим параметром значение.
- UNIFORM_PARTITIONS — количество партиций для равномерного начального разделения таблицы. Первая колонка первичного ключа должна иметь тип Uint64 или Uint32. Созданная таблица сразу будет разделена на указанное количество партиций.
Чтение из реплик
При выполнении запросов в YDB фактическое выполнение запроса к каждому шарду осуществляется в единой точке, обслуживающей протокол распределённых транзакций. Но благодаря хранению данных на разделяемом хранилище возможен запуск одного или нескольких фолловеров шарда без выделения дополнительного места в хранилище — данные уже хранятся реплицированно и возможно обслуживание более одного читателя (но писатель при этом всё ещё в каждый момент строго один).
Применение чтения из фолловеров позволяет:
Применение чтения из фолловеров позволяет:
- Обслуживать клиентов, критичных к минимальным задержкам, недостижимым иными способами в мульти-ДЦ-кластере.
- Обслуживать читающие запросы из фолловеров без влияния на модифицирующие запросы, выполняющиеся на шарде.
- Продолжать обслуживание при переездах лидера партиции (как штатной, при балансировке, так и при сбоях).
- В целом повышать предел производительности чтения шарда, если множество читающих запросов попадают на одни и те же ключи. Можно указать необходимость запуска реплик для чтения для каждого шарда таблицы. Обращения к репликам для чтения (то есть к фолловерам) обычно происходят в пределах сети дата-центра, что позволяет обеспечить время ответа в единицы миллисекунд.
- READ_REPLICAS_SETTINGS — PER_AZ означает использование указанного количества реплик в каждой AZ.
Примеры запуска нагрузки
Запуск нагрузки insertRandomOrder на 10 секунд в 10 потоков с 1000 видов товаров:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local workload stock run insertRandomOrder -s 120 -t 10 -p 1000Запуск нагрузки submitRandomOrder на 10 секунд в 5 потоков с 1000 видов товаров в заказе:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local workload stock run submitRandomOrder -s 10 -t 5 -p 1000Запуск нагрузки getRandomCustomerHistory на 5 секунд в 10 потоков:
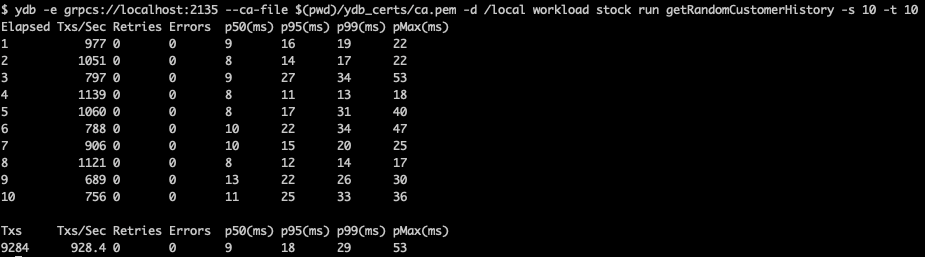
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local workload stock run getRandomCustomerHistory -s 5 -t 10Пример результатов нагрузки:
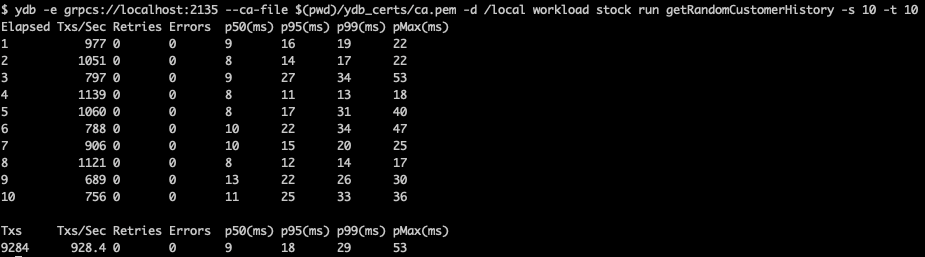
Что означают результаты вывода:
- Elapsed — номер временного окна. По умолчанию временное окно равно 1 секунде.
- Txs/sec — количество успешных транзакций нагрузки во временном окне.
- Retries — количество повторных попыток исполнения транзакции клиентом во временном окне.
- Errors — количество ошибок, случившихся во временном окне.
- p50(ms) — 50-й перцентиль latency запросов в мс.
- p95(ms) — 95-й перцентиль latency запросов в мс.
- p99(ms) — 99-й перцентиль latency запросов в мс.
- pMax(ms) — 100-й перцентиль latency запросов в мс.
- Timestamp — временная метка конца временного окна.
Завершение работы с Docker-контейнером
После завершения работы с YDB остановите Docker-контейнер:
docker kill ydb-localКакие еще есть варианты использования?
Мы постарались предоставить максимальную гибкость при использовании YDB. Для локального тестирования или отладки можно использовать Docker-контейнер или запустить кластер в Kubernetes (например, локально при помощи Minikube). Можно самостоятельно сконфигурировать и запустить кластер YDB с помощью подготовленной нами сборки.
Для промышленной эксплуатации мы рекомендуем развернуть YDB с помощью Kubernetes либо воспользоваться полностью управляемым сервисом в Yandex Cloud. И, конечно, вы всегда можете собрать YDB из исходников.
Что дальше?
Выход в опенсорс — ни в коем случае не финальная остановка. Для нас это скорее начало пути к тому, чтобы стать одной из лучших баз в мире в своём сегменте. Предстоит серьёзная работа: прямо сейчас мы активно трудимся над расширением аналитических способностей YDB.
В разработке возможность «охлаждения» данных в таблицах YDB для удешевления их хранения. Также мы планируем подготовить драйверы для популярных бенчмарков (таких как TPC-C и YCSB), чтобы предоставить возможность тестировать YDB привычным способом и сравнивать базу с аналогами. Планируем продолжать работу над инструментами экспорта и импорта данных. Будем развивать CDC — генерацию потоков событий об изменениях в БД и механизм записи этих событий в поддерживаемые системы передачи (чтобы получить консистентное состояние при их обработке на «приёмнике»). И, конечно, одним из безусловных приоритетов для нас всегда остаётся повышение эффективности системы и улучшение производительности.
Если у вас возникли вопросы — спрашивайте в комментариях и задавайте их на Stack Overflow с тегом YDB. Узнать больше о возможностях и вариантах использования, познакомиться с документацией, а также загрузить необходимые файлы и инструменты можно на странице ydb.tech.
