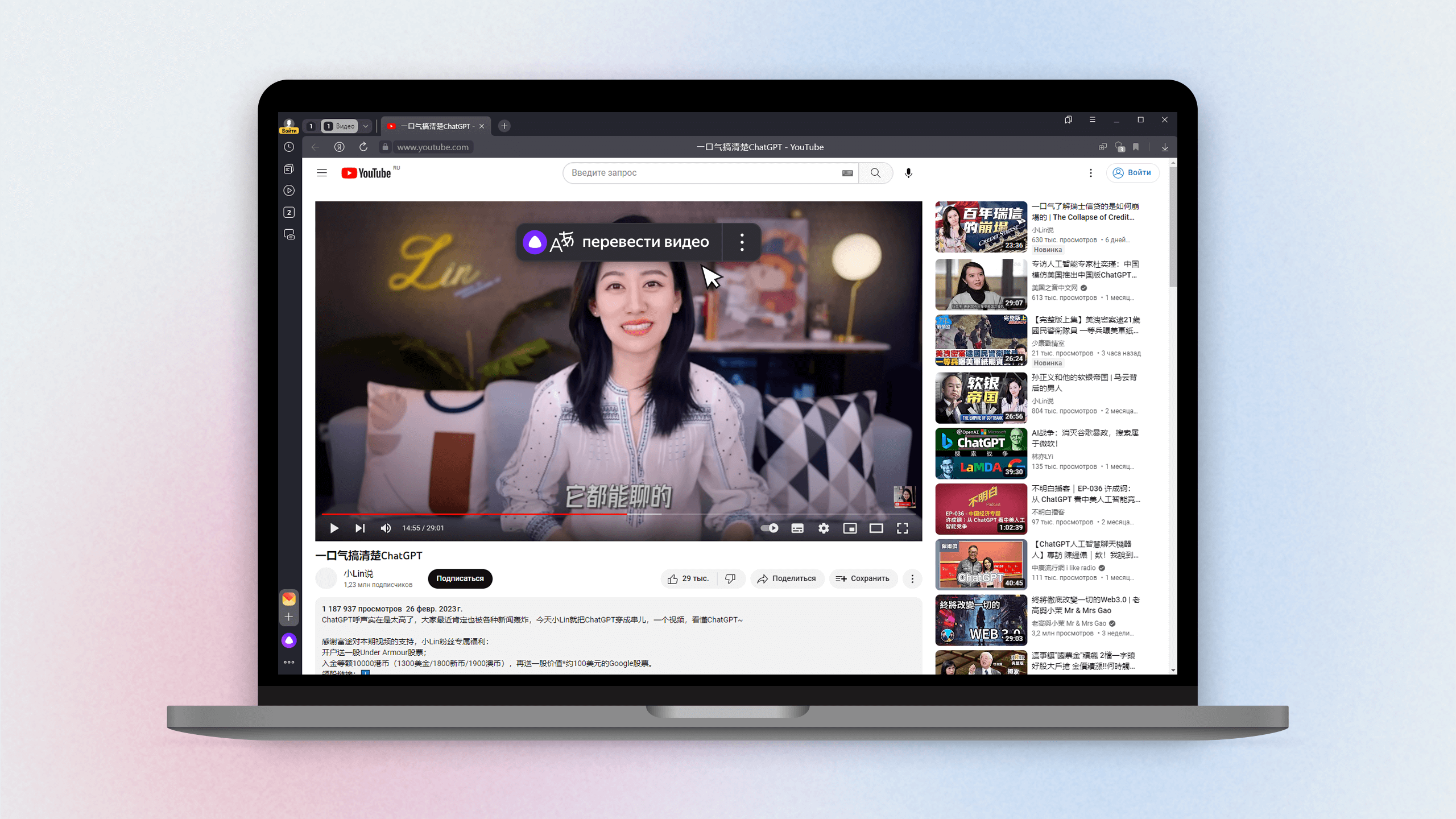
Привет, меня зовут Артур Яковлев, я делаю голосовой перевод видео в Яндекс Браузере. Примерно с лета я работаю над тем, чтобы научить Браузер переводить с китайского на русский. Почему мы посчитали это важной и интересной задачей? Дело в том, что китайская часть интернета содержит значительное количество видеоконтента, который за пределами страны почти не смотрят.
Множество диалектов, влияющие на смысл тоны и грамматические нюансы — ряд особенностей китайского усложняют разработку распознавания речи. Сейчас я коротко расскажу читателям Хабра о трудностях языка и объясню, как мы их преодолели.