Здравствуйте! Меня зовут Иван Давыдов, я занимаюсь исследованиями производительности в Яндекс.Деньгах.
Представьте, что у вас есть мощные сервера, на каждом из которых размещается ряд приложений. Если последних не очень много, они не мешают друг другу работать — им комфортно и уютно. Однажды вы приходите к микросервисам и выносите часть «тяжелой» функциональности в отдельные приложения.
Здесь можно увлечься, и микросервисов станет слишком много, вследствие чего станет сложно управлять ими и обеспечивать их отказоустойчивость. В итоге на каждом сервере станет «кучковаться» десяток приложений, которые борются за общие ресурсы. Получится «большая семья», а в большой семье клювом не щёлкай!
Однажды мы тоже с этим столкнулись. Моя история будет о тяжелых и бессонных ночах, когда я сидел под лампой в ночи и обстреливал прод. Всё началось с того, что мы стали замечать на боевых серверах проблемы, связанные с сетью.
Они сильно влияли на производительность и вносили ощутимые просадки. Параллельно выяснилось, что такие же ошибки возникают и при обычном пользовательском потоке, но в гораздо меньшем объеме.
Проблема скрывалась в утилизации TCP-сокетов более чем на 100%. Такое бывает, когда все имеющиеся на серверах сокеты постоянно открываются и закрываются. Из-за этого возникают сетевые проблемы взаимодействия между приложениями и появляются разного рода ошибки – недоступен удаленный хост, разорвано HTTP/HTTPS соединение (connection/read timeout, SSL peer shut down incorrectly) и другие.
Даже если у вас нет своего сервиса электронных платежей, оценить масштаб боли во время какой-нибудь очередной распродажи не сильно сложно – трафик увеличивается в несколько раз, а деградация производительности может привести к значительным убыткам. Так мы пришли к двум выводам – нужно оценить, как используются текущие мощности, и изолировать приложения друг от друга.
Чтобы изолировать приложения, мы решили прибегнуть к контейнеризации. Для этого мы использовали гипервизор, который содержит множество отдельных контейнеров с приложениями. Это позволяет изолировать ресурсы процессора, памяти, устройств ввода/вывода, сети, а также деревья процессов, пользователей, файловые системы и так далее.
При таком подходе каждое приложение имеет свое окружение, что обеспечивает гибкость, изолированность, надежность, и повышает общую производительность системы. Это красивое и элегантное решение, но перед этим необходимо ответить на ряд вопросов:
- Какой запас по производительности имеет один инстанс приложения на текущий момент?
- Как масштабируется приложение и есть ли избыточность по ресурсам в текущей конфигурации?
- Возможно ли повысить производительность одного инстанса и что является «узким местом»?
С такими вопросами коллеги пришли к нам – команде исследователей производительности.
Чем мы занимаемся?
Мы делаем всё для обеспечения производительности нашего сервиса и, в первую очередь, исследуем и улучшаем её для бизнес-процессов нашего продакшена. Каждый бизнес-процесс, будь то оплата товара в магазине кошельком или перевод денег между пользователями, по сути, представляет для нас цепочку запросов в системе.
Мы проводим эксперименты и составляем отчеты, чтобы оценить производительность системы при высокой интенсивности входящих запросов. Отчёты содержат метрики производительности и подробное описание выявленных проблем и узких мест. С помощью этой информации мы улучшаем и оптимизируем нашу систему.
Оценка потенциала каждого приложения осложняется тем, что в организации последовательности запросов бизнес-процесса участвуют несколько микросервисов, использующих мощности всех задействованных инстансов.
Выражаясь метафорически, мы знаем мощь нашей армии, но не знаем потенциала каждого из бойцов. Поэтому, в дополнение к текущим исследованиям, необходимо проводить оценку используемых ресурсов в рамках процесса управления мощностями. Этот процесс называется «Capacity management».
Наши исследования помогают выявлять и предотвращать нехватку ресурсов, прогнозировать закупки железа и иметь точные данные о текущих и потенциальных возможностях системы. В рамках такого процесса отслеживается актуальная производительность приложений (как медианная, так и максимальная) и предоставляются данные о текущем запасе.
Суть управления мощностями – в поиске баланса между потребляемыми ресурсами и производительностью.
Плюсы:
- В любой момент известно, что происходит с производительностью каждого приложения.
- Меньше рисков при добавлении новых микросервисов.
- Меньше затрат на закупки нового оборудования.
- Те мощности, что уже есть, используются более разумно.
Как работает управление мощностями
Вернемся к нашей ситуации со множеством приложений. Мы провели исследование, целью которого была оценка того, как используются мощности на продакшн-серверах.
Вкратце план действий такой:
- Определить пользовательскую интенсивность на конкретных приложениях.
- Составить профиль стрельбы.
- Оценить производительность каждого инстанса приложения.
- Оценить масштабируемость.
- Составить отчеты и заключения о минимально необходимом количестве инстансов для каждого приложения в боевой среде.
А теперь подробнее.
Инструменты
Для сбора метрик пользовательской интенсивности мы используем Heka и Zabbix. Для визуализации собранных метрик используется Grafana.
Zabbix нужен для наблюдения за ресурсами серверов, такими как: CPU, Memory, Network connections, DB и другими. Heka предоставляет данные по количеству и времени выполнения входящих/исходящих запросов, сбор метрик по внутренним очередям приложений и ещё бесконечное количество других данных. Grafana – гибкий инструмент для визуализации, который используют разные команды Яндекс.Денег. Мы – не исключение.
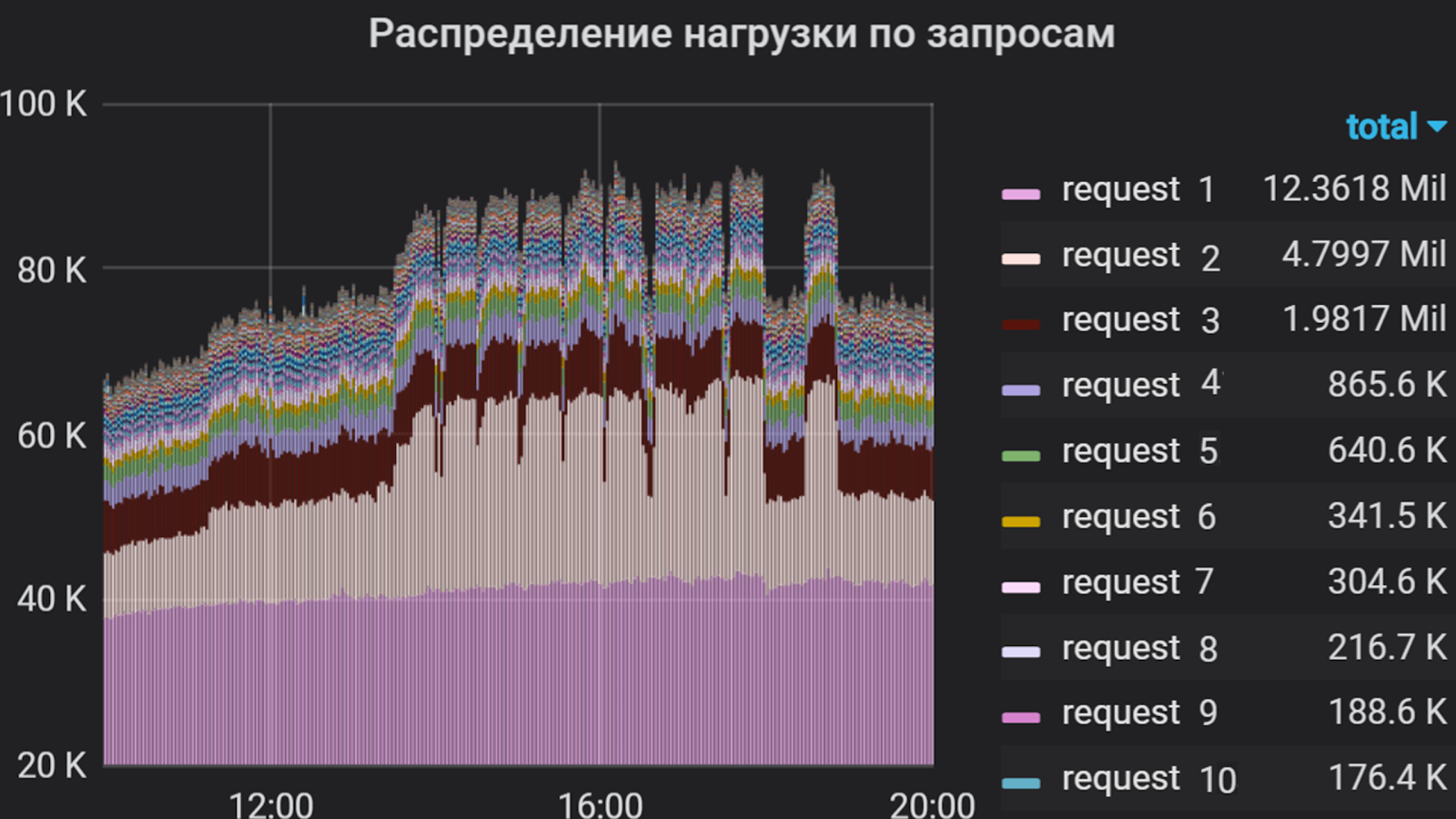
Grafana умеет показывать, например, такие вещи
В качестве генератора трафика используется Apache JMeter. С его помощью составляется сценарий стрельбы, который включает реализацию запросов, мониторинг валидности ответа, гибкое управление подаваемого потока и многое другое. Данный инструмент имеет как свои плюсы, так и минусы, но углубляться «почему именно данный продукт?» я не буду.
В дополнение к JMeter используется фреймворк yandex-tank – инструмент для нагрузочного тестирования и анализа производительности веб-сервисов и приложений. Он позволяет подключать свои модули для получения любых нужных функций и выводить результаты в консоли или в виде графиков. Результаты наших стрельб отображаются в Лунапарке (аналог https://overload.yandex.net), где мы можем за ними подробно наблюдать в реальном времени, вплоть до секундных пиков, обеспечивая необходимую и достаточную дискретность, и тем самым более оперативно реагировать на всплески, возникающие при стрельбе. В графане тоже можно настраивать дискретность, но данное решение является более затратным по физическим и логическим ресурсам. А иногда мы даже выгружаем сырые данные и визуализируем их через GUI Jmeter. Но только – тссс!
Кстати, о деградации. Практически любые сбои, возникающие в приложении под большим потоком трафика, оперативно анализируются с помощью Kibana. Но это тоже не панацея – некоторые сетевые проблемы можно проанализировать только посредством снятия и анализа трафика.
С помощью Grafana мы проанализировали пользовательскую интенсивность в приложении за несколько месяцев. За единицу измерения решили взять суммарное процессорное время выполнения запросов, то есть учитывались количество запросов и время их выполнения. Так мы составили список самых «тяжелых» запросов, которые составляют большую часть потока на приложение. Именно этот список и лег в основу профиля стрельбы.

Пользовательская интенсивность на приложение за несколько месяцев
Профиль стрельбы и пристрелка
Мы называем стрельбой запуск сценария в рамках проводимого эксперимента. Профиль составляется из двух частей.
Первая часть – составление сценария запросов. При реализации необходимо проанализировать пользовательскую интенсивность на каждый входящий запрос приложения и сделать процентное соотношение между ними, чтобы выявить топ самых вызываемых и долго выполняемых. Вторая часть – подбор параметров роста потока: с какой интенсивностью и как долго подавать нагрузку.
Для большей наглядности методику составления профиля лучше продемонстрировать на примере.
В Grafana строится график, который отражает пользовательскую интенсивность и долю каждого запроса в общем потоке. На основе данного распределения и времени ответа по каждому из запросов составляются группы в JMeter, каждая из которых является независимым генератором трафика. В основу сценария ложатся только самые «тяжелые» запросы, так как реализовать все (в некоторых приложениях их более сотни) затруднительно, да это и не всегда требуется из-за их сравнительно низкой интенсивности.

Процентное соотношение запросов
В данном исследовании рассматривается пользовательская интенсивность на постоянном потоке, а периодически возникающие «всплески» чаще всего рассматриваются в частном порядке.
В нашем примере рассматривается две группы. В первую группу вошли «request 1» и «request 2» в соотношении 1 к 2. Аналогично во вторую группу вошли запросы 3 и 4. Остальные запросы компонента имеют гораздо меньшую интенсивность, поэтому мы не включаем их в сценарий.

Распределение запросов по группам в Jmeter
Исходя из медианного времени ответа по каждой из групп, производится оценка производительности по формуле:
x = 1000 / t, где t – медианное время, мс
Получаем результат вычисления и оцениваем приблизительную интенсивность при увеличении числа потоков:
TPS = x * p, где p – количество потоков, TPS – transaction per second, а x – это результат предыдущего вычисления.
Если запрос обрабатывается за 500 мс, то при одном потоке мы имеем 2 Tps, а при 100 потоках в идеале должны иметь 200 Tps. Исходя из полученных результатов можно подобрать первоначальные параметры роста. После первых итераций исследований эти параметры обычно корректируются.
Когда сценарий стрельбы готов, мы запускаем пристрелку – стрельбу на одну минуту в один поток. Это делается для того, чтобы проверить работоспособность сценария при постоянном потоке, оценить время ответа на запросы в каждой из групп и получить процентное соотношение по запросам.
При прогоне такого профиля мы выяснили, что при одинаковой интенсивности процентное соотношение запросов сохраняется, так как среднее время ответа во второй группе больше, чем в первой. Поэтому мы выставили одинаковую скорость роста потока для обеих групп. В иных случаях пришлось бы экспериментальным путем подбирать параметры для каждой группы по отдельности.
В этом примере интенсивность подавалась ступенчато, то есть добавлялось некоторое число потоков за определенный интервал.

Параметры роста интенсивности
Параметры роста интенсивности были такими:
- Целевое количество потоков – 100 (определяется при пристрелке).
- Рост в течение 1000 секунд (~16 мин.).
- 100 ступеней.
Таким образом, каждые 10 секунд мы добавляем по одному потоку. Интервал между добавлением потоков и количество добавляемых потоков варьируются в зависимости от поведения системы на конкретном шаге. Зачастую интенсивность подается с плавным ростом, чтобы можно было отслеживать состояние системы на каждой из ступеней.
Боевые стрельбы
Обычно стрельба запускается ночью с удаленных серверов. В это время пользовательский трафик минимален – это значит, что стрельба почти не повлияет на пользователей, и погрешность в результатах будет меньше.
По результатам первых стрельб в один инстанс корректируем количество потоков и время роста, анализируем поведение системы в целом и находим отклонения в работе. После всех корректировок запускается повторная стрельба в один инстанс. На этом этапе мы определяем максимальную производительность и отслеживаем использование аппаратных ресурсов как сервера с приложением, так и всего, что за ним стоит.
По результатам стрельбы, производительность одного инстанса нашего приложения составила порядка 1000 Tps. При этом был зафиксирован рост времени ответа по всем запросам без увеличения производительности, то есть мы достигли насыщения, но не деградации.
На следующем этапе сравниваем результаты, полученные с других инстансов. Это важно, так как железо может отличаться, а значит, разные инстансы могут давать сильно разные показатели. Так было и у нас – часть серверов оказалась на порядок производительнее в силу поколения и характеристик. Поэтому мы выделили группу серверов с лучшими результатами и исследовали масштабируемость на них.
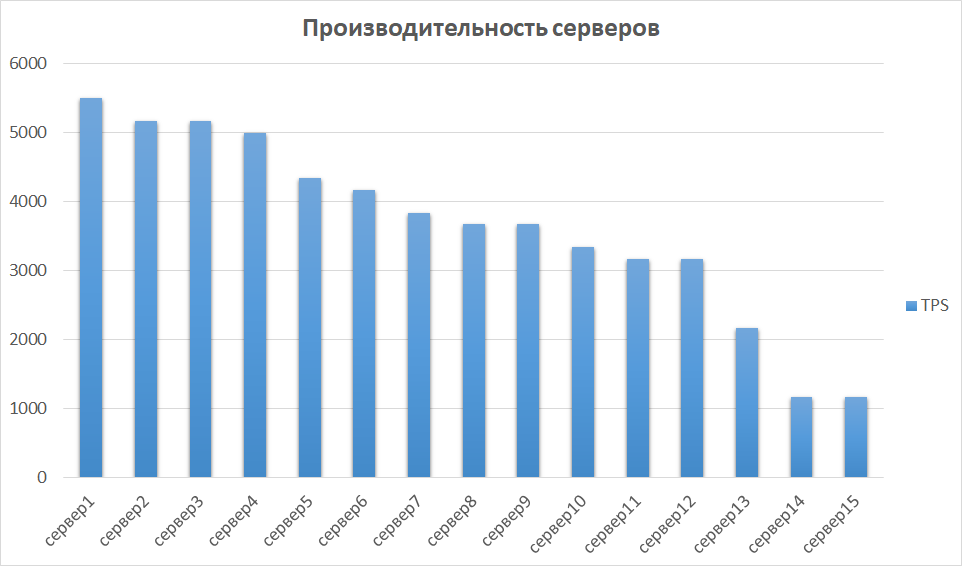
Сравнение производительности серверов
Масштабируемость и поиск узких мест
Следующий шаг – исследовать производительность на 2, 3 и 4 инстансах. В теории производительность должна расти линейно с увеличением количества инстансов. На практике обычно всё не так.
В нашем примере получился практически идеальный вариант.

Причиной насыщения роста производительности являлось исчерпание пулов коннекторов до последующего бэкенда. Это решается управлением размером пулов на исходящей и входящей стороне и приводит к увеличению производительности приложения.
В других исследованиях мы столкнулись с более интересными вещами. Эксперименты показали, что вместе с производительностью сильно растет утилизация CPU и коннектов баз данных. В нашем случае это произошло из-за того, что в конфигурации с одним инстансом мы упирались в собственные настройки пулов приложения, а при двух инстансах увеличили это количество вдвое, тем самым удвоив исходящий поток. БД оказалась не готова к такому объему. Из-за этого стали забиваться пулы к БД, процент потребляемого CPU добрался до критической отметки в 99%, и увеличивалось время обработки запросов, а часть трафика вообще отваливалась. И такие результаты мы получили уже при двух инстансах!
Чтобы окончательно убедиться в своих опасениях, мы провели стрельбу в 3 инстанса. Результаты оказались приблизительно такими же, как и при первых двух, разве что быстрее пришли к разладке.
Есть еще один пример «затыков», который, на мой взгляд, является самым болезненным – это плохо написанный код. Тут может быть все, что угодно, начиная с запросов к БД, которые выполняются минутами, заканчивая кодом, который нерационально использует память Java-машины.
Итоги
В результате у исследуемого в нашем примере инстанса приложения запас по производительности оказался более чем в 5 раз.
Для увеличения производительности необходимо рассчитать достаточное количество пулов обработчика в настройках приложения. Достаточно двух инстансов для конкретного приложения, а использование всех 15, которые есть в наличии, избыточно.
После исследования получены следующие результаты:
- Определена и поставлена на мониторинг пользовательская интенсивность за 1 месяц.
- Выявлен запас по производительности одного инстанса приложения.
- Получены результаты об ошибках, возникающих под большим потоком.
- Выявлены узкие места для дальнейшей работы над увеличением производительности.
- Выявлено минимально достаточное количество инстансов для корректной работы приложения. И, как следствие, выявлена избыточность использования мощностей.
Результаты исследования легли в основу проекта по переводу компонентов в контейнеры, о котором мы расскажем в следующих статьях. Теперь мы можем точно сказать, сколько контейнеров и с какими характеристиками необходимо иметь, как рационально использовать их мощности и над чем стоит поработать, чтобы обеспечивать производительность на должном уровне.
Заходите в наш уютный телеграм-чатик, где вы всегда можете попросить совета, помочь коллегам и просто пообщаться тему исследований производительности.
На сегодня всё. Задавайте вопросы в комментариях и подписывайтесь на блог Яндекс.Денег – скоро мы расскажем о фишинге и как на него не попадаться.
