Всем привет! Меня зовут Сергей Орешкин, я CDO Московской Биржи. Вместе с моими коллегами – Петром Лукьянченко (бизнес), Владимиром Молостовым и Федором Темнохудом (ИТ) – мы расскажем об опыте поиска, выбора решения и запуска платформы ресурсоемких вычислений на большом объёме данных на базе Hadoop.
Каждый день только на рынке акций Мосбиржи почти 100 тысяч частных инвесторов совершает более 20 млн транзакций объемом от 40 млрд рублей. Один из ключевых параметров, которыми оперируют инвесторы, принимая решения о сделке, – это ликвидность бумаги. Бумага считается ликвидной, если её можно купить или продать по желаемой цене за минимальное время. По малоликвидным бумагам инвестору приходится ждать, прежде чем найдется другой инвестор, готовый заключить сделку на взаимовыгодных условиях. Для инвестора такое ожидание – это издержки, а вероятность образования таких издержек называется риском ликвидности.
Для Биржи риск ликвидности – тоже явление нежелательное, в результате его реализации резко падает объем торгов, и клиент не может продать/купить бумагу по комфортной для него цене. А задача биржи обеспечить такую возможность для клиента в любой момент – причем по хорошей цене. Чтобы минимизировать риск ликвидности во всем мире работает институт маркетмейкерства: брокеры и банки наполняют стаканы заявками на покупку и продажу бумаг, за что получают вознаграждение от биржи. И, конечно же, мы хотим платить маркетмейкерам только тогда, когда их услуги действительно нужны – а это значит, что мы должны точно знать, что происходит с инструментами, которые представлены на том или ином рынке, и насколько велик риск ликвидности по каждому из них. Учитывая, что количество торгуемых бумаг крайне велико, и торгуются они высокочастотно и супербыстро, нам нужен инструмент, который позволит обсчитать огромный объем данных «на лету».
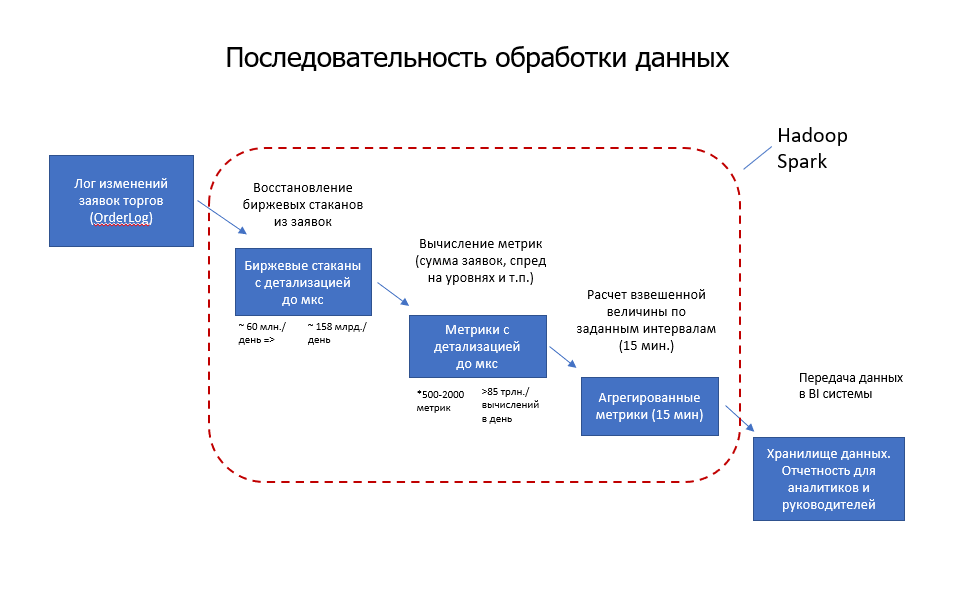
Говоря «биржевым» языком, перед нами встала задача расчета метрик ликвидности и метрик маркетмейкерских программ. Для её решения нам потребовалась система, выполняющая большой объем расчетов на торговых данных, которая позволила бы на основе данных об изменениях рыночных заявок рассчитывать сотни аналитических показателей в различных разрезах, а также моделировать поведение рынка, оценивая вклад конкретного участника. Чтобы создать ядро этой системы, мы разработали прототип горизонтально масштабируемой платформы для массово-параллельных вычислений на базе кластера Hadoop. В целевой конфигурации платформа способна эффективно обрабатывать огромные массивы информации – десятки триллионов вычислений в день.
Рассказываем, почему мы выбрали именно это решение и в чем его польза для Биржи.