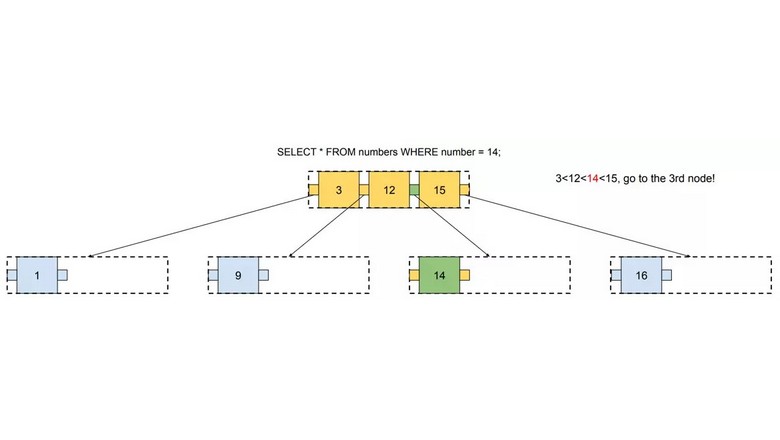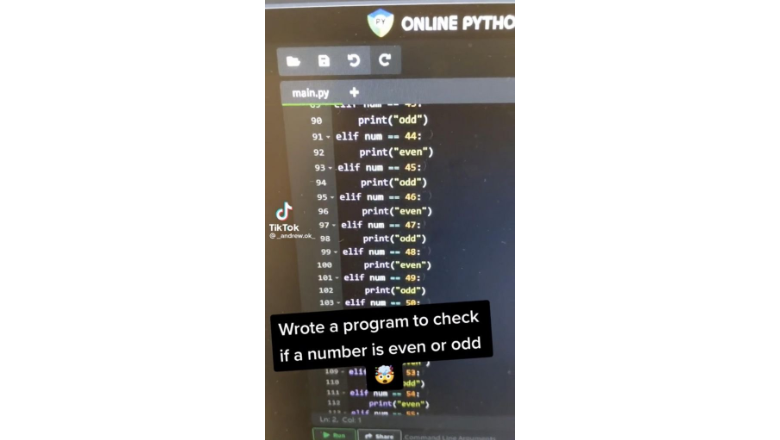
Просматривая недавно соцсети, я наткнулся на этот скриншот. Разумеется, его сопровождало множество злобных комментариев, критикующих попытку этого новичка в программировании решить классическую задачу computer science: операцию деления с остатком.
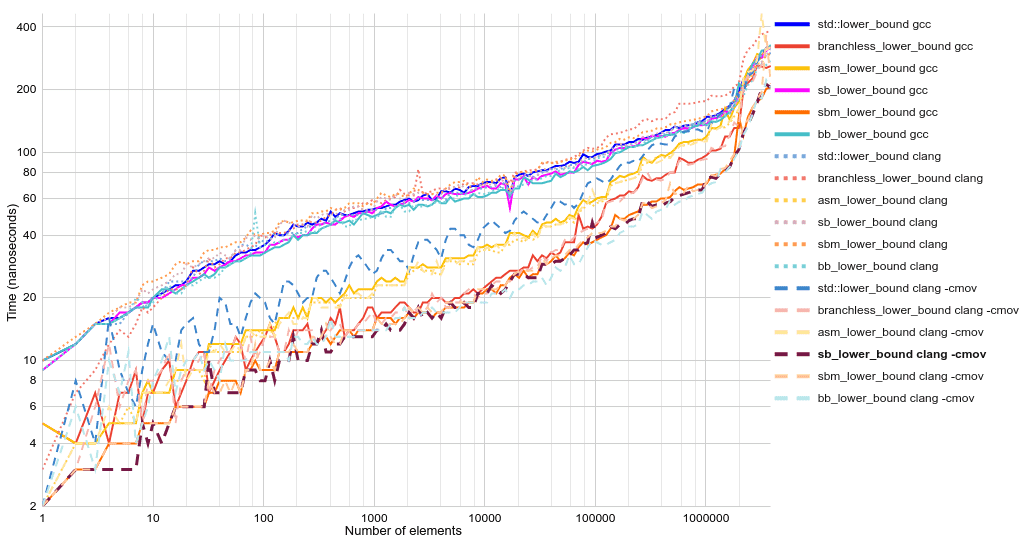
В современном мире, где ИИ постепенно заменяет программистов, отнимая у них работу и совершая переворот в том, как мы подходим к рассуждениям о коде, нам, возможно, следует быть более открытыми к мыслям людей, недавно пришедших в нашу отрасль? На самом деле, показанный выше код — идеальный пример компромисса между временем и задействованной памятью. Мы жертвуем временем и в то же время памятью и временем компьютера! Поистине чудесный алгоритм!
Поэтому я решил изучить эту идею проверки чётности числа при помощи одних сравнений, чтобы понять, насколько хорошо она работает в реальных ситуациях. Я сторонник высокопроизводительного кода, поэтому решил реализовать это на языке программирования C, потому что он и сегодня остаётся самым быстрым языком в мире с большим отрывом от других (благодаря гению Денниса Ричи).