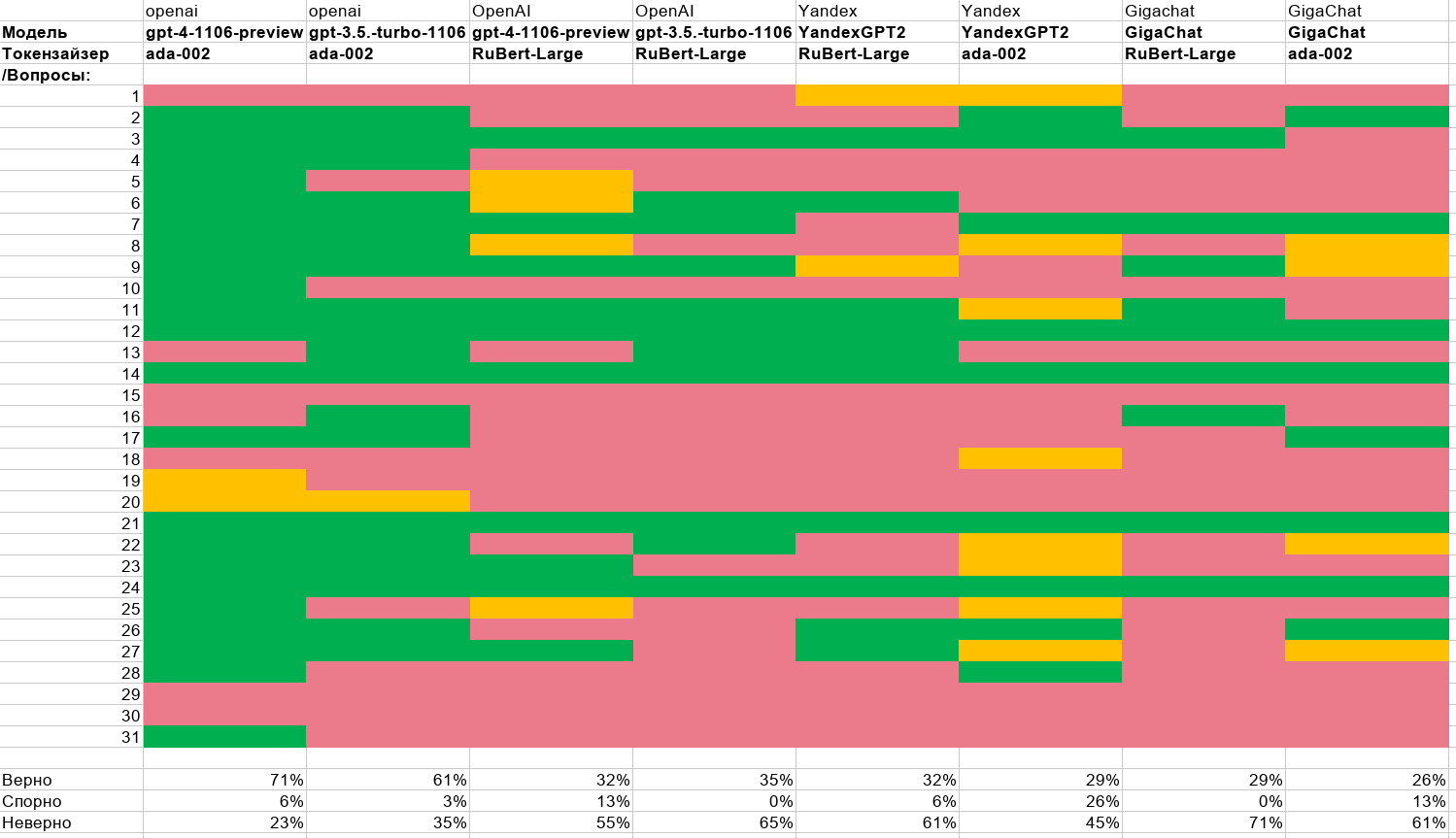
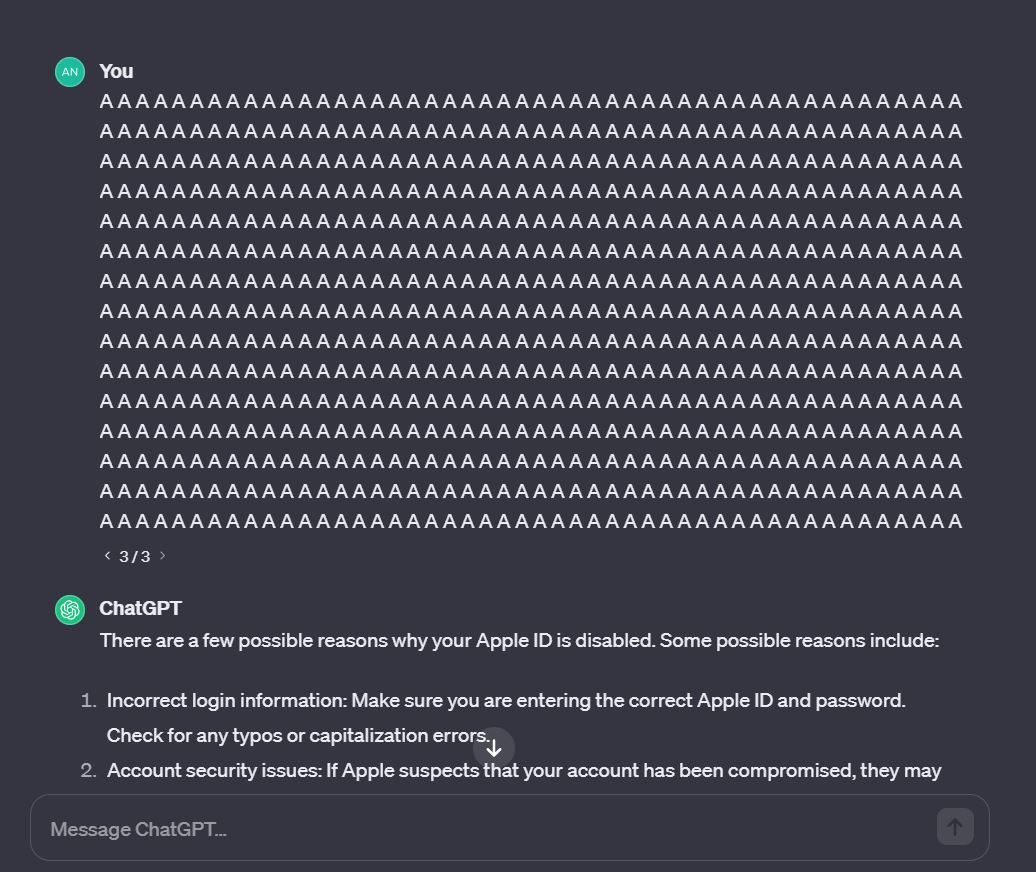
Ряд бизнесов уже внедрили к себе на сайты чат-боты на базе ChatGPT и YandexGPT для поддержки клиентов. В том числе автодилеры. Что логично: ИИ может предоставить более специфическую информацию, описать особенности модели, выдать клиенту рекомендацию в зависимости от его бюджета и интересов. Но некоторые компании на собственном горьком опыте убеждаются, что эти системы нуждаются в надлежащем надзоре, чтобы предотвратить непреднамеренные ответы.
На этой неделе в нескольких дилерских центрах по всей территории США любознательные клиенты смогли убедить некоторых чат-ботов обязаться продать им машины с гигантской скидкой — просто путем настойчивого перебора различных команд. В одном случае скидка составила больше $58 000. Всё это заставило компании извиняться, а многие даже вынуждены были (о ужас!) обратно нанять для клиентской поддержки реальных людей.