
В прошлой заметке я рассказывал о проблемах с рекурсией в функции Фибоначчи при использовании 64-битных переменных в качестве ее аргументов и компиляции кода с помощью Microsoft Visual C++. Выяснилось, что компилятор включает хвостовую рекурсию, когда используются 32-битные переменные, но не делает этого при переходе к 64-битным. На всякий случай напомню, что хвостовая рекурсия – это оптимизация, производимая компилятором, при которой некоторые виды хвостовых вызовов преобразуются в безусловные переходы. Узнать больше о хвостовой рекурсии.
Хвостовая рекурсия в C++ с использованием 64-битных переменных — Часть 1
3 мин
Перевод
В этот раз я хочу поделиться с вами одной проблемой, с которой столкнулся, когда решил сравнить итерационные и рекурсивные функции в C++. Между рекурсией и итерацией есть несколько отличий: о них подробно рассказано в этой стать. В языках общего назначения вроде Java, C или Python рекурсия довольно затратна по сравнению с итерацией из-за необходимости каждый раз выделять новый стековый фрэйм. В C/C++ эти затраты можно легко устранить, указав оптимизирующему компилятору использовать хвостовую рекурсию, при которой определенные типы рекурсии (а точнее, определенные виды хвостовых вызовов) преобразуются в команды безусловного перехода. Для осуществления такого преобразования необходимо, чтобы самым последним действием функции перед возвратом значения был вызов еще одной функции (в данном случае себя самой). При таком сценарии безусловный переход к началу второй подпрограммы безопасен. Главный недостаток рекурсивных алгоритмов в императивных языках заключается в том, что в них не всегда возможно иметь хвостовые вызовы, т.е. выделение места для адреса функции (и связанных с ней переменных, например, структур) на стеке при каждом вызове. При слишком большой глубине рекурсии это может привести к переполнению стека из-за ограничения на его максимальный размер, который обычно на порядки меньше объема оперативной памяти.
Многомерное дерево Mtree
3 мин
Recovery Mode
Организация данных в программировании имеет определяющее значение. Способов организации данных не так уж много. Среди различных структур данных особое место занимает организация данных в виде дерева.
Jancy — скриптовый язык для системных/сетевых программистов
14 мин
 Зачем вообще создавать новый язык программирования? Их уже существует невероятное количество — по моему твёрдому убеждению, значительно больше, чем надо. И наверняка далеко не последнюю роль в данном положении вещей играет то, что создание компиляторов — это невероятно увлекательный процесс. С поправкой на арбузы и свиные хрящики — это вообще одна из самых «вкусных» работ, о которых может мечтать увлечённый программист.
Зачем вообще создавать новый язык программирования? Их уже существует невероятное количество — по моему твёрдому убеждению, значительно больше, чем надо. И наверняка далеко не последнюю роль в данном положении вещей играет то, что создание компиляторов — это невероятно увлекательный процесс. С поправкой на арбузы и свиные хрящики — это вообще одна из самых «вкусных» работ, о которых может мечтать увлечённый программист.Непередаваемо здоровским является цветочно-конфетный период — первый этап изучения теории компиляторов по толстым умным книжкам, и — тут же! — её применения на практике, в своём собственном языке. Даже печальная перспектива того, что создатель языка вполне может оказаться его единственным пользователем, не способна перевесить радость творчества и остановить сферического-в-вакууме компиляторного Кулибина. Разумеется, если удовлетворение собственного интереса является не только важной, но и единственной движущей силой всего процесса — вышеописанная перспектива с неизбежностью будет воплощена в жизнь. Но даже если это и НЕ единственная причина создания нового языка — перспектива стать одиноким пользователем своего творения всё равно имеет шансы реализоваться.
Оберон умер, да здравствует Оберон! Часть 1. Некоторые любят поактивней
5 мин
Языкам программирования семейства Оберон не суждено было прорваться в мейнстрим, хотя они и оставили заметный след в IT-индустрии. Однако, и операционные системы, написанные на этих языках (являясь одновременно и программными каркасами различных решений и средами разработки), и сами языки программирования используются в учебной, исследовательской и промышленной сферах и по сей день, понуждая к творчеству и экспериментам, развиваясь и впитывая новые веянья индустрии и влияя на неё.
Этой обзорной статьёй я открываю серию статей, посвящённых языку Активный Оберон и операционной системе A2, написанной на этом языке.
Первая публикация по Активному Оберону появилась в 1997 году, но понятно, что язык и его реализация появились несколько раньше. За эти годы произошло много изменений в языке, переработана среда времени выполнения, написана операционная система A2…
Этой обзорной статьёй я открываю серию статей, посвящённых языку Активный Оберон и операционной системе A2, написанной на этом языке.
Итак, встречайте — Активный Оберон
Первая публикация по Активному Оберону появилась в 1997 году, но понятно, что язык и его реализация появились несколько раньше. За эти годы произошло много изменений в языке, переработана среда времени выполнения, написана операционная система A2…
Метапрограммирование: какое оно есть и каким должно быть
11 мин

Метапрограммирование — вид программирования, связанный с созданием программ, которые порождают другие программы как результат своей работы (wiki). Это достаточно общий термин, к которому, согласно той же википедии, относится и генерация исходного кода внешними инструментами, и различные препроцессоры, и «плагины к компилятору» — макросы с возможностью модификации синтаксического дерева не посредственно в процессе компиляции, и даже такая экзотическая возможность, как самомодифицирующийся код — модификация программы самой программой непосредственно во время выполнения.
Хотя, конечно, самомодифицирующийся код — это скорее отдельная большая тема, достойная отдельного исследования; здесь под метапрограммированием мы будем понимать процессы, происходящие во время компиляции программы.
Метапрограммирование реализовано в той или иной мере в очень разных языках; если не рассматривать экзотические и близкие к ним языки, то самым известным примером метапрограммирования является С++ с его системой шаблонов. Из «новых» языков можно рассмотреть D и Nim. Одна из самых удачных попыток реализации метапрограммирования — язык Nemerle. Собственно, на примере этой четверки мы и рассмотрим сабж.
Метапрограммирование — интереснейшая тема; в этой статье я попытаюсь разобраться, что же это такое, и каким оно должно быть в идеальном случае.
Циклические контейнеры в Objective-C
2 мин
Перевод
Некоторое время назад я написал этот код:
Заметили проблему? Я — нет.
NSMutableArray *environments = [NSMutableArray new];
for (NSString *key in [dictionary allKeys]) {
XCCEnvironment *environment = [[XCCEnvironment alloc] initWithName:key
parameters:dictionary[key]];
[environments addObject:environments];
}
return environments;
Заметили проблему? Я — нет.
Изменения в Visual C++
12 мин
Перевод
Когда вы захотите обновить версию Visual C++ компилятора (например, перейти с Visual Studio с 2013 на 2015), будет не лишним узнать, почему вы можете столкнуться с тем, что код, который прежде успешно компилировался и выполнялся, теперь будет вызывать ошибки компиляции и/или ошибки времени выполнения.
Эти проблемы могут быть вызваны многочисленными изменениями компилятора для соответствия стандарту С++, изменениями в сигнатурах функций или изменениями расположения объектов в памяти.
Эти проблемы могут быть вызваны многочисленными изменениями компилятора для соответствия стандарту С++, изменениями в сигнатурах функций или изменениями расположения объектов в памяти.
Оптимизируем шаг за шагом с компилятором Intel C++
8 мин

Каждый разработчик рано или поздно сталкивается с проблемой оптимизации своего приложения, причём сделать это хочется с минимальным вложением усилий и максимальной выгодой в плане производительности. В этом вопросе на помощь приходит компилятор, который на сегодняшний день многое умеет делать автоматически, нужно только сказать ему об этом с помощью ключей. Опций компиляции, как и видов оптимизации, развелось достаточно много, поэтому я решил написать блог о пошаговой оптимизации приложения с помощью компилятора Intel.
Итак, весь тернистый путь компиляции и оптимизации нашего приложения можно разбить на 7 шагов. Пошагали!
Новый инструмент анализа SIMD программ — Vectorization Advisor
6 мин
В блоге компании опубликовано уже немало постов, посвященных векторизации, вот, например, довольно обстоятельный обзор принципов автовекторизации. С каждым выходом новых процессоров Intel тема становится все более актуальной для достижения максимальной производительности приложения. В этом посте я расскажу о Vectorization Advisor, который входит в знакомый многим Intel Advisor XE и позволяет решить множество проблем векторизации кода. Однако сначала о том, зачем это нужно.
Разбор естественного языка: под капотом
4 мин

API синтаксического анализатора
Продолжаю свой предыдущий пост. Время сфокусироваться на деталях внутреннего устройства синтаксического анализатора. В качестве языка реализации я выбрал Go, поскольку хотел малой ценой получить параллельный (в смысле, использующий все доступные ядра CPU) производительный инструмент, без погружения в низкоуровневую пучину C++.
Полученный код предоставляет следующий API:
type Attribute struct {
Name string
Value string
}
type ParseMatch struct {
Text string
Nonterminal string
Rule string
Attributes []Attribute
Submatches []ParseMatch
Hypotheses []string
HypothesisCount uint
}
func Parse(text, nonterminal string, hypotheses_limit uint) []ParseMatch
Match ссылается на дочерние объекты того же типа, соотвествующие нетерминалам или лексическим терминалам подошедшего правила. В общем случае, из-за неоднозначности, присущей естественным языкам, тексту соответствует несколько разборов (например, из-за наличия омонимов). Поэтому функция Parse возвращает множество объектов Match. Вышеупомянутая неоднозначность синтаксического разбора должна устраняться на следующем (семантическом) уровне анализа текста.
Итак, функция Parse берёт text — текст для разбора, nonterminal — название нетерминала (например, «sentence»), а также максимальное число выдвигаемых гипотез hypotheses_limit (об этом чуть ниже). Параметр nonterminal может быть пустым. В этом случае тексту будет сопоставляться лексический терминал, найденный в морфологической базе.
В терминах данного анализатора гипотеза — это предположение того, что нарушенное ограничение значения атрибута вызвано случайной причиной. Если анализатор встречает несоответствие значения атрибута ограничению, заданному рассматриваемым в данный момент правилом, а число выдвинутых гипотез не достигло hypotheses_limit, то данное несоответствие игнорируется. В противном случае рассматриваемое правило отбрасывается. Данный механизм удобен для отладки правил, но должен избегаться в реальной работе, поскольку чудовищно замедляет процесс разбора.
LLILC — транслятор MSIL в байткод LLVM от Microsoft
1 мин
Сегодня сотрудник Microsoft анонсировал проект  LLILC — новый проект для трансляции MSIL в байткод LLVM, предназначенный пока главным образом для инфраструктуры CoreCLR. В ближайшее время он может быть использован для JIT-компиляции, а в дальнейшем и для формирования прекомпилированных сборок (Ahead-of-Time) средствами .NET Native.
LLILC — новый проект для трансляции MSIL в байткод LLVM, предназначенный пока главным образом для инфраструктуры CoreCLR. В ближайшее время он может быть использован для JIT-компиляции, а в дальнейшем и для формирования прекомпилированных сборок (Ahead-of-Time) средствами .NET Native.
Несмотря на то, что в CoreCLR уже есть свой JIT, планируется расширить поддержку различных платформ за счёт LLVM. Новый JIT использует тот же набор внутренних API, что и RyuJIT и бесшовно его заменяет. Таким образом новый JIT позволит .NET-коду выполняться на всех поддерживаемых LLVM-платформах, на которые можно портировать CoreCLR.
LLILC — новый проект для трансляции MSIL в байткод LLVM, предназначенный пока главным образом для инфраструктуры CoreCLR. В ближайшее время он может быть использован для JIT-компиляции, а в дальнейшем и для формирования прекомпилированных сборок (Ahead-of-Time) средствами .NET Native.Несмотря на то, что в CoreCLR уже есть свой JIT, планируется расширить поддержку различных платформ за счёт LLVM. Новый JIT использует тот же набор внутренних API, что и RyuJIT и бесшовно его заменяет. Таким образом новый JIT позволит .NET-коду выполняться на всех поддерживаемых LLVM-платформах, на которые можно портировать CoreCLR.
Разбор естественного языка: грамматическая нотация
6 мин

Я уже довольно давно интересуюсь ИИ, особенно областью, связанной с пониманием машиной текстов, написанных на естественном языке. Как известно, классическая теория анализа текста разделяет этот процесс на три этапа:
- Морфологический — анализ словоформ и их характеристик (число, падеж, и т.д.);
- Синтаксический — выделение структуры предложения (отношения между словами);
- Семантический — выделение смысла исходя из «модели мира»;
Первый этап в целом решён. Мы имеем подробные морфологические словари, покрывающие львиную долю слов, встречающихся в большинстве текстов. Кроме того, для распространённых языков существуют правила, позволяющие с достаточной точностью классифицировать неизвестные словоформы.
Ситуация с синтаксическим разбором куда более сложная. Существующие анализаторы не могут претендовать на правильность и точность разбора в сложных случаях. Большая часть качественных продуктов выпущены под проприетарной лицензией (в большей мере это касается русского языка; с английским проблема, кажется, не стоит столь остро). Поэтому для прогресса в понимании машиной текстов, написанных на естественном языке, мы нуждаемся в качественных и доступных синтаксических анализаторах.
Из-за отсутствия у меня глубоких знаний в области нейронных сетей я решил следовать более проторенной тропой, а именно разработать BNF-подобную грамматическую нотацию и реализовать анализатор, использующий грамматические правила, описанные с её помощью. С этой точки зрения при разработке практически полезного анализатора основная работа заключается именно в построении достаточной системы правил (что у меня далеко до завершения). В следующем посте я опишу устройство реализованного анализатора, а пока хочу сфокусироваться на разработанной грамматической нотации.
Ближайшие события






Firebird Conf: конференция для разработчиков и администраторов СУБД Firebird
6 июня
09:00 – 20:00
Москва

Генерация кода во время исполнения или «Пишем свой JIT-компилятор»
18 мин
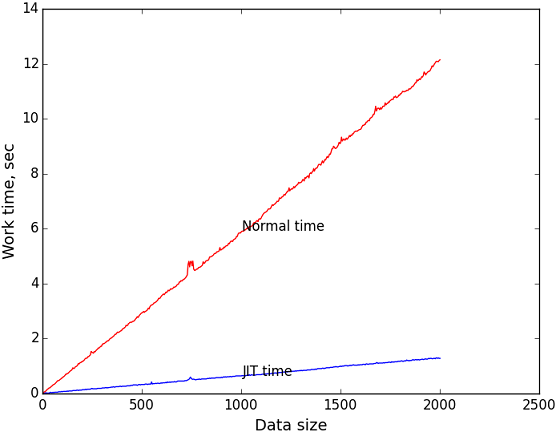
Современные компиляторы очень хорошо умеют оптимизировать код. Они удаляют никогда не выполняющиеся условные переходы, вычисляют константные выражения, избавляются от бессмысленных арифметических действий (умножение на 1, сложение с 0). Они оперируют данными, известными на момент компиляции.
В момент выполнения информации об обрабатываемых данных гораздо больше. На её основании можно выполнить дополнительные оптимизации и ускорить работу программы.
Оптимизированный для частного случая алгоритм всегда работает быстрее универсального (по крайней мере, не медленнее).
Что если для каждого набора входных данных генерировать оптимальный для обработки этих данных алгоритм?
Очевидно, часть времени выполнения уйдёт на оптимизацию, но если оптимизированный код выполняется часто, затраты окупятся с лихвой.
Как же технически это сделать? Довольно просто — в программу включается мини-компилятор, генерирующий необходимый код. Идея не нова, технология называется “компиляция времени исполнения” или JIT-компиляция. Ключевую роль JIT-компиляция играет в виртуальных машинах и интерпретаторах языков программирования. Часто используемые участки кода (или байт-кода) преобразуются в машинные команды, что позволяет сильно повысить производительность.
Java, Python, C#, JavaScript, Flash ActionScript — неполный (совсем неполный) список языков, в которых это используется. Я предлагаю решить конкретную задачу с использованием этой технологии и посмотреть, что получится.
«Нежданчики» языка Фортран
6 мин

Многие из нас, обучаясь программированию ещё в университетах или дома, делали это на языках С/С++. Конечно, всё зависит от времени, в которое начиналось наше знакомство с языками программирования. Скажем, кто-то начинал с Фортрана, другие — с Basic’a или Delphi, но стоит признать, что доля начавших свой тернистый путь программиста с С/С++ наибольшая. К чему я всё это? Когда перед нами стоит задача изучить новый язык и написать на нём код, мы часто основываемся на том, как бы я это написал на своём «базовом» языке. Сузим вопрос — если нужно написать что-то на Фортране, то мы вспоминаем, как бы это было реализовано на С и делаем по аналогии. Очередной раз столкнувшись с тонкостью языка, которая привела к абсолютно неработающему алгоритму и большой проблеме, эскалированной мне, я решил отыскать как можно больше нюансов языка Фортран (Fortran 90/95), по сравнению с С, с которыми столкнулся лично. Это своего рода «нежданчики», которые ты явно не планировал увидеть, а они бац – и всплыли!
Конечно, речь не пойдёт о синтаксисе — в каждом языке он свой. Я попробую рассказать о глобальных вещах, способных изменить всё «с ног на голову». Поехали!
Большое обзорное тестирование языков программирования
9 мин
Недавно очередной раз отработал со студентам 2-го курса 2-семестровую дисциплину «Алгоритмические языки». Обзорно рассмотрели несколько дюжин языков программирования. Один из студентов, Вадим Шукалюк, захотел получше с ними познакомиться, получить более четкое представление о каждом из них. Посоветовал ему провести небольшое исследование. Чем и увлёк. Предлагаю свой отчёт по проделанной за несколько месяцев вместе с ним работе.
У каждого языка программирования есть свои достоинства и недостатки. Одна из важнейших характеристик транслятора с любого языка — это скорость исполнения программ. Очень трудно или даже невозможно получить точную оценку такой скорости исполнения. Ресурс http://benchmarksgame.alioth.debian.org/ предлагает игровую форму для проверки такой скорости на разных задачах. Но число языков, представленных на этом ресурсе, довольно невелико. Предельную ёмкость стека, критическую величину для рекурсивных вычислений проверить проще, но она может меняться в разных версиях транслятора и быть зависимой от системных настроек.
Тестировались следующие трансляторы: си (gcc, clang, icc), ассемблер (x86, x86-64), ява (OpenJDK), паскаль (fpc), яваскрипт (Google Chrome, Mozilla Firefox), лисп (sbcl, clisp), эрланг, хаскель (ghc, hugs), дино[1], аук (gawk, mawk, busybox), луа, рубин, бейсик (gambas, libre office), питон-2, пи-эйч-пи, постскрипт (gs), пролог (swipl, gprolog), перл, метапост, ТEХ, тикль, бэш. Исследовались как собственно скорость исполнения нескольких небольших, но трудоёмких алгоритмов, так и:
У каждого языка программирования есть свои достоинства и недостатки. Одна из важнейших характеристик транслятора с любого языка — это скорость исполнения программ. Очень трудно или даже невозможно получить точную оценку такой скорости исполнения. Ресурс http://benchmarksgame.alioth.debian.org/ предлагает игровую форму для проверки такой скорости на разных задачах. Но число языков, представленных на этом ресурсе, довольно невелико. Предельную ёмкость стека, критическую величину для рекурсивных вычислений проверить проще, но она может меняться в разных версиях транслятора и быть зависимой от системных настроек.
Тестировались следующие трансляторы: си (gcc, clang, icc), ассемблер (x86, x86-64), ява (OpenJDK), паскаль (fpc), яваскрипт (Google Chrome, Mozilla Firefox), лисп (sbcl, clisp), эрланг, хаскель (ghc, hugs), дино[1], аук (gawk, mawk, busybox), луа, рубин, бейсик (gambas, libre office), питон-2, пи-эйч-пи, постскрипт (gs), пролог (swipl, gprolog), перл, метапост, ТEХ, тикль, бэш. Исследовались как собственно скорость исполнения нескольких небольших, но трудоёмких алгоритмов, так и:
- качество оптимизации некоторых трансляторов;
- особенности при работе с процессорами Intel и AMD;
- предельное число рекурсивных вызовов (ёмкость стека).
И ещё раз про уникальные константы
3 мин
Прочитав статью «Вычислите длину окружности», которая, в общем-то, крайне позабавила меня своим стилем, и узнав для себя кое-что новое, я стал несколько сомневаться в достаточной подробности предложенной информации. Всё-таки компиляторов довольно много, систем тоже немало, а в статье как-то навеяно Windows и Visual Studio (на правах ИМХО).
Deconvolutional Neural Network
9 мин
Туториал
Использование классических нейронных сетей для распознавания изображений затруднено, как правило, большой размерностью вектора входных значений нейронной сети, большим количеством нейронов в промежуточных слоях и, как следствие, большими затратами вычислительных ресурсов на обучение и вычисление сети. Сверточным нейронным сетям в меньшей степени присущи описанные выше недостатки.
Свёрточная нейронная сеть (англ. convolutional neural network, CNN) — специальная архитектура искусственных нейронных сетей, предложенная Яном Лекуном и нацеленная на эффективное распознавание изображений, входит в состав технологий глубокого обучения (англ. deep leaning). Эта технология построена по аналогии с принципами работы зрительной коры головного мозга, в которой были открыты так называемые простые клетки, реагирующие на прямые линии под разными углами, и сложные клетки, реакция которых связана с активацией определённого набора простых клеток. Таким образом, идея сверточных нейронных сетей заключается в чередовании сверточных слоев (англ. convolution layers) и субдискретизирующих слоев (англ. subsampling layers, слоёв подвыборки).[6]
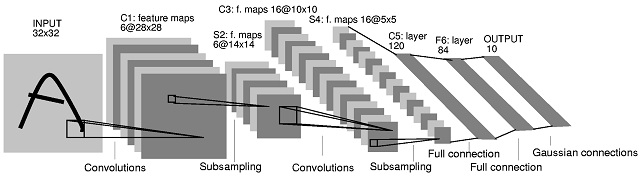
Рис 1. Архитектура сверточной нейронной сети
Ключевым моментом в понимании сверточных нейронных сетей является понятие так называемых «разделяемых» весов, т.е. часть нейронов некоторого рассматриваемого слоя нейронной сети может использовать одни и те же весовые коэффициенты. Нейроны, использующие одни и те же веса, объединяются в карты признаков (feature maps), а каждый нейрон карты признаков связан с частью нейронов предыдущего слоя. При вычислении сети получается, что каждый нейрон выполняет свертку (операцию конволюции) некоторой области предыдущего слоя (определяемой множеством нейронов, связанных с данным нейроном). Слои нейронной сети, построенные описанным образом, называются сверточными слоями. Помимо, сверточных слоев в сверточной нейронной сети могут быть слои субдискретизации (выполняющие функции уменьшения размерности пространства карт признаков) и полносвязные слои (выходной слой, как правило, всегда полносвязный). Все три вида слоев могут чередоваться в произвольном порядке, что позволяет составлять карты признаков из карт признаков, а это на практике означает способность распознавания сложных иерархий признаков [3].
Что же именно влияет на качество распознавания образов при обучении сверточных нейронных сетей? Озадачившись данным вопросом, наткнулись на статью Мэттью Зайлера (Matthew Zeiler).
Свёрточная нейронная сеть (англ. convolutional neural network, CNN) — специальная архитектура искусственных нейронных сетей, предложенная Яном Лекуном и нацеленная на эффективное распознавание изображений, входит в состав технологий глубокого обучения (англ. deep leaning). Эта технология построена по аналогии с принципами работы зрительной коры головного мозга, в которой были открыты так называемые простые клетки, реагирующие на прямые линии под разными углами, и сложные клетки, реакция которых связана с активацией определённого набора простых клеток. Таким образом, идея сверточных нейронных сетей заключается в чередовании сверточных слоев (англ. convolution layers) и субдискретизирующих слоев (англ. subsampling layers, слоёв подвыборки).[6]
Рис 1. Архитектура сверточной нейронной сети
Ключевым моментом в понимании сверточных нейронных сетей является понятие так называемых «разделяемых» весов, т.е. часть нейронов некоторого рассматриваемого слоя нейронной сети может использовать одни и те же весовые коэффициенты. Нейроны, использующие одни и те же веса, объединяются в карты признаков (feature maps), а каждый нейрон карты признаков связан с частью нейронов предыдущего слоя. При вычислении сети получается, что каждый нейрон выполняет свертку (операцию конволюции) некоторой области предыдущего слоя (определяемой множеством нейронов, связанных с данным нейроном). Слои нейронной сети, построенные описанным образом, называются сверточными слоями. Помимо, сверточных слоев в сверточной нейронной сети могут быть слои субдискретизации (выполняющие функции уменьшения размерности пространства карт признаков) и полносвязные слои (выходной слой, как правило, всегда полносвязный). Все три вида слоев могут чередоваться в произвольном порядке, что позволяет составлять карты признаков из карт признаков, а это на практике означает способность распознавания сложных иерархий признаков [3].
Что же именно влияет на качество распознавания образов при обучении сверточных нейронных сетей? Озадачившись данным вопросом, наткнулись на статью Мэттью Зайлера (Matthew Zeiler).
Intel® Graphics Technology. Часть III: эффективные вычисления на графике
5 мин
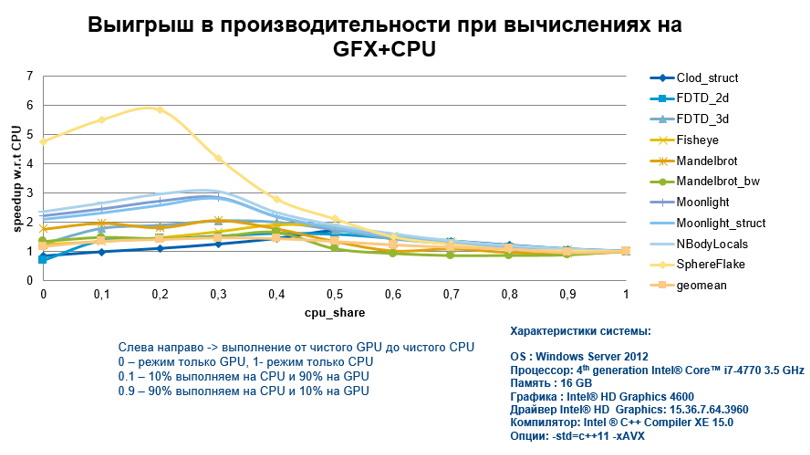
В комментариях к прошлому посту был поднят весьма важный вопрос – а будет ли вообще выигрыш в производительности от выгрузки вычислений на интегрированную графику, по сравнению с выполнением только на CPU? Конечно, он будет, но нужно соблюдать определенные правила программирования для эффективных вычислений на GFX+CPU.
В подтверждение моих слов, сразу представлю график ускорения, получаемого при выполнении вычислений на интегрированной графике, для различных алгоритмов и с разной долей вовлеченности CPU. На КДПВ мы видим, что выигрыш более чем весомый.
Использование расширенных возможностей компилятора Intel® C++ для приложений Android
4 мин
Перевод
Компилятор Intel C++ предоставляет много возможностей для оптимизации приложений под самые различные задачи, в том числе для мобильных устройств. В этой статье мы затронем два аспекта оптимизации: во-первых, поговорим об использовании выполняемого модуля Intel Cilk Plus в Android для реализации многопоточности приложений, во-вторых, коснемся темы использования Profile-guided Optimization (PGO) для повышения производительности приложений в ОС Android. Ссылки для более глубокого изучения этих тем даны в конце статьи.