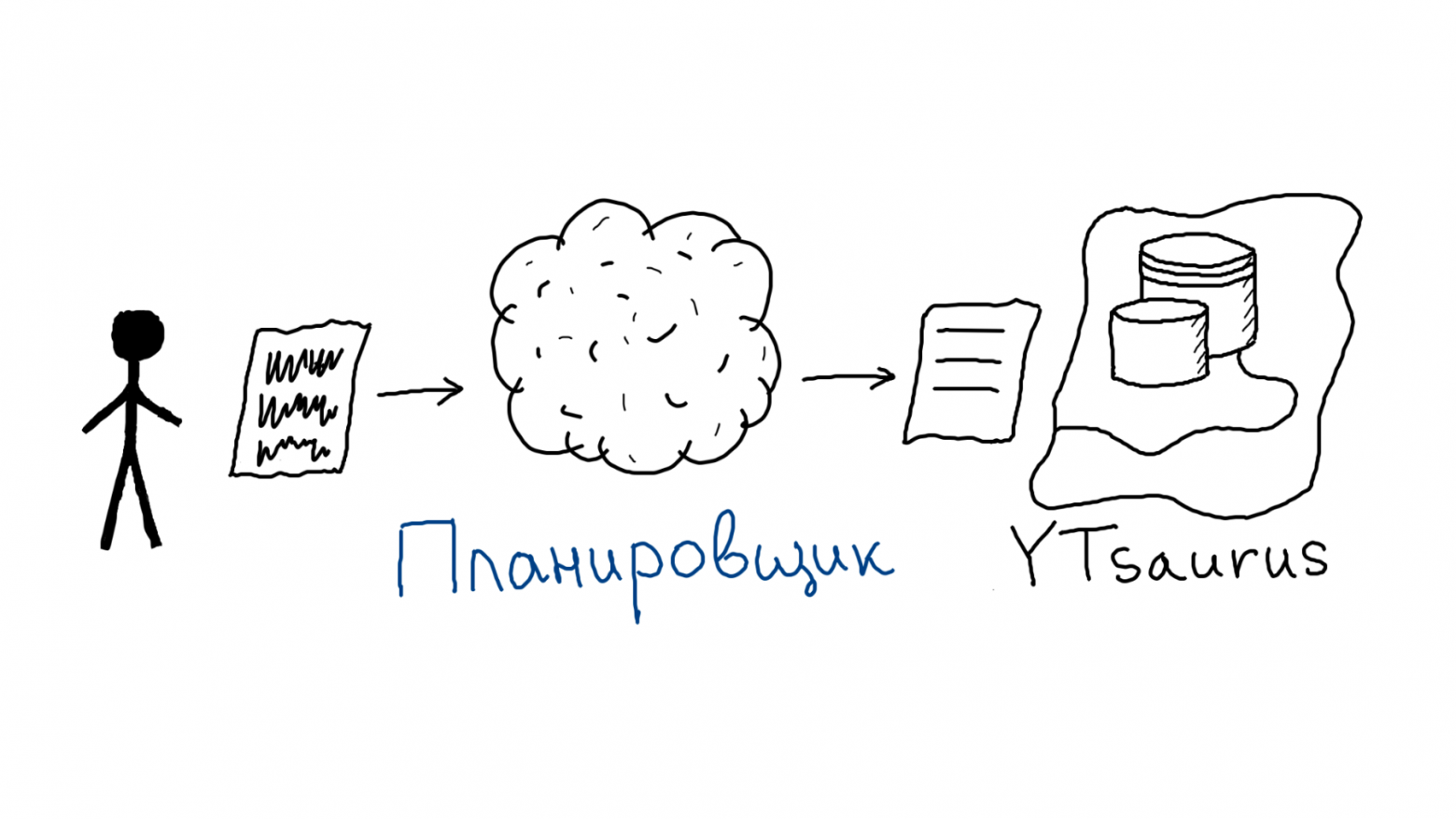
Бывало у вас так, что некоторые аналитики запрашивают побольше вычислительных ядер и оперативной памяти для своих Jupyter-ноутбуков, а у вас в это время ничего не работает? У меня бывало, ведь недостаточно уметь разрабатывать код на Spark — еще нужно уметь его настраивать, правильно инициализировать сеансы работы и эффективно управлять доступом к вычислительным ресурсам. Если отдать настройку на волю случая, Spark может (и будет) потреблять ресурсы всего кластера, а другие приложения будут стоять в очереди.
Меня зовут Владислав, я работаю Дата инженером в Альфа-Банке, и в этой статье мы поговорим о том, как правильно подобрать необходимое количество параметров и не положить кластер на коленочки.