Хабр, привет. Перевел пост, который идёт строго (!) в закладки и передаётся коллегам. Он со списком блокнотов и библиотек ML и Data Science для разных отраслей промышленности. Все коды на Python, и размещены на GitHub. Они будут полезны как для расширения кругозора, так и для запуска своего интересного стартапа.

Отмечу, что если среди читателей есть желающие помочь, и добавить в любую из подотраслей подходящий проект, пожалуйста, свяжитесь со мной. Я их добавлю в список. Итак, давайте начнём изучение списка.
Отмечу, что если среди читателей есть желающие помочь, и добавить в любую из подотраслей подходящий проект, пожалуйста, свяжитесь со мной. Я их добавлю в список. Итак, давайте начнём изучение списка.

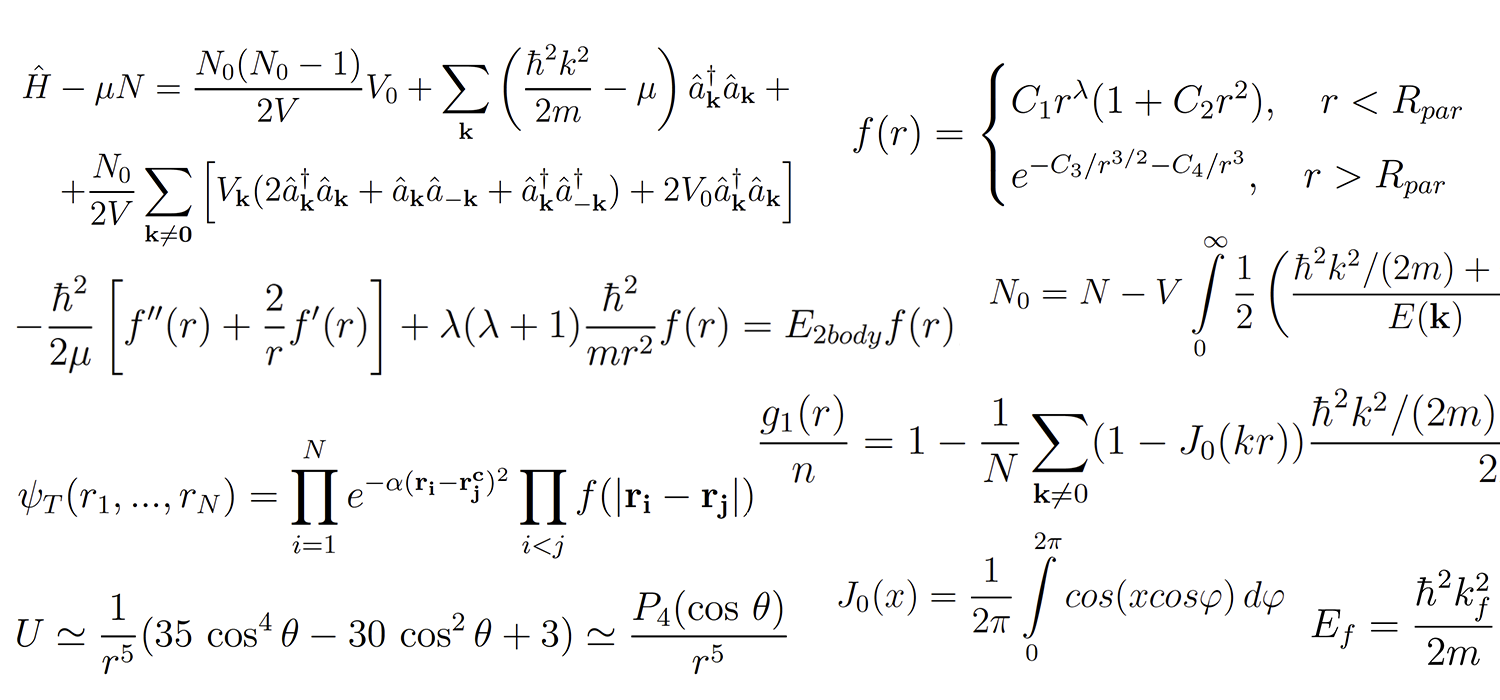
 В институтах студентов учат интегрировать аналитически, а потом обнаруживается, что на практике интегралы почти все считают численными методами. Ну или по крайней мере проверяют таким образом аналитическое решение.
В институтах студентов учат интегрировать аналитически, а потом обнаруживается, что на практике интегралы почти все считают численными методами. Ну или по крайней мере проверяют таким образом аналитическое решение.