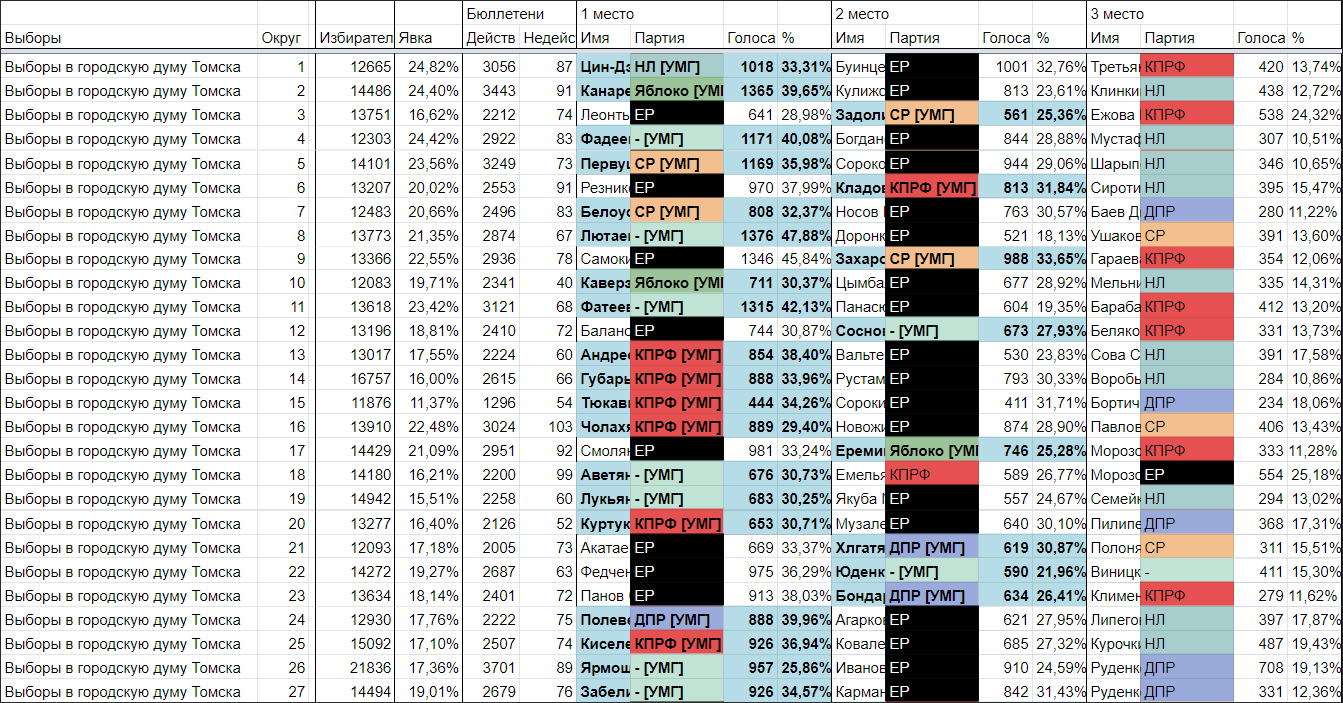
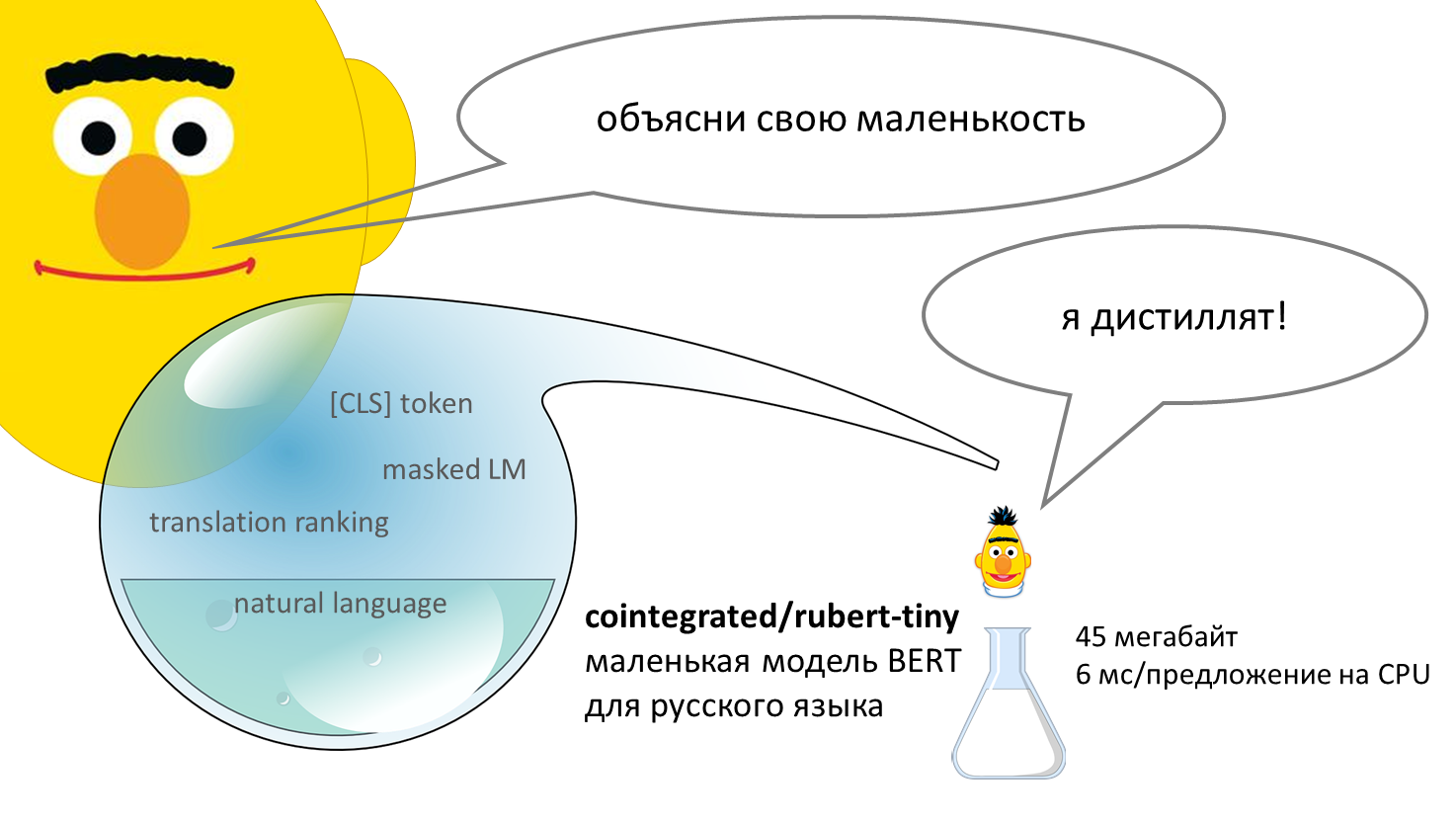
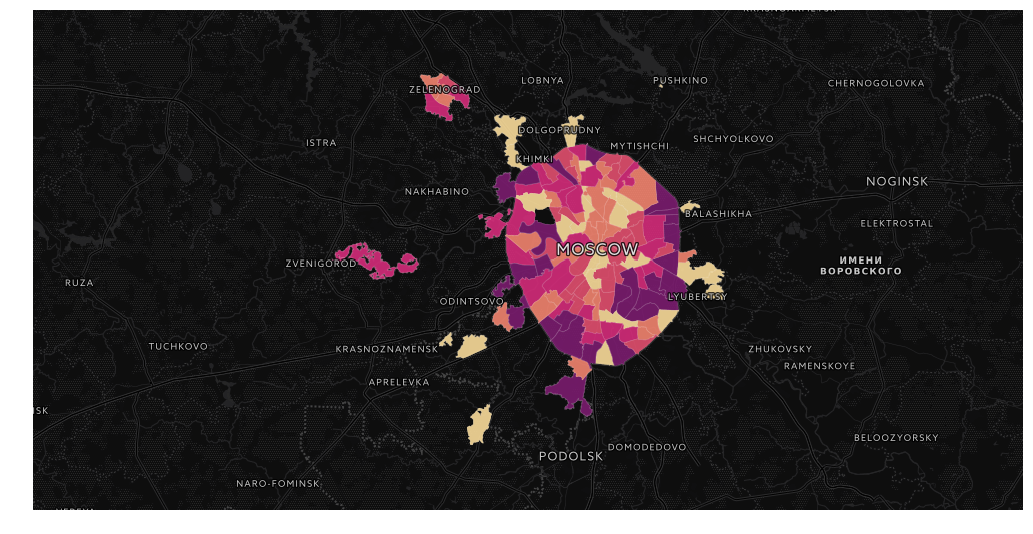
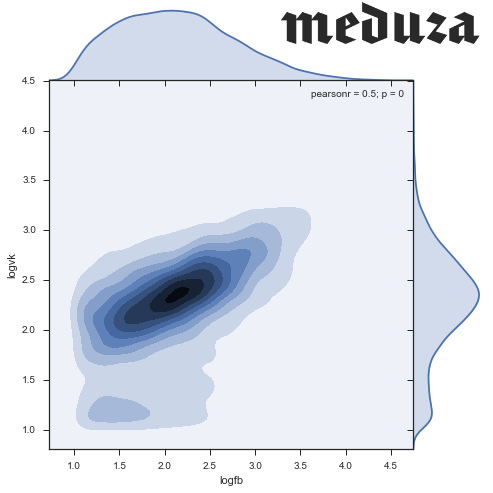
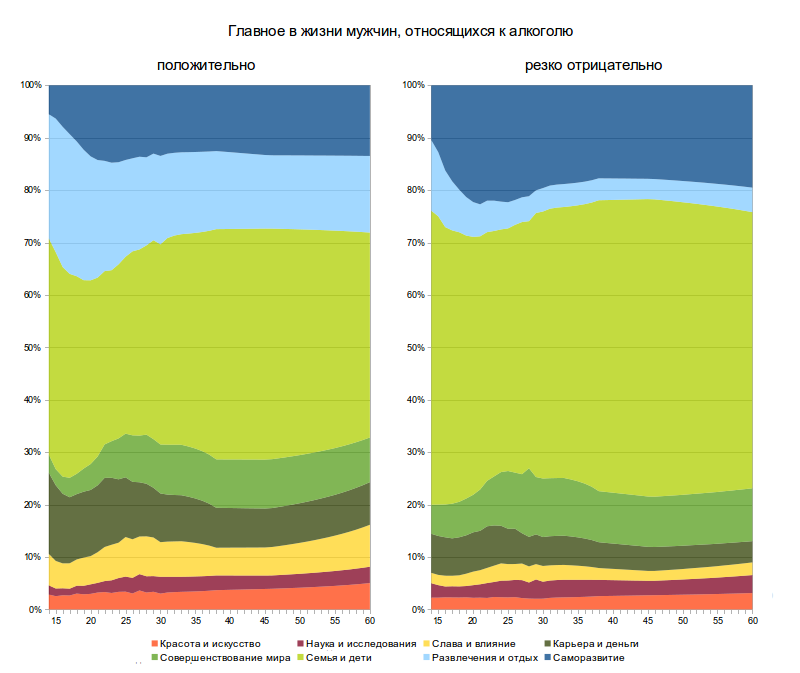
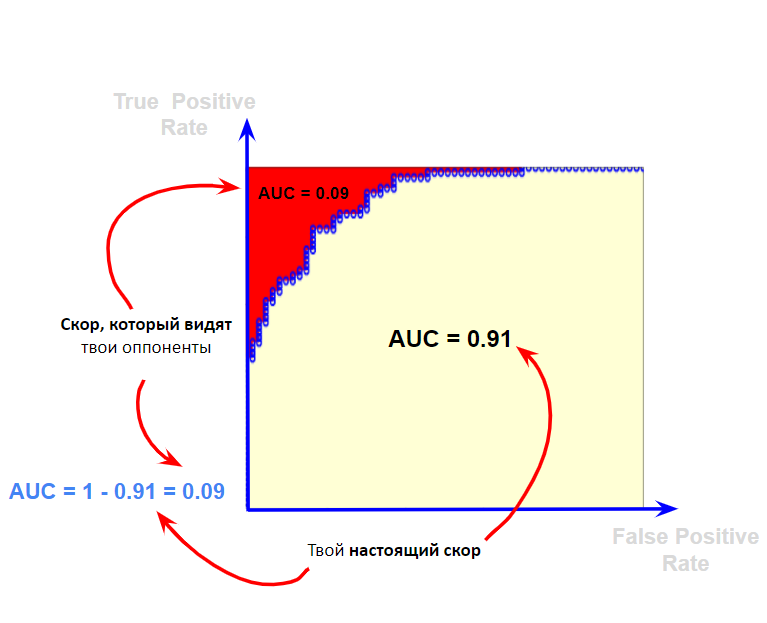
Меня зовут Пётр Ромов, я — data scientist в Yandex Data Factory. В этом посте я предложу сравнительно простой и надежный способ начать карьеру аналитика данных.
Многие из вас наверняка знают или хотя бы слышали про Kaggle. Для тех, кто не слышал: Kaggle — это площадка, на которой компании проводят конкурсы по созданию прогнозирующих моделей. Её популярность столь велика, что часто под «кэглами» специалисты понимают сами конкурсы. Победитель каждого соревнования определяется автоматически — по метрике, которую назначил организатор. Среди прочих, Kaggle в разное время опробовали Facebook, Microsoft и нынешний владелец площадки — Google. Яндекс тоже несколько раз отметился. Как правило, Kaggle-сообществу дают решать задачи, довольно близкие к реальным: это, с одной стороны, делает конкурс интересным, а с другой — продвигает компанию как работодателя с солидными задачами. Впрочем, если вам скажут, что компания-организатор конкурса задействовала в своём сервисе алгоритм одного из победителей, — не верьте. Обычно решения из топа слишком сложны и недостаточно производительны, а погони за тысячными долями значения метрики не настолько и нужны на практике. Поэтому организаторов больше интересуют подходы и идейная часть алгоритмов.

Kaggle — не единственная площадка с соревнованиями по анализу данных. Существуют и другие: DrivenData, DataScience.net, CodaLab. Кроме того, конкурсы проводятся в рамках научных конференций, связанных с машинным обучением: SIGKDD, RecSys, CIKM.
Для успешного решения нужно, с одной стороны, изучить теорию, а с другой — начать практиковать использование различных подходов и моделей. Другими словами, участие в «кэглах» вполне способно сделать из вас аналитика данных. Вопрос — как научиться в них участвовать?
Многие из вас наверняка знают или хотя бы слышали про Kaggle. Для тех, кто не слышал: Kaggle — это площадка, на которой компании проводят конкурсы по созданию прогнозирующих моделей. Её популярность столь велика, что часто под «кэглами» специалисты понимают сами конкурсы. Победитель каждого соревнования определяется автоматически — по метрике, которую назначил организатор. Среди прочих, Kaggle в разное время опробовали Facebook, Microsoft и нынешний владелец площадки — Google. Яндекс тоже несколько раз отметился. Как правило, Kaggle-сообществу дают решать задачи, довольно близкие к реальным: это, с одной стороны, делает конкурс интересным, а с другой — продвигает компанию как работодателя с солидными задачами. Впрочем, если вам скажут, что компания-организатор конкурса задействовала в своём сервисе алгоритм одного из победителей, — не верьте. Обычно решения из топа слишком сложны и недостаточно производительны, а погони за тысячными долями значения метрики не настолько и нужны на практике. Поэтому организаторов больше интересуют подходы и идейная часть алгоритмов.
Kaggle — не единственная площадка с соревнованиями по анализу данных. Существуют и другие: DrivenData, DataScience.net, CodaLab. Кроме того, конкурсы проводятся в рамках научных конференций, связанных с машинным обучением: SIGKDD, RecSys, CIKM.
Для успешного решения нужно, с одной стороны, изучить теорию, а с другой — начать практиковать использование различных подходов и моделей. Другими словами, участие в «кэглах» вполне способно сделать из вас аналитика данных. Вопрос — как научиться в них участвовать?

 В пятничном номере NY Times опубликована
В пятничном номере NY Times опубликована 
 Это реальная история. События, о которых рассказывается в посте, произошли в одной теплой стране в 21ом веке. На всякий случай имена персонажей были изменены. Из уважения к профессии всё рассказано так, как было на самом деле.
Это реальная история. События, о которых рассказывается в посте, произошли в одной теплой стране в 21ом веке. На всякий случай имена персонажей были изменены. Из уважения к профессии всё рассказано так, как было на самом деле.