
Чтобы обучать нейросети понимать и генерировать человеческие языки, нужно много качественных текстов на нужных языках. «Много» – не проблема в эпоху интернета, но с качеством бывают сложности. В этом посте я предлагаю использовать BERT-подобные модели для двух задач улучшения качества обучающих текстов: исправление ошибок распознавания текста из сканов и фильтрация параллельного корпуса предложений. Я испробовал их на башкирском, но и для других языков эти рецепты могут оказаться полезны.
Mini-ml-stand для бедных
Простой
17 мин
Туториал

Всем привет! Снова на связи General RJ45 с новым прекрасным решением, но на сей раз по теме ML и аналитики.
На моем счету уже два законченных ML проекта и за это время я достаточно много поработал с аналитиками и ML инженерами, да и вообще над созданием ML и аналитических решений и могу сказать что у меня сформировалось своё представление о данных решения и я вижу какие проблемы возникают в данных процессах и что нужно разработчикам для их более эффективной работы, как пример это прозрачность всего процесса чтобы они могли видеть весь процесс от начала до конца и контролировать его.
В рамках данной статьи хочу рассказать как можно максимально просто поднять ML стенд на котором можно будет вести полноценную разработку и ETL процессов, и различных обучений моделей и их переобучений.
Стек того что мы поднимем в рамках этой статьи, также будут и другие инструменты как Nginx, Postgresql но мы их учитываем как часть компонентов ниже:
Анализировать данные — это как варить пиво. Почему дата-анализ и пивоварение — одно и то же с техноизнанки
10 мин

Три года я был эстонским пивоваром: придумывал рецепты и сам варил. Когда начал изучать Python, SQL и анализ данных, понял, что между подготовкой данных и подготовкой сусла много общего: оказывается, в цеху я занимался DS, но не подозревал об этом. Меня зовут Алексей Гаврилов, я сеньор дата-аналитик в ретейле. В этой статье расскажу, чем пивоварение и аналитика данных похожи изнутри.
Как Почта моделирует риски потери отправлений
Средний
7 мин
Кейс

Привет! Я Кирилл Мамонов, главный аналитик отдела монетизации данных в Почтатехе. Расскажу, как мы создали модель, которая предсказывает до 97% возможных пропаж международных отправлений.
Готовы ли вы к прозрачности мозга: корпорации готовятся залезть в головы работников
15 мин
Аналитика

В начале этого года на Всемирном экономическим форуме в Давосе прозвучала презентация профессора Ниты Фарахани о том, как возможности современных датчиков мозговой активности для контроля за сотрудниками могут изменить рабочие места. ИИ позволяет расшифровывать мозговую активность способами, которые раньше не представлялись возможными: носимые датчики (наушники, повязки, миниатюрные наклейки, которые можно спрятать за ухом) могут определять эмоциональное состояние человека; замечать и расшифровывать лица, которые он видит; расшифровывать простые геометрические формы, цифры, ПИН-коды; наручные датчики вроде часов позволяют расшифровывать сигналы на какие нажимать клавиши.
В ходе презентации профессор пыталась вывести на первый план пользу отслеживающих мозговую активность устройств для ментального и физического здоровья сотрудников, рисуя картины контроля за своим состоянием и детектирования любых тревожных звоночков для обращения к врачу. Но даже бизнес-аудитория главного экономического форума планеты прозвучала смятённо, когда в завершение своего выступления профессор Фарахани обратилась к залу с вопросом: «готовы ли вы к этому будущему?»
Определение свободного парковочного места с помощью Computer Vision
Средний
8 мин

Всем привет! Это моя первая статья на Хабр (поэтому не судите строго).
Дело было так: смотрел я как-то в окно и увидел, как человек сидит в машине на парковке и ждет, когда освободится парковочное место. Бывает, что и я сижу в машине и жду, когда же можно будет припарковать своего верного коня. И тут я подумал, а почему бы не подключить Компьютерное Зрение для этого? Зачем я учился разработке нейросетей, если не могу заставить компьютер работать вместо меня?
Изначально идея заключалась в следующем: Модель на базе компьютерного зрения должна через веб-камеру, установленную дома, отслеживать освободившиеся места на парковке и информировать через telegram-бота если такое место появится. Работать будем на Python.
Итак, ТЗ для меня от меня сформулировано, теперь за дело!
Первое с чем необходимо было определиться, это решить, какую модель детектирования объектов использовать. Сначала мой выбор пал на Fast R-СNN. Модель показывала хорошее качество детектирования. Однако после нескольких дней прокрастинации обдумывания реализации я решил воспользоваться более современными и интересными методами и подключить детектор от YOLO (взял не самую новую 4 версию).
Что нам стоит диаграмму в Python построить: 5 вариантов привлекающей внимание визуализации данных и кое-что ещё
6 мин

Диаграммы помогают визуализировать как простые, так и самые сложные наборы данных. При этом диаграмм — множество видов, у каждого есть свои достоинства и недостатки. О наиболее эффектных и эффективных, реализуемых с Python, мы решили рассказать в сегодняшней подборке. Если вам интересна эта тема – просим под кат. А если у вас есть собственные предпочтения среди графиков (или вы используете что-то ещё), то пишите в комментариях, обсудим. Что же – поехали!
Slovo и русский жестовый язык
Средний
10 мин

Всем привет! В этой статье мы расскажем о непростой задаче распознавания русского жестового языка (РЖЯ) для слабослышащих. Насколько нам известно, в открытом доступе не существует универсального набора данных для распознавания РЖЯ. Поэтому мы решили выложить небольшую часть нашего датасета в открытый доступ. В статье мы затронем основные особенности РЖЯ, поговорим о проблемах и сложностях самого языка, и процессе его сбора и разметки. Расскажем, где искали экспертов и как нам в итоге удалось собрать самый большой и разнородный жестовый датасет для РЖЯ. В конце статьи представим набор предобученных нейронных сетей и небольшое приложение, демонстрирующее распознавание жестового языка. Часть датасета и веса моделей мы выложили в открытый доступ — все ссылки вы можете найти в конце статьи или в нашем репозитории.
Чисто научный подход: чего хотят женщины и о чем говорят мужчины
Простой
8 мин

Женщины сами не знают, что хотят, а мужчины говорят о работе. И мои слова - это не стереотипное мышление, а обоснованное на данных заявление. По крайней мере, на основе данных 240 тысяч анкет женщин и мужчин, которые я спарсила с сайта mamba.ru, а потом “разложила по графичкам”. Цель была - сформировать портреты пользователей, но и плюсом пришла к приятному и немного трогательному выводу.
Особенности прогнозирования продаж и оттока в условиях неопределенности
14 мин
Кейс

Бизнес в современных условиях развивается стремительно. На динамику продаж, доходов, расходов оказывает влияние множество различных факторов, как внутренних (инвестиции, стимулирование отдельных каналов продаж, исследование рынка и т.п.), так и внешних – различные непредвиденные обстоятельства, вроде, пандемий, стихийных бедствий, исторические событий.
Такие общемировые события вносят свои коррективы в развитие бизнеса и оказывают влияние как в краткосрочном, так и в долгосрочном периоде. Для аналитиков подобные внешние факторы оказываются часто более значимыми, чем внутренние, поскольку наступление данных событий всегда означает крушение привычных тенденций. А это осложняет прогнозирование, заставляет отказываться от привычных моделей и искать новые подходы.
С 2015 по 2021 годы я работала в дирекции по продажам конвергентных продуктов Билайн аналитиком, можно сказать, «на все руки» – аналитиком продаж, продуктовым, финансовым. В мою зону ответственности входили операционная и ежемесячная отчетность, расчет планов продаж на квартал, бюджетирование расходов на продажи, расчеты кейсов по инициативам – для всего этого требовалось моделирование основных KPI развития бизнеса.
Меня зовут Нина Фещенко, с 2022 года в департаменте аналитики розничного бизнеса (B2C) я в большей степени занимаюсь работой с данными и BI-аналитикой, но без моделирования тоже не обходится. В этом посте я опишу свой опыт построения модели прогнозирования продаж конвергентных продуктов (2019-2021), а также прогнозирования оттока мобильных абонентов в 2022 году. Расскажу, как работала модель в относительно стабильный период до 2020-го года, и какие корректировки пришлось внести впоследствии.
Анализ таблиц сопряженности средствами Python. Часть 1. Визуализация
43 мин
Туториал
Категориальные данные имеет огромное значение в DataScience. Как справедливо заметили авторы в [1], мы живем в мире категорий: информация может быть сформирована в категориальном виде в самых различных областях - от диагноза болезни до результатов социологического опроса.
Частным случаем анализа категориальных данных является анализ таблиц сопряженности (contingency tables), в которые сводятся значения двух или более категориальных переменных.
Однако, прежде чем написать про статистический анализ таблиц сопряженности, остановимся на вопросах их визуализации. Казалось бы, об этом уже написано немало - есть статьи про графические возможности python, есть огромное количество информации и примеров с программным кодом. Однако, как всегда имеются нюансы - в процессе исследования возникают вопросы как с выбором средств визуализации, так и с настройкой инструментов python. В общем, есть о чем поговорить...
В данном обзоре мы рассмотрим следующие способы визуализации таблиц сопряженности.
PySpark для аналитика. Как правильно просить ресурсы и как понять, сколько нужно брать
9 мин

Александр Ледовский, тимлид команды аналитики и DS в Авито, рассказал про опыт работы с Apache Spark и о том, как правильно задавать параметры Spark-сессии, чтобы получить ресурсы.
Применение методов CRISP-DM для анализа Big Sales Data
Простой
5 мин
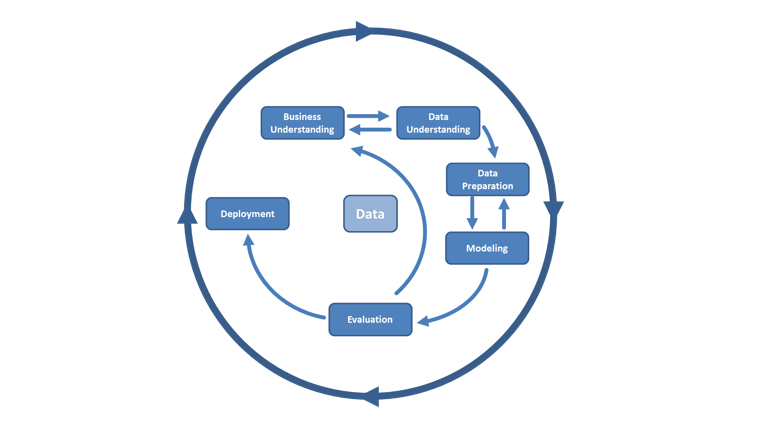
Метод обработки данных, полученных в процессе продажи людьми (звонки/встречи), с целью оптимизации воронки, сокращения цикла сделки и увеличения конверсии.
Ближайшие события






Firebird Conf: конференция для разработчиков и администраторов СУБД Firebird
6 июня
09:00 – 20:00
Москва

EasyPortrait — портретная сегментация и анализ лиц
Средний
9 мин

Всем привет! Наверняка, кто-то из вас уже пользовался сервисом видеоконференций SberJazz. Мы в нашей RnD команде решили помочь ребятам с задачей замены фона, для чего создали подходящий датасет и провели ряд исследований в направлении удаления фона (background removal). На этом мы не остановились и разметили данные для задачи анализа лица (face parsing). Это позволит пользователям применять эффекты бьютификации: сглаживание кожи, изменение размера и цвета губ или глаз, отбеливание зубов и т. д.
В данной статье мы расскажем о новом наборе данных EasyPortrait, опишем процесс его создания от идеи до разметки, и представим обученные на нем нейронные сети. Датасет и веса моделей мы выложили в открытый доступ — ссылки лежат в конце статьи и в нашем репозитории.
Алгоритм, сделавший ChatGPT таким «человечным» — Reinforcement Learning from Human Feedback
8 мин

ChatGPT генерирует разнообразный и привлекательный для человека текст. Но что делает текст «хорошим»? Это субъективно и зависит от контекста. Например, если вы попросите сочинить историю, нужен творческий подход. Если вы запрашиваете информацию, то хотите, чтобы она была правдивой. А если вы просите написать код, то ожидаете, что он будет исполняемым.
Вы наверняка слышали о том, что OpenAI привлекали сотрудников из Африки для помощи в разметке токсичности их ассистента. Менее известен факт найма реальных разработчиков, чтобы подготовить данные с пояснениями к коду на человечском языке.
Именно данные с фидбеком от людей позволили дообучить их языковую модель и сделать продукт таким «человечным».
Разберем алгоритм, который позволяет согласовать модель машинного обучения со сложными человеческими ценностями.
ARRS // Нам нужна ваша помощь
Простой
3 мин

Русскоязычное Комьюнити Escape From Tarkov обращается к дешифровщикам и криптографам за помощью в дешифровке изображений из игры альтернативной реальности ARRS терминал.
Текущий процесс дешифровки силами энтузиастов из комьюнити зашёл в тупик.
Регрессионный анализ в DataScience. Часть 3. Аппроксимация
Средний
72 мин
Туториал
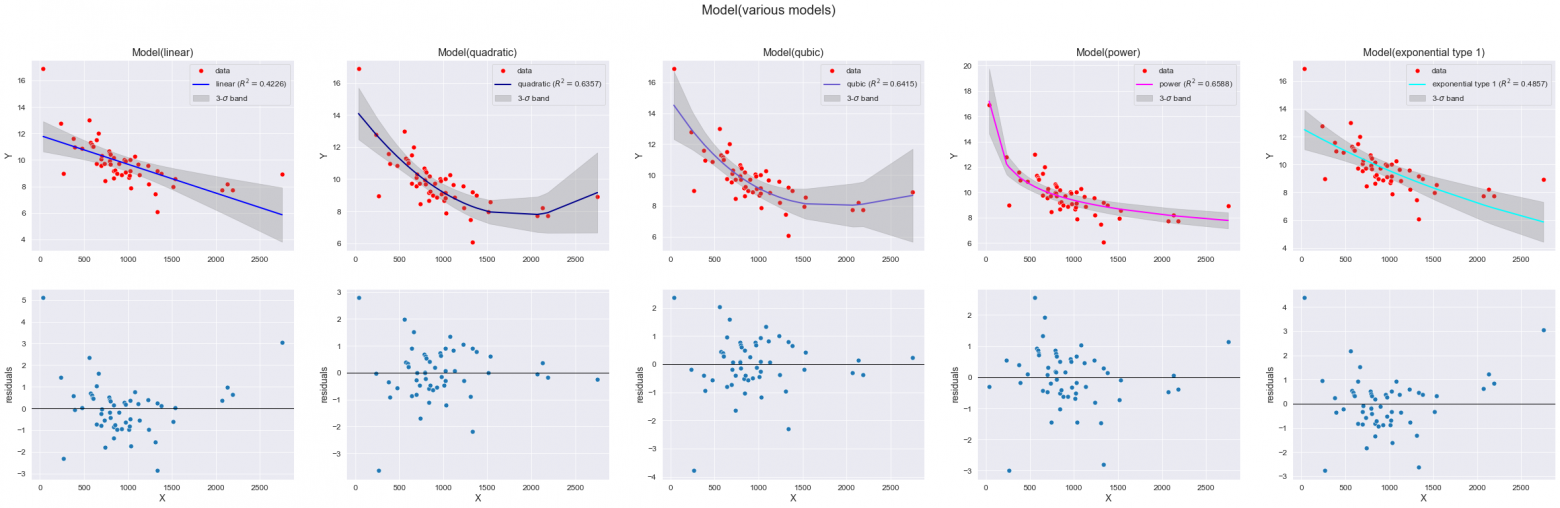
В предыдущих обзорах (https://habr.com/ru/articles/690414/, https://habr.com/ru/articles/695556/) мы рассматривали линейную регрессию. Пришло время переходить к нелинейным моделями. Однако, прежде чем рассматривать полноценный нелинейный регрессионный анализ, остановимся на аппроксимации зависимостей.
Про аппроксимацию написано так много, что, кажется, и добавить уже нечего. Однако, кое-что добавить попытаемся.
При выполнении анализа данных может возникнуть потребность оперативно построить аналитическую зависимость. Подчеркиваю - речь не идет о полноценном регрессионном анализе со всеми его этапами, проверкой гипотез и т.д., а только лишь о подборе уравнения и оценке ошибки аппроксимации. Например, мы хотим оценить характер зависимости между какими-либо показателями в датасете и принять решение о целесообразности более глубокого исследования. Подобный инструмент предоставляет нам тот же Excel - все мы помним, как добавить линию тренда на точечном графике:
Пара вопросов к мерчандайзерам «Леруа Мерлен»
Простой
3 мин
Аналитика

Письмо на Балабановскую спичечную фабрику:
«Я 11 лет считаю спички у вас в коробках — их то 59, то 60, а иногда и 58. Вы там сумасшедшие что ли все???»
Периодически задаюсь вопросом "ящик каких батареек купить в этом году". И поэтому являюсь давним поклонником исследований-сравнений разных элементов питания, наиболее известные и масштабные из которых — за авторством Алексея Надежина (@AlexeyNadezhin).
А работают ли игровые механики?
Простой
10 мин
Кейс

Этот вопрос мне задают постоянно.
Привет, Хабр! Меня зовут Тагир Хайрутдинов, я старший аналитик данных в Альфа-Банке. За прошлый год я посетил примерно 10 профильных конференций и прочих мероприятий. Когда на мероприятиях я рассказываю людям о том, что такое геймификация и какое влияние она оказывает на бизнес на примере проектов Альфы, то самый частый вопрос от маркетологов, овнеров, аналитиков и прочих — «А это реально работает?»
Да, геймификация действительно работает. Об этом и пойдет сегодня речь — я расскажу, что такое геймификация, какой эффект от неё получает бизнес и как мы используем игровые механики в Альфе. Делать я это буду на примере игры «Симулятор мошенника», в которой мы предлагали клиентам в форме игры проверить своё умение распознавать мошенников. Статья будет больше интересна аналитикам, продакт овнерам, маркетологам.
Segment Anything: создание первой базисной модели для сегментации изображений
9 мин
Перевод

Сегментация, то есть распознавание пикселей изображения, принадлежащих объекту — базовая задача компьютерного зрения, используемая в широком спектре применений, от анализа научных снимков до редактирования фотографий. Однако для создания точной модели сегментации под конкретные задачи обычно требуется высокоспециализированный труд технических экспертов, имеющих доступ к инфраструктуре обучения ИИ и большим объёмам тщательно аннотированных данных, относящихся к предметной области.
Наша лаборатория Meta AI* стремится сделать сегментацию более доступной, основав проект Segment Anything: новую задачу, датасет и модель для сегментации изображений (подробности см. в нашей исследовательской статье). Мы публикуем нашу Segment Anything Model (SAM) и датасет масок Segment Anything 1-Billion mask dataset (SA-1B) (крупнейший в мире датасет сегментации), чтобы их можно было использовать во множестве разных областей и стимулировать дальнейшие исследования базисных моделей компьютерного зрения. Мы открываем доступ к датасету SA-1B, позволяя использовать его в исследовательских целях; модель Segment Anything Model доступна по открытой лицензии (Apache 2.0). Вы можете протестировать демо SAM со своими собственными изображениями.
* Принадлежит корпорации Meta Platforms, которая признана экстремистской организацией, её деятельность в России запрещена.