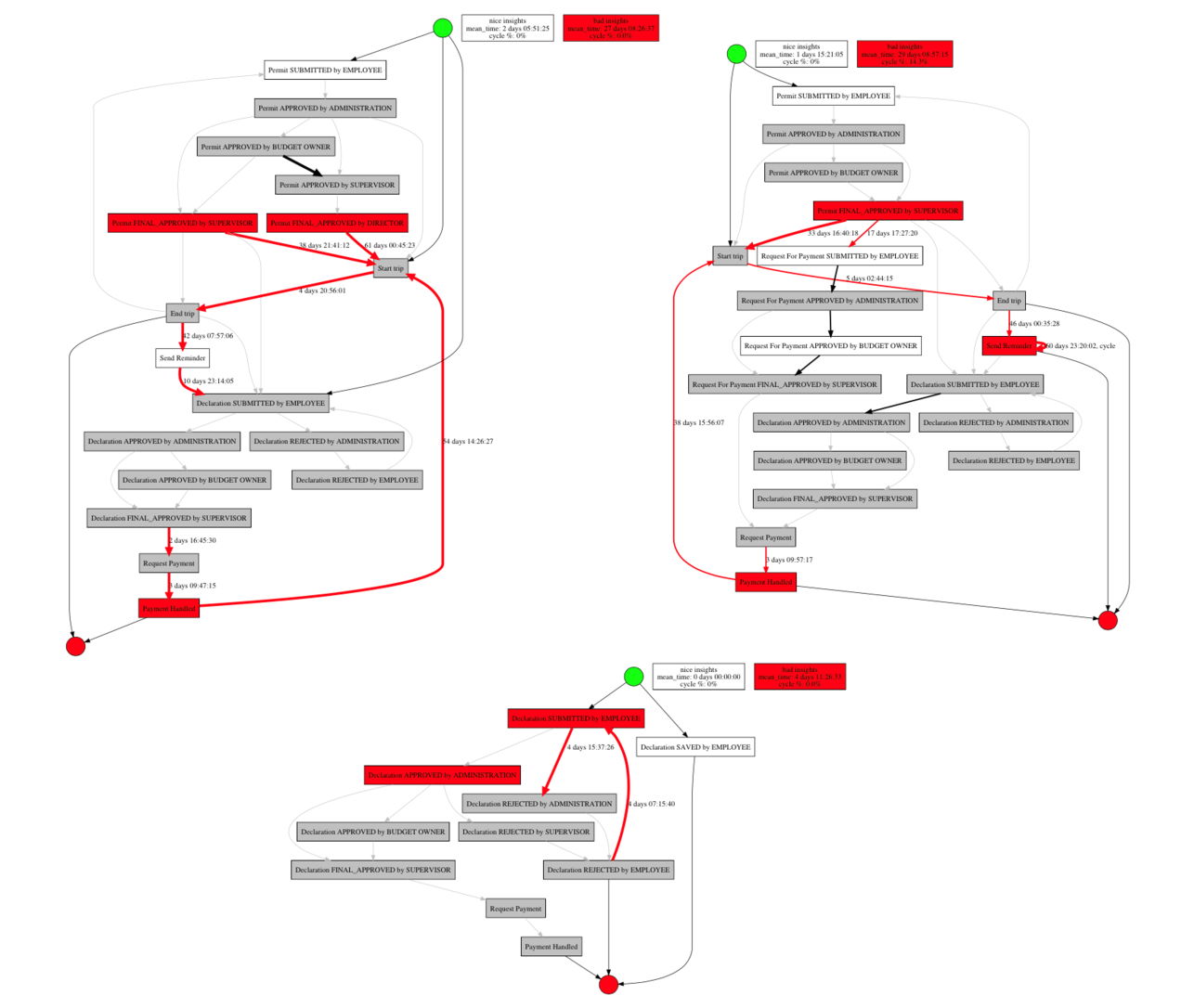
Process Mining – это мост между Data Mining и Process Management. Это подход к извлечению, анализу и оптимизации процессов на основе данных из журналов событий (event logs), доступных в информационных системах. Мы разработали и открыли библиотеку, позволяющую быстро и достаточно просто обрабатывать данные информационных систем производства, чтобы находить узкие места и точки неэффективности.
Первой научной теорией, целью которой был анализ и оптимизация рабочих процессов, является «Научное управление». На рубеже XIX – XX веков усилиями американского исследователя Фредерика Тейлора и его единомышленников была создана теория классического менеджмента. Она основывается на положении, что существует «наилучший способ» выполнения каждой конкретной работы, и проблема низкой производительности может быть решена путем использования метода, названного «научным хронометрированием». Суть метода заключается в разделении работы на последовательность элементарных операций, которые хронометрируются и фиксируются при участии рабочих. В итоге это позволяет получить точную информацию о необходимых затратах времени на выполнение той или иной работы.

Таким образом, более 120 лет назад таким простым шагом был дан старт научному подходу к исследованию процессов. С развитием общества и технологий эволюционируют и совершенствуются подходы к анализу и оптимизации процессов: происходит переход к «Массовому производству», в основе которого лежит специализация с возможностями оптимизации сборки, компьютеризации и анализа статистки.
Современный Process Mining — это эволюция этого подхода с учётом больших данных.