
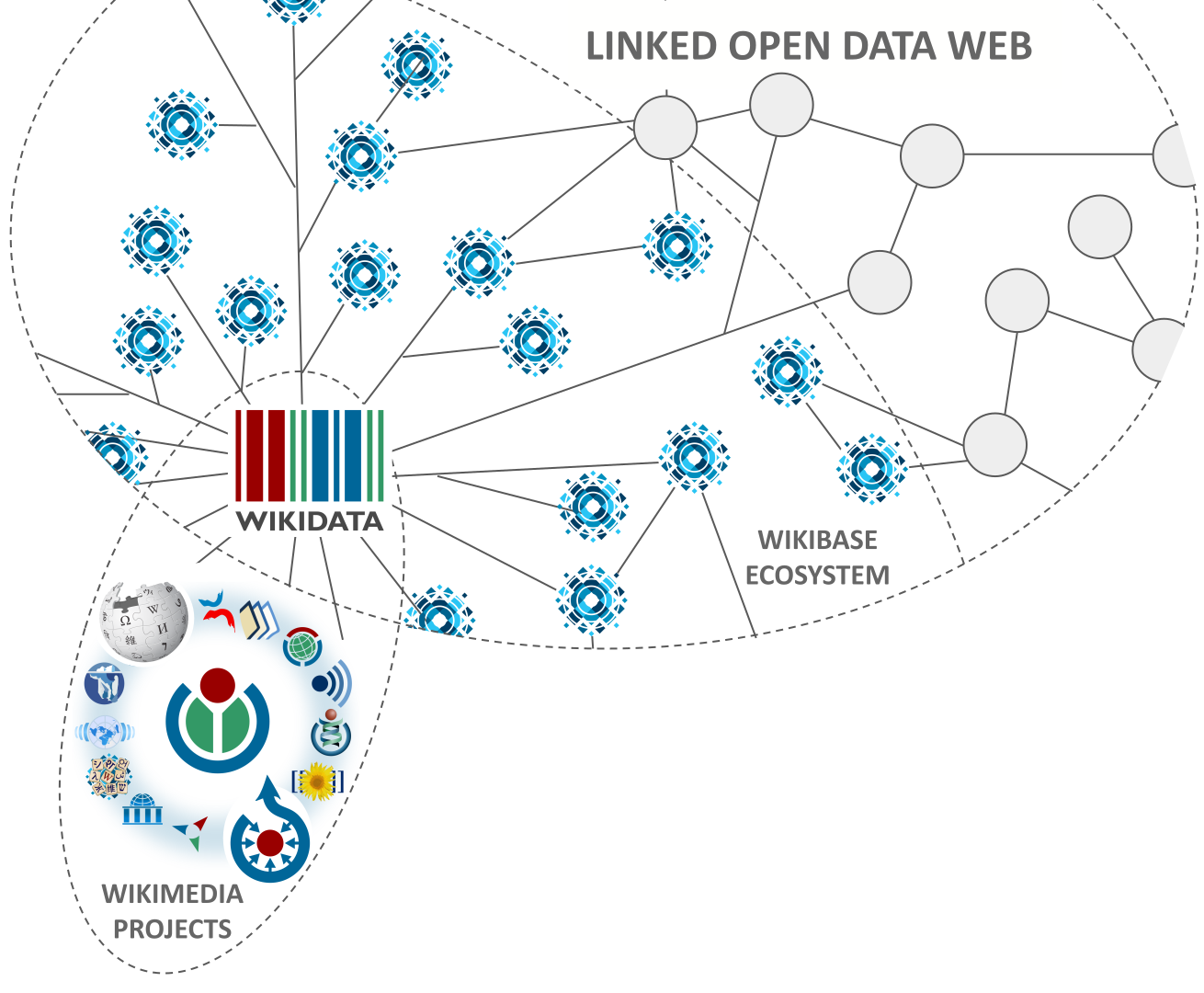
Здравствуйте, на Хабре не много о Викиданных, хочу рассказать об этом бесплатном открытом интересном и полезном сервисе. Веб интерфейс располагается по адресу https://www.wikidata.org/wiki/Wikidata:Main_Page.
Здравствуйте, на Хабре не много о Викиданных, хочу рассказать об этом бесплатном открытом интересном и полезном сервисе. Веб интерфейс располагается по адресу https://www.wikidata.org/wiki/Wikidata:Main_Page.

TL;DR В статье рассказывается о том, как мне удалось перевести чтение лент в ВКонтакте**, Telegram, Facebook*, Instagram**, Reddit и почтовых рассылок в единый сервис InoReader. Причем почти без написания своих велосипедов.
Кластеризация — это набор методов без учителя для группировки данных по определённым критериям в так называемые кластеры, что позволяет выявлять сходства и различия между объектами, а также упрощать их анализ и визуализацию. Из-за частичного сходства в постановке задач с классификацией кластеризацию ещё называют unsupervised classification.
В данной статье описан не только принцип работы популярных алгоритмов кластеризации от простых к более продвинутым, но а также представлены их упрощённые реализации с нуля на Python, отражающие основную идею. Помимо этого, в конце каждого раздела указаны дополнительные источники для более глубокого ознакомления.

Привет, Хабр! Меня зовут Иван Антипов, я занимаюсь ML в команде матчинга Ozon. Наша команда разрабатывает алгоритмы поиска одинаковых товаров на сайте. Это позволяет покупателям находить более выгодные предложения, экономя время и деньги.
В этой статье мы обсудим кластеризацию на графах, задачу выделения сообществ, распад карате-клуба, self-supervised и unsupervised задачи — и как всё это связано с матчингом.
Анализ системы защиты сайта от ботов на примере letu.ru с использованием javascript reverse engineering.
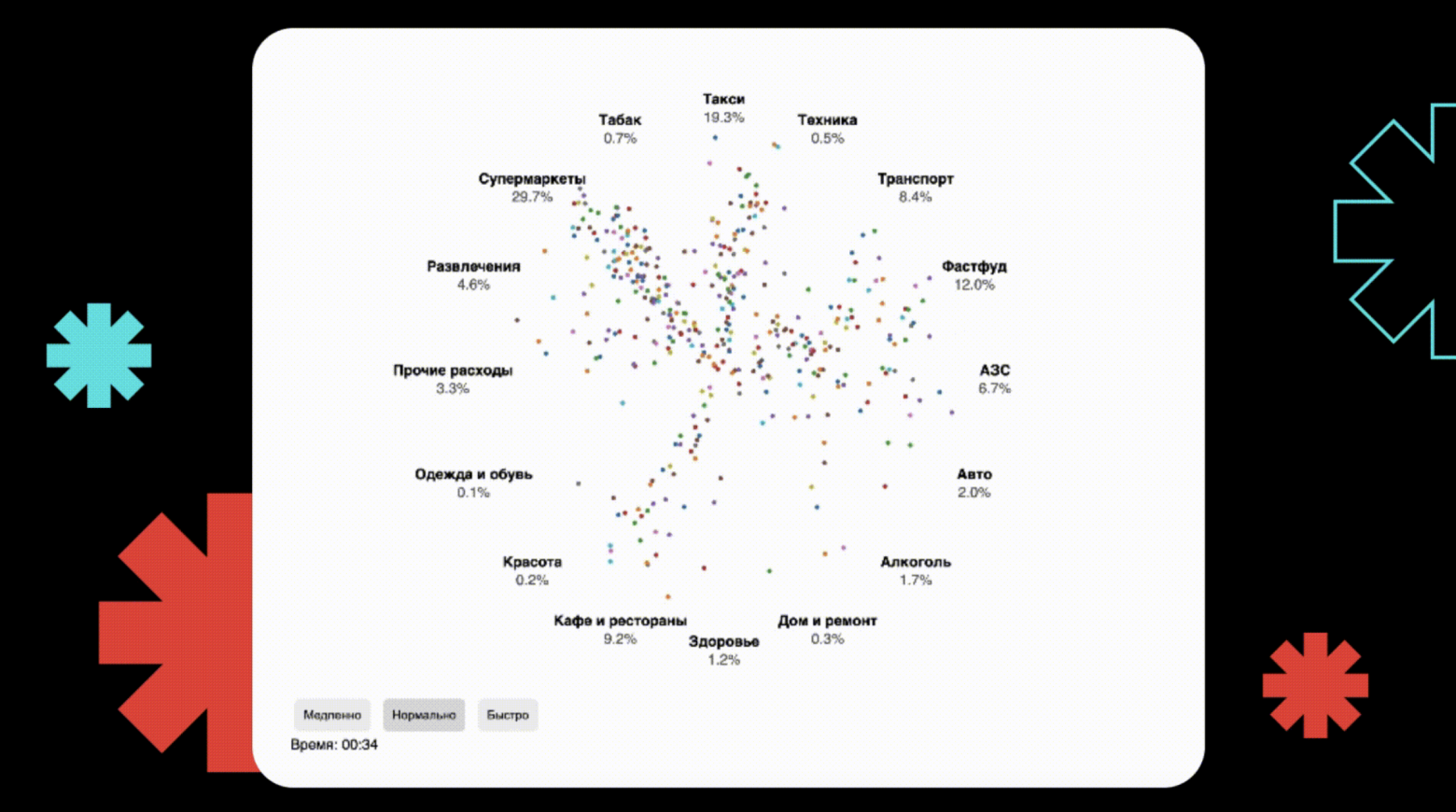
Привет, Хабр! Меня зовут Тагир, я занимаюсь аналитикой игровых механик. Недавно я наткнулся на статью, в которой визуализировали жизни тысяч людей с точностью до минуты — люди отмечали, на что они тратят свое время в течение дня, а автор агрегрировал эти данные и сделал визуализацию, разбив активности по категориям.
Я переложил эту логику на банковские транзакции, чтобы посмотреть, на что люди тратят свои деньги в определенный момент времени, и получил статистику, о которой все и так вроде бы знают. На обед люди ходят в ближайшее кафе и заправляют машину, после работы — в супермаркет, а на выходных — отдыхают в увеселительных заведениях. Но визуализировав эти данные, увидел, что выглядит это весьма залипательно.

В первой части статьи я рассказывал о создании цифрового юриста, способного отвечать на вопросы на основе 200-страничного регламента. Цель — работа такого юриста в закрытом контуре организации, без использования облачных технологий.
Особенностью эксперимента является в том, что оценку ответов делают обычные люди. Юристы.
Во второй части мы рассмотрим как и зачем делать локальные токензайзеры и попробуем запустить всё полностью на локальной машине с видеокартой 4090.
В конце будет приведена полная сравнительная таблица разных моделей и токензайзеров.

Принятие решений на основе данных является неотъемлемой частью работы аналитика. Данные помогают сделать это быстро. Но что если объём данных достигает десятков петабайт? Подобная задача становится не такой тривиальной, как может показаться на первый взгляд. Как масштабировать работу с данными в продуктовых командах? Как быстро найти инсайты в куче данных? Какие инструменты могут быть полезны для аналитика?
Заинтригованы? Добро пожаловать в мир аналитики больших данных.


«Пять глаз», «Девять глаз» и «Четырнадцать глаз» — это реально существующие международные альянсы по массовому наблюдению, включающие в себя, соответственно, 5, 9 и 14 западных стран, а также партнёрские страны-сателлиты. На основе соглашений в основе этих альянсов, спецслужбы развитых стран образуют единую машину слежения и контроля практически за любой коммуникационной активностью людей в их странах и по всему миру, включая все виды онлайн-коммуникаций.
Корнями эти альянсы уходят к секретному соглашению США и Великобритании об обмене сигнальной разведкой между странами-союзниками в годы Холодной войны. Это соглашение оставалось секретом для общественности до 2005 года, потому что один из методов альянса — помощь спецслужб друг другу в обходе законов своих стран: если законы одной страны не позволяют спецслужбам копаться в интернет-делах своих граждан, то выполнить грязную работу для них могут коллеги из другой страны. Например, спецслужбы Великобритании попались на использовании возможностей американского Агентства национальной безопасности (АНБ) для сбора данных о жителях Соединенного Королевства.
Сегодня мы расскажем о том, устроен этот международный шпионский «коллаб», почему беспочвенны обещания VPN-реклам помочь избежать попадания под этот глобальный колпак, и что про это нужно знать обычным пользователям VPN и интернета.

Три года я был эстонским пивоваром: придумывал рецепты и сам варил. Когда начал изучать Python, SQL и анализ данных, понял, что между подготовкой данных и подготовкой сусла много общего: оказывается, в цеху я занимался DS, но не подозревал об этом. Меня зовут Алексей Гаврилов, я сеньор дата-аналитик в ретейле. В этой статье расскажу, чем пивоварение и аналитика данных похожи изнутри.

В начале этого года на Всемирном экономическим форуме в Давосе прозвучала презентация профессора Ниты Фарахани о том, как возможности современных датчиков мозговой активности для контроля за сотрудниками могут изменить рабочие места. ИИ позволяет расшифровывать мозговую активность способами, которые раньше не представлялись возможными: носимые датчики (наушники, повязки, миниатюрные наклейки, которые можно спрятать за ухом) могут определять эмоциональное состояние человека; замечать и расшифровывать лица, которые он видит; расшифровывать простые геометрические формы, цифры, ПИН-коды; наручные датчики вроде часов позволяют расшифровывать сигналы на какие нажимать клавиши.
В ходе презентации профессор пыталась вывести на первый план пользу отслеживающих мозговую активность устройств для ментального и физического здоровья сотрудников, рисуя картины контроля за своим состоянием и детектирования любых тревожных звоночков для обращения к врачу. Но даже бизнес-аудитория главного экономического форума планеты прозвучала смятённо, когда в завершение своего выступления профессор Фарахани обратилась к залу с вопросом: «готовы ли вы к этому будущему?»

Всем привет! Это моя первая статья на Хабр (поэтому не судите строго).
Дело было так: смотрел я как-то в окно и увидел, как человек сидит в машине на парковке и ждет, когда освободится парковочное место. Бывает, что и я сижу в машине и жду, когда же можно будет припарковать своего верного коня. И тут я подумал, а почему бы не подключить Компьютерное Зрение для этого? Зачем я учился разработке нейросетей, если не могу заставить компьютер работать вместо меня?
Изначально идея заключалась в следующем: Модель на базе компьютерного зрения должна через веб-камеру, установленную дома, отслеживать освободившиеся места на парковке и информировать через telegram-бота если такое место появится. Работать будем на Python.
Итак, ТЗ для меня от меня сформулировано, теперь за дело!
Первое с чем необходимо было определиться, это решить, какую модель детектирования объектов использовать. Сначала мой выбор пал на Fast R-СNN. Модель показывала хорошее качество детектирования. Однако после нескольких дней прокрастинации обдумывания реализации я решил воспользоваться более современными и интересными методами и подключить детектор от YOLO (взял не самую новую 4 версию).








Всем привет! В этой статье мы расскажем о непростой задаче распознавания русского жестового языка (РЖЯ) для слабослышащих. Насколько нам известно, в открытом доступе не существует универсального набора данных для распознавания РЖЯ. Поэтому мы решили выложить небольшую часть нашего датасета в открытый доступ. В статье мы затронем основные особенности РЖЯ, поговорим о проблемах и сложностях самого языка, и процессе его сбора и разметки. Расскажем, где искали экспертов и как нам в итоге удалось собрать самый большой и разнородный жестовый датасет для РЖЯ. В конце статьи представим набор предобученных нейронных сетей и небольшое приложение, демонстрирующее распознавание жестового языка. Часть датасета и веса моделей мы выложили в открытый доступ — все ссылки вы можете найти в конце статьи или в нашем репозитории.

Женщины сами не знают, что хотят, а мужчины говорят о работе. И мои слова - это не стереотипное мышление, а обоснованное на данных заявление. По крайней мере, на основе данных 240 тысяч анкет женщин и мужчин, которые я спарсила с сайта mamba.ru, а потом “разложила по графичкам”. Цель была - сформировать портреты пользователей, но и плюсом пришла к приятному и немного трогательному выводу.
Категориальные данные имеет огромное значение в DataScience. Как справедливо заметили авторы в [1], мы живем в мире категорий: информация может быть сформирована в категориальном виде в самых различных областях - от диагноза болезни до результатов социологического опроса.
Частным случаем анализа категориальных данных является анализ таблиц сопряженности (contingency tables), в которые сводятся значения двух или более категориальных переменных.
Однако, прежде чем написать про статистический анализ таблиц сопряженности, остановимся на вопросах их визуализации. Казалось бы, об этом уже написано немало - есть статьи про графические возможности python, есть огромное количество информации и примеров с программным кодом. Однако, как всегда имеются нюансы - в процессе исследования возникают вопросы как с выбором средств визуализации, так и с настройкой инструментов python. В общем, есть о чем поговорить...
В данном обзоре мы рассмотрим следующие способы визуализации таблиц сопряженности.

Можно ли найти конкретного человека, жившего в XVII веке? Выражаясь современным языком «пробить по базам». Оказывается, архивные документы хранят массу информации об обычных людях того периода. Однако существует ряд сложностей, не позволяющих обычному исследователю добраться до этой информации. Во-первых, нужно пройти определённую процедуру по получению доступа в архив. Во-вторых, не всегда можно выйти на нужный документ, используя так называемый научно-справочный аппарат – различные описи и реестры документов, имеющиеся в архиве. Наконец, не имея навыков чтения документов XVII века, которые написаны скорописью, почти нереально ознакомиться с его содержанием.
Данные проблемы предполагается решить с помощью создания базы данных служилых людей XVII века. Об этом небольшая история.
Как всё начиналось.
Привет! Меня зовут Дмитрий и вот уже более 10 лет я изучаю историю южных уездов России XVII века. Территориально – это современные Белгородская, а также соседние Воронежская, Курская, Липецкая и другие области. Населены они были тогда так называемыми служилыми людьми – они получали здесь в качестве служебного жалования земельные наделы, которые сами и обрабатывали. В XVIII веке их потомки стали однодворцами, а затем государственными крестьянами. Большая часть населения Курской, Воронежской и соседних губерний XIX века происходят из тех самых служилых людей XVI–XVII веков.

Диффузионные модели могут значительно расширить мир творческой работы и создания контента в целом. За последние несколько месяцев они уже доказали свою эффективность. Количество диффузионных моделей растет с каждым днем, а старые версии быстро устаревают


С 5 сентября по 20 октября Хабр приоткрыл портал в оккультное IT-измерение, в котором обитают дата-сатанистысайентисты. Стоило произнести зловещее заклинание «стартует сезон Data Mining» и возложить на призовой алтарь игровой монитор, как на хаб слетелись десятки адептов.
Под катом подводим итоги сезона, показываем лучшие посты, знакомимся с авторами, славим победителя и поясняем, почему Data Mining так важен в современном мире.
Вместе с компанией SM Lab — спонсором сезона и куратором хаба — мы изучили присланные на конкурс манускрипты. Среди постов сезона были поразительные жемчужины. Лучшую из них определили читатели.