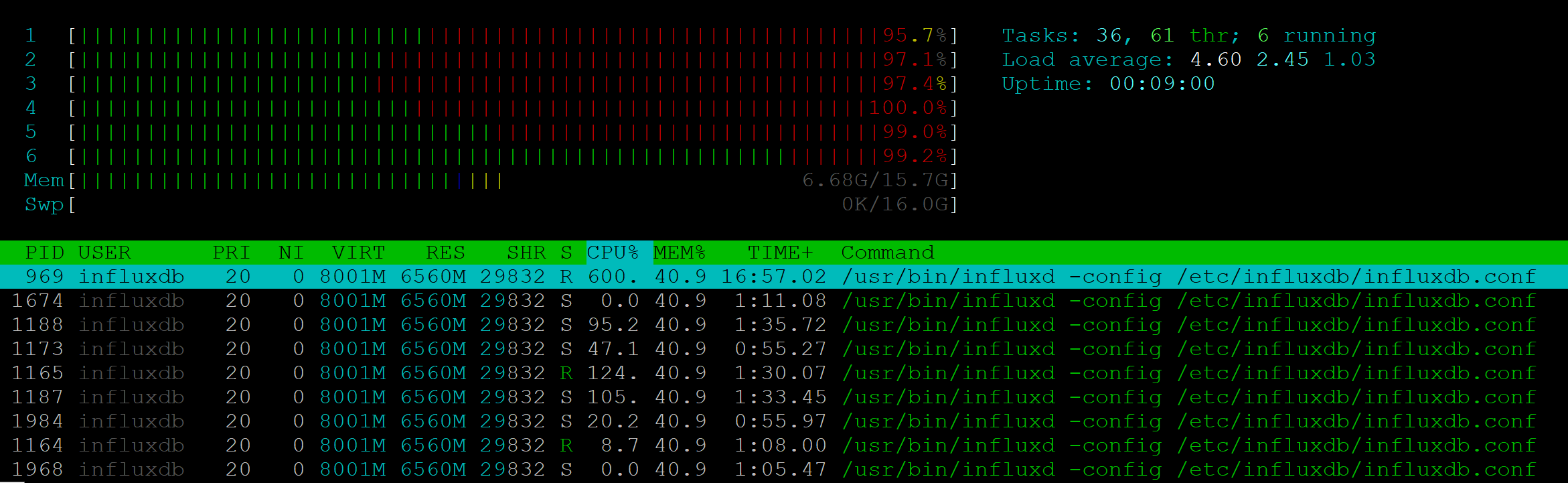
Давно хотел написать про то как я храню свои файлы, как делаю бэкапы, но все никак не доходили руки. Недавно тут появилась статья, в чем-то похожую на мою но с другим подходом.
Сама статья.
Я уже много лет пытаюсь найти идеальный для себя метод для хранения файлов. Думаю я его нашел, но всегда есть что улучшить, если есть какие-то мысли как сделать лучше, с удовольствием почитаю.
Начну с того что расскажу пару слов о себе, я занимаюсь веб разработкой и в свободное время фотографирую. Отсюда вывод что хранить мне нужно рабочие и личные проекты, фото, видео ну и другие файлы.
У меня где-то 680 GB файлов, из них процентов 90 это фото и видео.
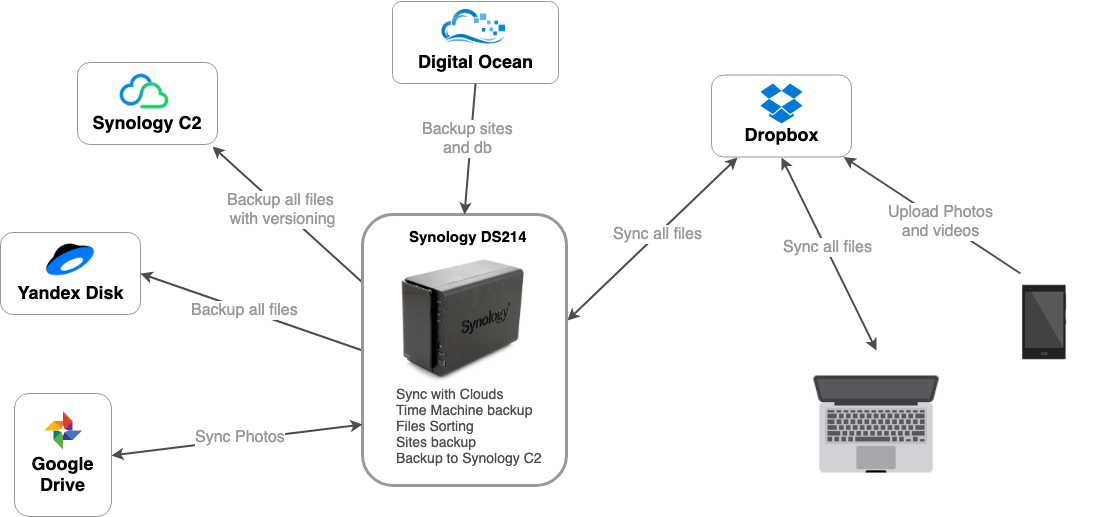
Тут примерная схема того как и где хранятся все мои файлы.
Сама статья.
Я уже много лет пытаюсь найти идеальный для себя метод для хранения файлов. Думаю я его нашел, но всегда есть что улучшить, если есть какие-то мысли как сделать лучше, с удовольствием почитаю.
Начну с того что расскажу пару слов о себе, я занимаюсь веб разработкой и в свободное время фотографирую. Отсюда вывод что хранить мне нужно рабочие и личные проекты, фото, видео ну и другие файлы.
У меня где-то 680 GB файлов, из них процентов 90 это фото и видео.
Круговорот файлов в моих хранилищах:
Тут примерная схема того как и где хранятся все мои файлы.