

Чтобы система долго работала без сбоев и перерывов, нужно поработать над отказоустойчивостью. В статье дадим несколько способов её построить и покажем готовое решение.
Чтобы система долго работала без сбоев и перерывов, нужно поработать над отказоустойчивостью. В статье дадим несколько способов её построить и покажем готовое решение.

В начале ноября так сложились обстоятельства, что мне с коллегой довелось поучаствовать в качестве судей на мероприятии под строгим названием «Отборочный этап чемпионата России по спортивному программированию» в дисциплине «Продуктовое программирование». Или, говоря более простым языком — студенческий трехдневный онлайн-хакатон, победители которого поедут на финал чемпионата страны в Москву.
Вот об этом мероприятии, что на нём было интересного и каких-то выводах из увиденного сегодня и поговорим.

Системы управления базами данных (далее по тексту – СУБД) – набор компонентов, с помощью которого можно создавать, хранить, передавать и управлять базами данных. Они нужны практически на любом предприятии, которому приходится иметь дело с большими массивами информации: это могут быть данные о товарах магазина или производителя, данные о клиентах, данные о сотрудниках, данные о вашем сайте – в общем, всё, что по какой-то причине нужно хранить для решения разных бизнес-задач.

Меня зовут Вадим Ивахин, я техлид в Vi.Tech — это IT-дочка ВсеИнструменты.ру.
Я и мои коллеги трудимся над большим количеством проектов и используем в своей работе различные инструменты, в том числе MongoDB. В этой статье я не стану рассказывать о том, что такое MongoDB. Хочу рассказать о её интересной и удобной особенности — механизме Watch, и о том, как с его помощью спроектировать приложение, способное выдержать десятки тысяч rps.

Параллелизм – это возможность выполнения запросов сервером СУБД в нескольких потоков. По умолчанию в настройках SQL Server параллелизм не ограничен и потенциально для выполнения запроса могут использоваться все ядра всех процессоров (max degree of parallelism= 0). В то же время, в системах 1С вендор настоятельно рекомендует установить max degree of parallelism = 1, и, соответственно, один запрос будет использовать только одно ядро.
Почему так и что же с этим всем делать? Давайте разбираться.

ClickHouse — система управления базами данных с открытым исходным кодом, построенная на основе колонок. Это означает, что данные хранятся и обрабатываются не по строкам, а по столбцам. Она стала широко популярной среди ИТ-организаций благодаря своим способностям по быстрой обработке данных и масштабируемости. Высокопроизводительная обработка запросов в ClickHouse делает ее идеальным выбором для работы с большими объемами данных и оперативной аналитики.
В данной статье мы подробно рассмотрим, что представляет собой разработка ClickHouse, а также как организации используют ее для хранения и обработки данных. Еще мы обсудим недостатки этой системы и разберемся, насколько подходит она под ваши потребности.

Не секрет, что работа с часовыми поясами — боль, и многие разработчики объяснимо стараются ее избегать. Тем более что в каждом языке программирования / СУБД работа с часовыми поясами реализована по-разному.
Среди тех, кто работает с PostgreSQL, есть очень распространенное заблуждение про типы данных timestamp (который также именуется timestamp without time zone) и timestamptz (или timestamp with time zone). Вкратце его можно сформулировать так:
Мне не нужен тип timestamp with time zone, т.к. у меня все находится в одном часовом поясе — и сервер, и клиенты.
В статье я постараюсь объяснить, почему даже в таком довольно простом сценарии можно запросто напороться на проблемы. А в более сложных (которые на самом деле чаще встречаются на практике, чем может показаться) баги при использовании timestamp практически гарантированы.

По определенным обстоятельствам потребовалось создать имитацию всего контура тестируемого нами ПО, контур включает в себя множество различных сервисов, но в этой статье остановимся на базе данных, так как процесс ее развертывания наиболее нитереснен.
В статье освещен процесс решения проблем при сборке образа и запуске контейнера

Мы продолжаем погружение в основы операционной системы OpenVMS. В прошлых статьях мы установили её в качестве виртуальной машины, настроили сеть и активировали лицензии. Бонусом поставили туда SSH и даже организовали Web-интерфейс для удобного управления. Теперь пришла пора попробовать раскатать какой-нибудь простой сервис вроде Redis.
Уверены, что большинство наших читателей c Хабра знает, что это такое. Но если вы впервые слышите эту аббревиатуру, немного расскажем о ней. Расшифровывается она как Remote Dictionary Server. Это скоростная in-memory NoSQL СУБД, используемая для работы с парами «ключ:значение». Чаще всего её используют в качестве кэша перед основными БД, такими как MariaDB или PostgreSQL.

Привет! Меня зовут Петр и мы в компании Nixys очень любим Redis. Эта база используется, если не на каждом нашем проекте, то на подавляющем большинстве. Мы работали как с разными инсталляциями Redis, так и с разными версиями, вплоть до самых дремучих, вроде 2.2. Несмотря на то, что в Интернете очень много статей и докладов по этой БД, мы в своей практике достаточно часто встречаемся с непониманием некоторых основных концепций Redis и со стороны разработчиков, и со стороны системных администраторов.
В серии статей я попытаюсь осветить неочевидные нюансы при работе с Redis и сегодня начну с основных концепций и понятий. А еще в конце статьи приведу небольшой чек-лист, который может помочь вам в оптимизации этого NoSQL решения.

При написании бэкенда работа с базой данных зачастую составляет большую часть кода в проекте. Но несмотря на то, что в го стандартная библиотека для тестирования довольно удобная, она требует написания большого количества кода. Поэтому иногда вместо того, чтобы писать тесты разработчики могут ограничить тестирование при помощи какого-либо клиента (например, при помощи tableplus или другого sql-клиента), либо тестируют уже конечные точки API используя postman. С одной стороны, это, конечно может быть быстрее для первого тестирования, но с другой — такие методы не обеспечивают должного покрытия тестами приложения.
Решить проблему с написанием большого количества кода может помочь библиотека testify, которая позволяет писать тесты более выразительно и с меньшим количеством кода. В testify есть пакеты require и assert, в первом случае выполнение теста будет прервано, а во втором — продолжено. В статье будет использоваться пакет assert. Для облегчения понимания кода можно использовать табличное тестирование, которое поможет определить, какие случаи проверяются даже при беглом взгляде на код.
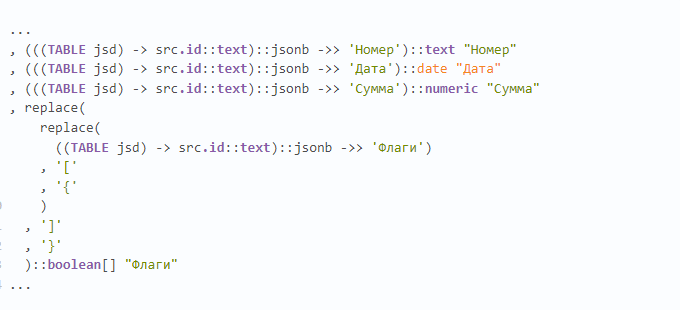
Недавно попался на глаза примерно такой кусок запроса, и тут прекрасно примерно все:
• множество чтений из CTE (хоть и единственной записи, но все же);
• извлечение по каждому ключу текста с раскастовкой в jsonb;
• извлечение каждого отдельного json-ключа в каждое отдельное одноименное поле;
• "ручное" преобразование текстового представления массива в json в текстовое представление PostgreSQL.
А как - правильно?

Привет, Хабр!
PostgreSQL, одна из самых мощных и гибких реляционных СУБД, предлагает нам свой модуль pg_trgm, чтобы решить сложную задачу полнотекстового поиска.
Когда речь идет о поиске, просто LIKE запросы больше не всегда могут удовлетворить технические требования. Полнотекстовый поиск подразумевает не только поиск точных соответствий, но и учет схожести слов, учет морфологии, а также поддержку более сложных запросов. PostgreSQL, конечно, предоставляет средства для выполнения таких задач, и модуль pg_trgm - один из инструментов, с помощью которого это можно сделать.
Итак, что такое pg_trgm? Этот модуль PostgreSQL предоставляет набор функций и операторов, которые позволяют работать с трехграммами (триграммами) - это последовательности из трех символов. Для понимания, давайте взглянем на пример...








Сегодня мы поговорим о СУБД Redis, рассмотрим процесс установки и настройки. В отличие от реляционных систем управления базами данных, Redis является СУБД класса NoSQL с открытым исходным кодом, работающей со структурами данных типа «ключ — значение».
Разберемся для начала с тем, что такое NoSQL. Представим, что у нас есть приложение, которому необходимо быстро и без задержек обрабатывать разные по структуре данные, не имеющие определенной структуры. В таком случае использование “классических”, реляционных баз данных будет не самым лучшим решением, так как нам необходимо будет сначала каким-то образом структурировать эти данные, а уже потом с ними работать. При использовании NoSQL мы можем использовать структуру “ключ-значение” и иметь возможность быстро обрабатывать неструктурированные данные. NoSQL используются как для баз данных, так и для реализации кэшей, брокеров сообщений. При этом, NoSQL стала популярным решением из-за простоты разработки, функционала, высокой производительности и возможности горизонтального масштабирования.
Но, вернемся к СУБД Redis. Redis - это хранилище значений ключей в памяти, известное своей гибкостью, производительностью и широкой языковой поддержкой. Данная система ориентирована на достижение максимальной производительности на атомарных операциях (заявляется о приблизительно 100 тыс. SET- и GET-запросов в секунду на Linux-сервере начального уровня). Написана на Си, интерфейсы доступа созданы для большинства основных языков программирования. Далее мы поговорим о том, как установить и безопасно настроить Redis на сервере Ubuntu 22.04.





Всем привет! Я Алексей Пономаревский, разработчик решений для платформ сбора и обработки больших данных.
Два года назад мы в ITSumma создали решение для потоковой обработки данных с помощью Apache Spark и базы данных Greenplum — spark-greenplum-connector. Это многофункциональный плагин для Spark, на его основе инженеры могут строить ETL-решения и анализировать данные in-memory.
Изначально мы разработали его, как часть клиентской платформы потоковой обработки данных. Но со временем он прирос одной интересной функциональностью, которая недоступна сейчас в других подобных решениях. В этой статья я хочу сделать краткое сравнение между двумя opensource-продуктами Apache Spark и Flink, а также рассказать об одной интересной особенности Spark, которую мы реализовали в коннекторе.

На стабильную работу ИТ-инфраструктуры компании в локальном дата-центре влияет много факторов: резервирование по схеме N+1, работа инженерных систем, экспертиза технических специалистов. Однако есть и внешние. К ним относится отказ оборудования, природные катаклизмы и геополитические конфликты.
В статье мы рассказали, как специалисты ITGLOBAL.COM запустили резервную площадку для восстановления данных после сбоев (Disaster Recovery) в облаке для ГК «Интерлизинг». А на YouTube выпустили видео с интервью участников проекта.