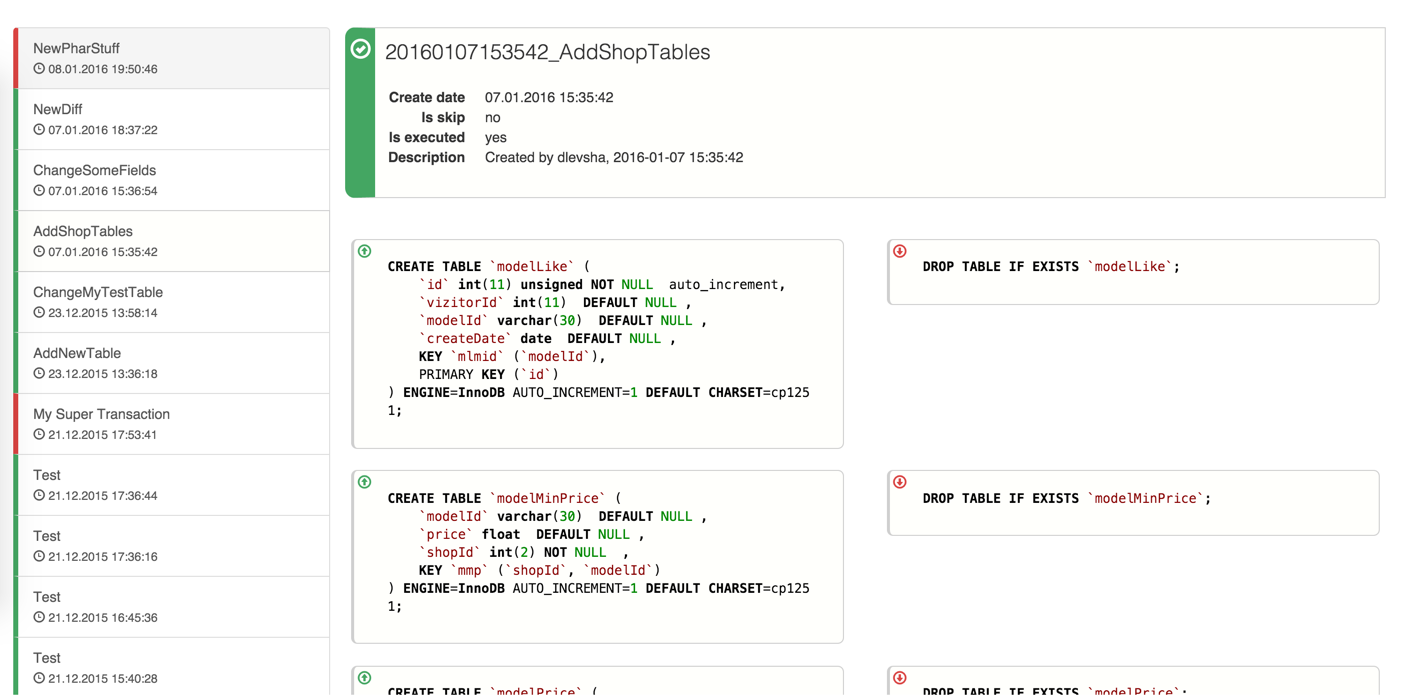
Интеграция с БД - привычно сложная и хрупкая часть большинства кодобаз, постоянно отвлекающая внимание разработчиков и раздувающая сроки. Какой бы хайпующий фреймворк вы ни пробовали, вы неизбежно обнаруживаете себя борющимся с одними и теми же симптомами, но ощущение того, что проблема могла бы решаться проще не покидает вас. Знакомо?
Оказывается, так вовсе не должно быть. В данном посте мы разберёмся в причинах и сформулируем подход, который оставляет большинство привычных проблем просто несуществующими.