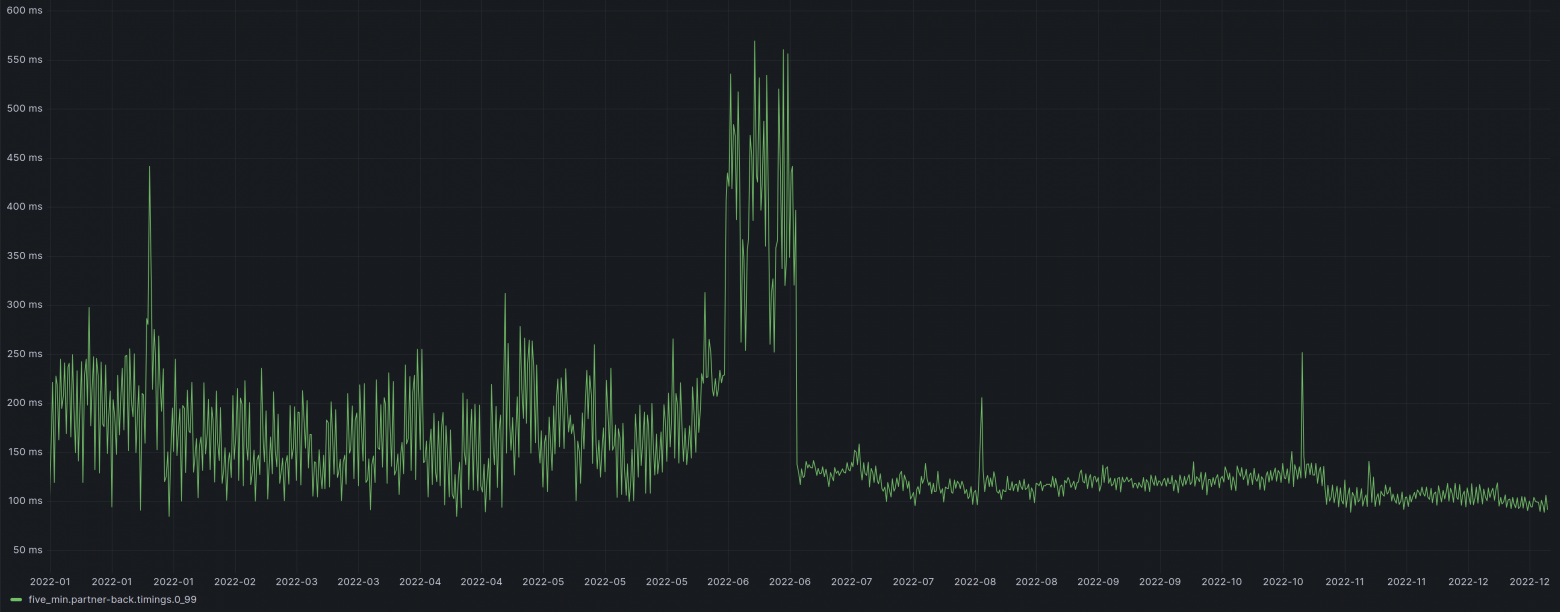
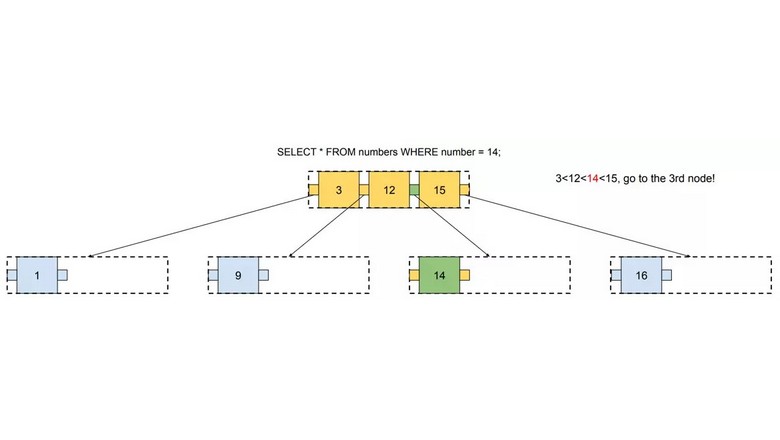
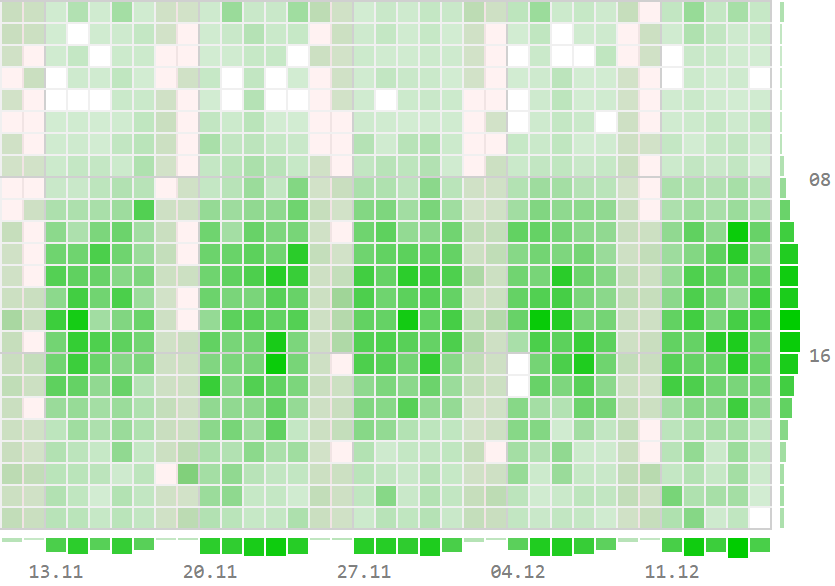
Привет, Хабр! Меня зовут Максим, я работаю тестировщиком оборудования в Selectel Lab. В лаборатории мы занимаемся тестированием нового оборудования для дата-центров. О том, как мы измеряли производительность PostgreSQL на разных конфигурациях — под катом!