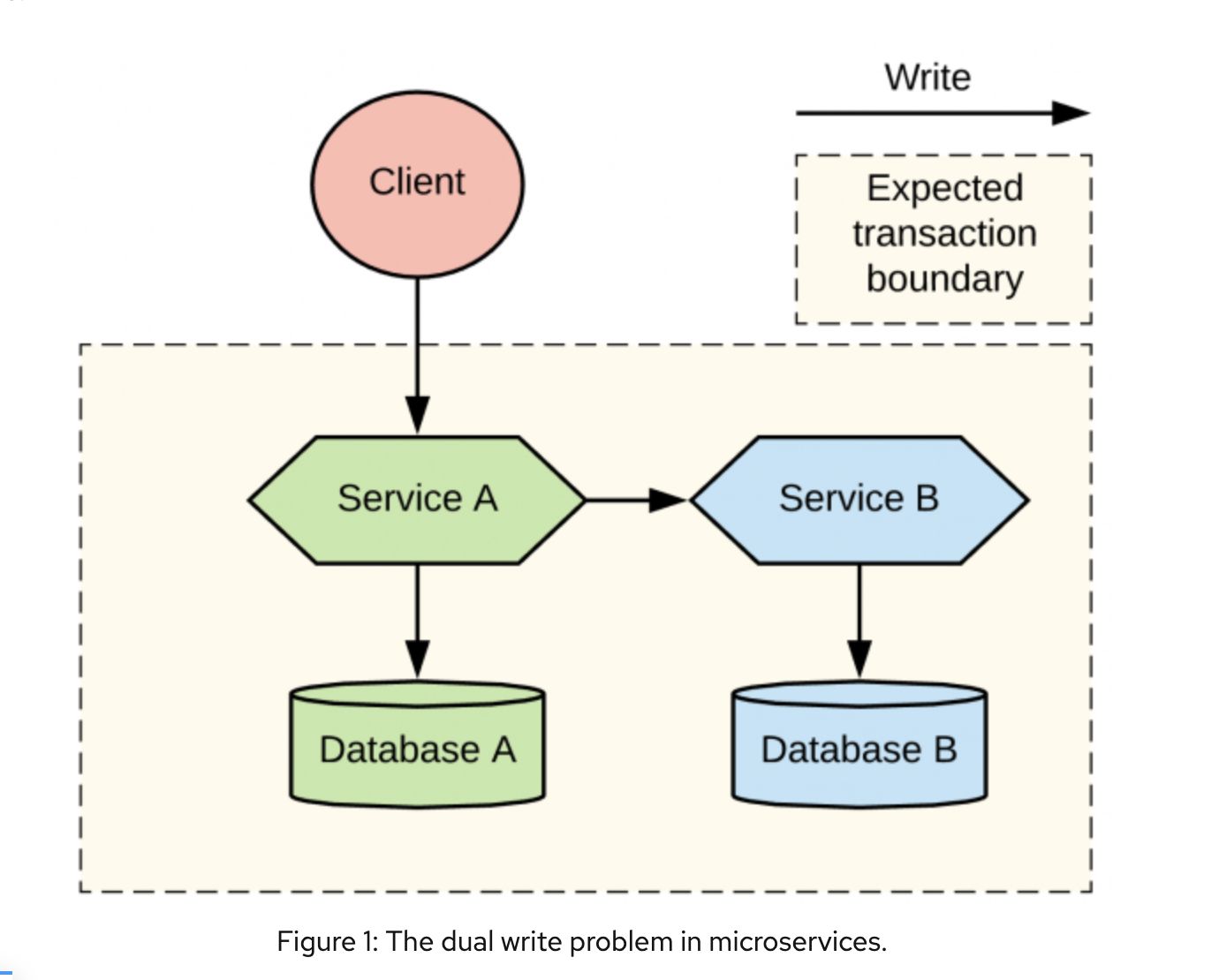
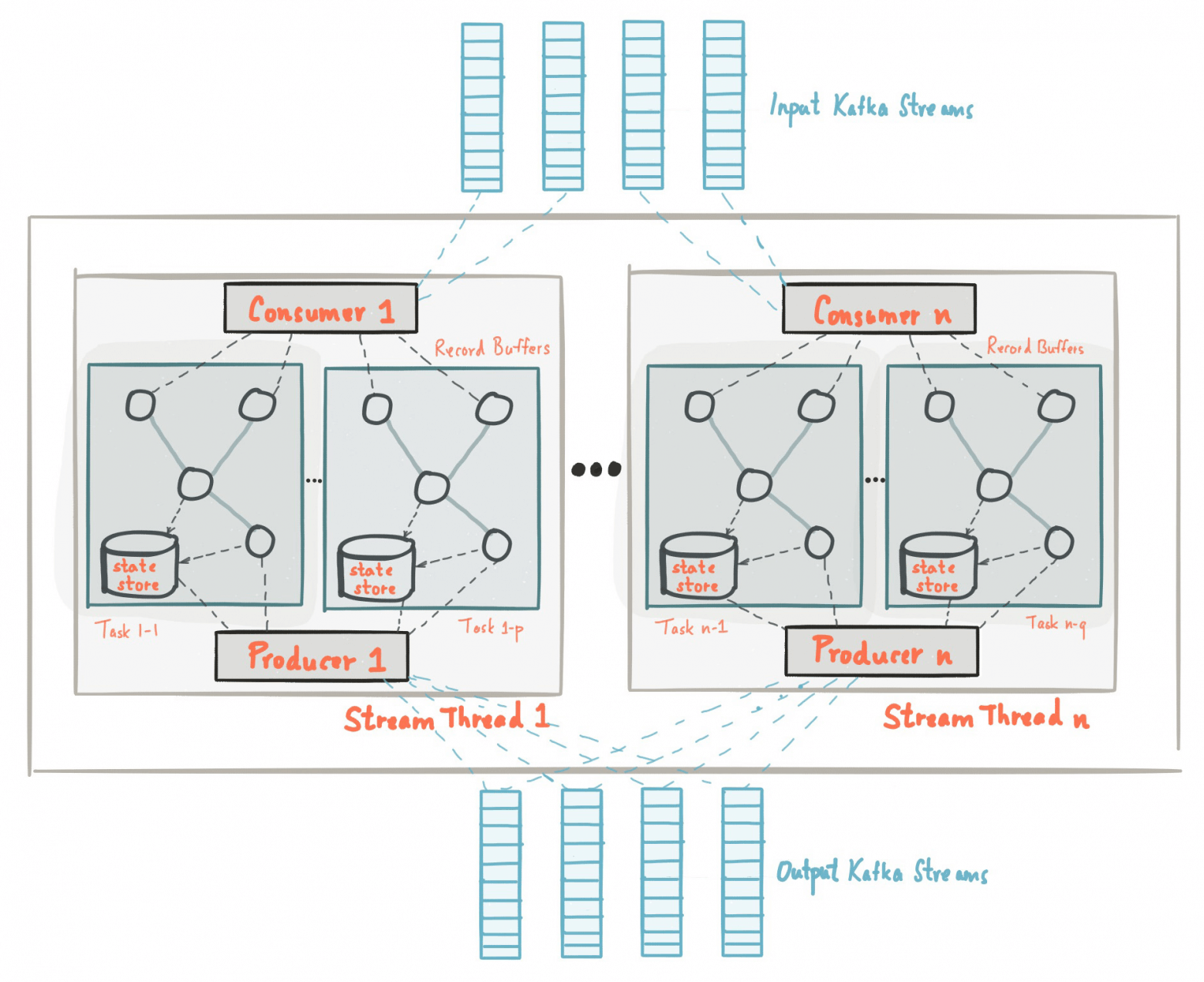
Статья посвящена анализу и сравнению двух моделей построения систем — монолитной и с разделением на микросервисы. В ней мы с разных сторон оценим оба этих подхода и связанную с ними сложность, убедившись в превосходстве последнего. Представим микросервисы и прочие архитектуры в реалистичном свете, не воскрешая то, что должно оставаться мёртвым.