
Сегодня мы расскажем об одном из сервисов SAP, который характеризует наш новый подход к созданию продуктов и работе с клиентами. Это решение SAP Cloud Platform Big Data Services, которое предлагает клиентам возможность работать с большими данными в Hadoop по модели подписки на облачное приложение.
В первой статье мы сделаем обзор того, как анализ Big Data может пригодиться бизнесу на практике, как отличаются облачного и on-premise размещения Hadoop, а про основные функции, сервисы и технологии в SAP Cloud Platform Big Data Services. В следующих статьях мы подробнее разберём технологические особенности и отдельные сервисы внутри данного решения.
Big Data в бизнесе

В первой статье мы сделаем обзор того, как анализ Big Data может пригодиться бизнесу на практике, как отличаются облачного и on-premise размещения Hadoop, а про основные функции, сервисы и технологии в SAP Cloud Platform Big Data Services. В следующих статьях мы подробнее разберём технологические особенности и отдельные сервисы внутри данного решения.
Big Data в бизнесе

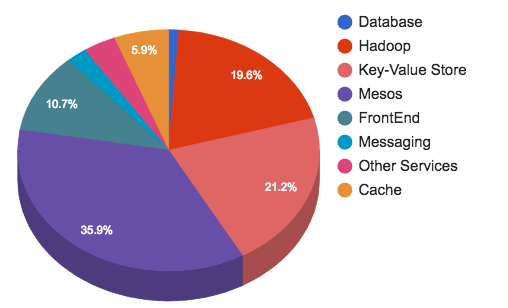


 Эта статья послужит практическим руководством по сборке, начальной настройке и тестированию работоспособности Hadoop начинающим администраторам. Мы разберем, как собрать Hadoop из исходников, сконфигурировать, запустить и проверить, что все работает, как надо. В статье вы не найдете теоретической части. Если вы раньше не сталкивались с Hadoop, не знаете из каких частей он состоит и как они взаимодействуют, вот пара полезных ссылок на официальную документацию:
Эта статья послужит практическим руководством по сборке, начальной настройке и тестированию работоспособности Hadoop начинающим администраторам. Мы разберем, как собрать Hadoop из исходников, сконфигурировать, запустить и проверить, что все работает, как надо. В статье вы не найдете теоретической части. Если вы раньше не сталкивались с Hadoop, не знаете из каких частей он состоит и как они взаимодействуют, вот пара полезных ссылок на официальную документацию:














