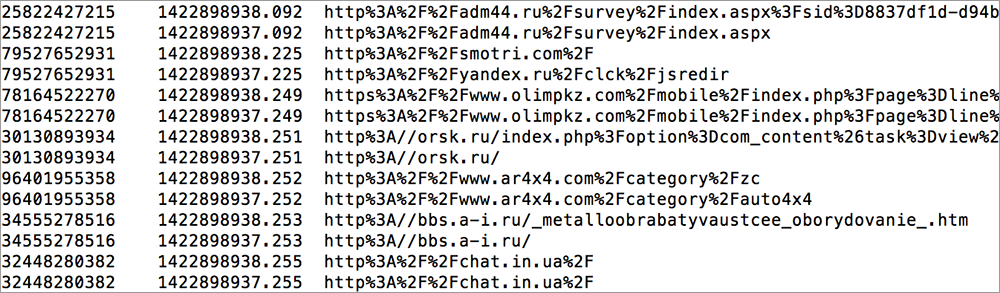
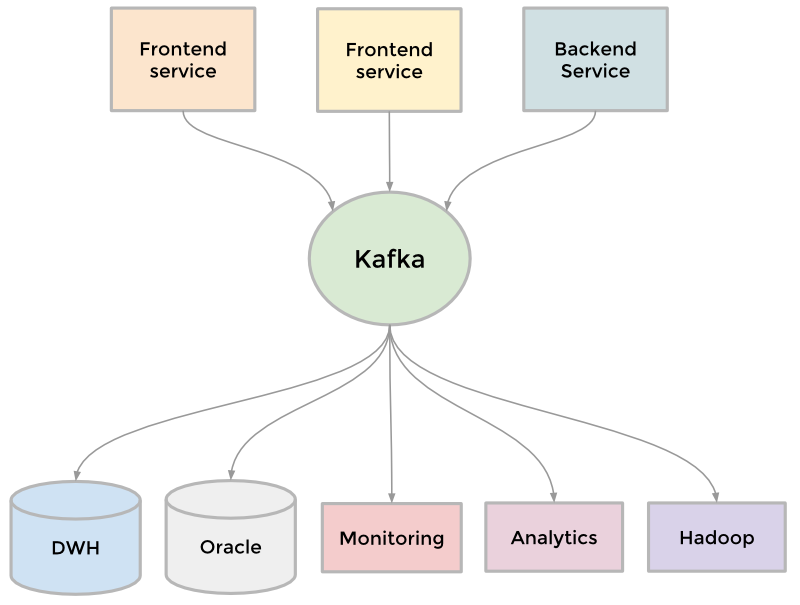
Привет, Хабр! Мы продолжаем наш цикл статьей, посвященный инструментам и методам анализа данных. Следующие 2 статьи нашего цикла будут посвящены Hive — инструменту для любителей SQL. В предыдущих статьях мы рассматривали парадигму MapReduce, и приемы и стратегии работы с ней. Возможно многим читателям некоторые решения задач при помощи MapReduce показались несколько громоздкими. Действительно, спустя почти 50 лет после изобретения SQL, кажется довольно странным писать больше одной строчки кода для решения задач вроде «посчитай мне сумму транзакций в разбивке по регионам».
С другой стороны, классические СУБД, такие как Postgres, MySQL или Oracle не имеют такой гибкости в масштабировании при обработке больших массивов данных и при достижении объема большего дальнейшая поддержка становится большой головоной болью.

Собственно, Apache Hive был придуман для того чтобы объединить два этих достоинства:
Под катом мы расскажем каким образом это достигается, каким образом начать работать с Hive, и какие есть ограничения на его применения.
С другой стороны, классические СУБД, такие как Postgres, MySQL или Oracle не имеют такой гибкости в масштабировании при обработке больших массивов данных и при достижении объема большего дальнейшая поддержка становится большой головоной болью.
Собственно, Apache Hive был придуман для того чтобы объединить два этих достоинства:
- Масштабируемость MapReduce
- Удобство использования SQL для выборок из данных.
Под катом мы расскажем каким образом это достигается, каким образом начать работать с Hive, и какие есть ограничения на его применения.









 [@tsafin — Обладателя
[@tsafin — Обладателя