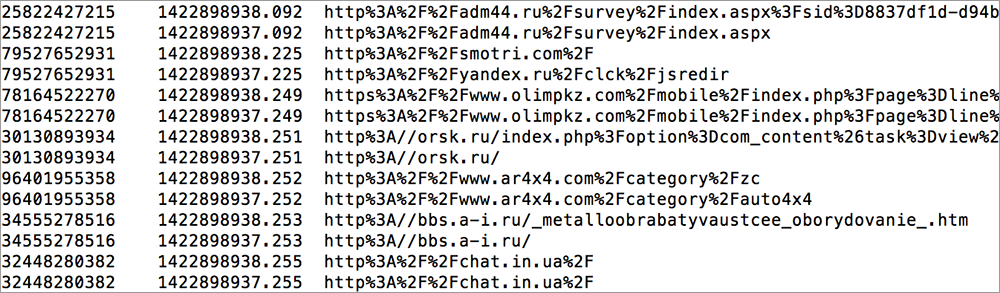
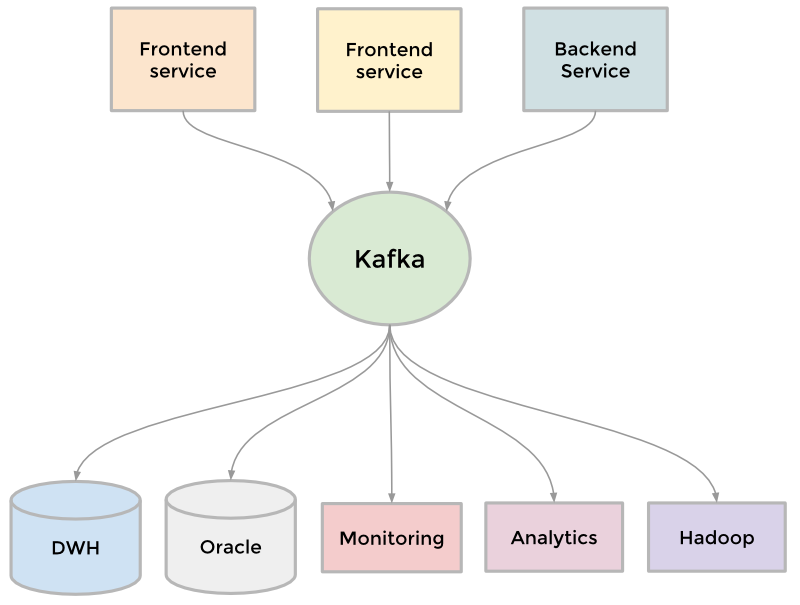
Привет, Хабр! Мы продолжаем цикл статей, посвященный Apache Flume. В предыдущей части мы поверхностно рассмотрели этот инструмент, разобрались с тем, как его настраивать и запускать. В этот раз статья будет посвящена ключевым компонентам Flume, с помощью которых не страшно манипулировать уже настоящими данными.









 [@tsafin — Обладателя
[@tsafin — Обладателя