❓Как проектировать системы, которые будут толерантными для различного вида отказов и ошибок?
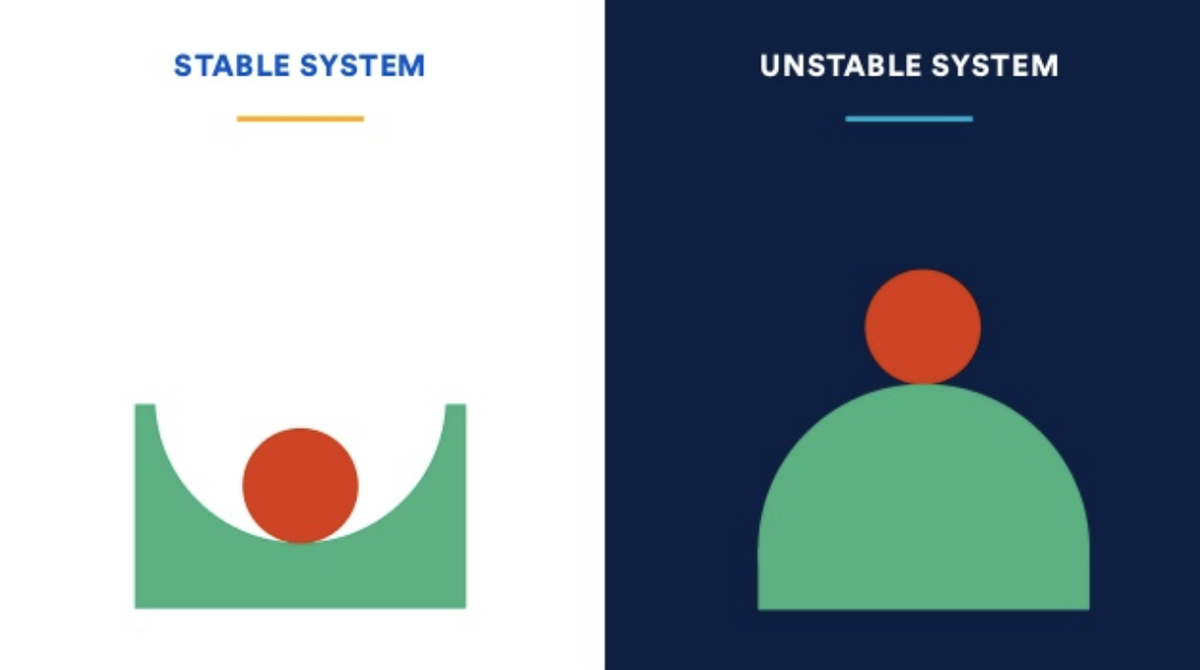
Что такое отказоустойчивость и стабильность?
Под отказоустойчивостью будем понимать свойство системы, которое позволяет максимально сохранять работоспособность при отказе отдельных конкретных компонентов системы либо связанных систем и восстанавливать работоспособность системы при восстановлении отказавших компонентов или связанных систем. Давайте рассмотрим подробнее эти 2 момента:
1. Деградация работоспособности системы должна быть прямо пропорциональна "величине" отказа. То есть, если упал сервис, отвечающий за некую некритичную функциональность — вся система не должна при этом падать. Да, небольшой кусочек не работает, но это не влияет на стабильность остальной части функционала.
2. Стабильность системы предполагает самостоятельного восстановления работоспособности после сбоя как компонентов системы, так и всей системы в целом. К примеру, если пропадала сеть на некоторое время — то у стабильных систем после восстановления подключения все компоненты продолжат работать и данные вернутся в консистентное состояние без ручного вмешательства со стороны команды эксплуатации.