

Это вторая и заключительная часть статьи, в которой мы рассматриваем задачу классификации экзопланет. Если предыдущая статья была больше про предобработку данных, то здесь мы будем строить модели, отбирать лучшие и экспериментировать.
Это вторая и заключительная часть статьи, в которой мы рассматриваем задачу классификации экзопланет. Если предыдущая статья была больше про предобработку данных, то здесь мы будем строить модели, отбирать лучшие и экспериментировать.
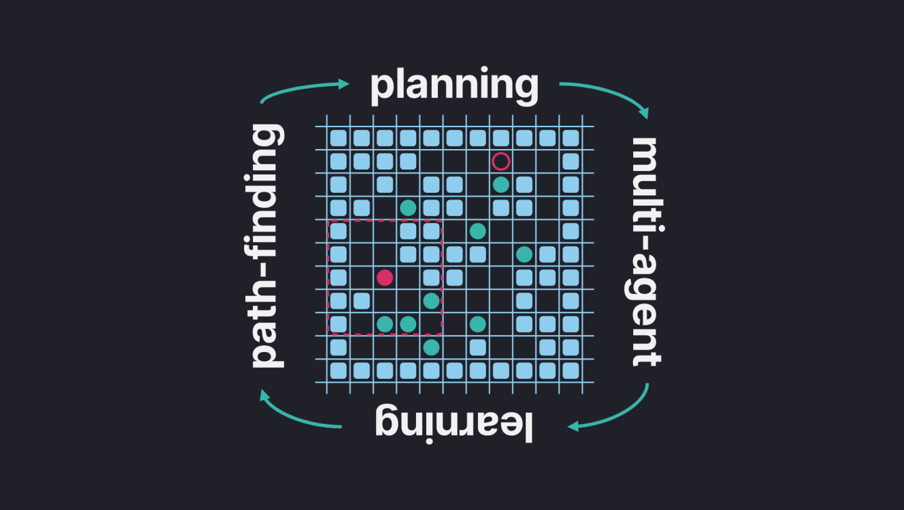
Привет! Меня зовут Константин Яковлев, я научный работник и вот уже более 15 лет я занимаюсь методами планирования траектории. Когда речь идет о том, чтобы построить траекторию для одного агента, то задачу зачастую сводят к поиску пути на графе, а для этого в свою очередь обычно используют алгоритм A* или какие‑то из его многочисленных модификаций. Если же агентов много, они перемещаются в рабочем пространстве одновременно, то задача (внезапно) становится несколько более сложной и применить напрямую A* не получится. Вернее получится, но лишь для небольшого числа агентов (проклятье размерности, куда деваться). Тем не менее для централизованного случая, т. е. для случая, когда есть один (мощный) вычислитель, с которым связаны все агенты и который всё про всех знает, решить задачу много‑агентного планирования можно достаточно эффективно. Можно даже находить оптимальные решения для умеренного количества агентов за относительное приемлемое время (например, порядка 1 секунды на современном десктопном PC для 30–50 агентов).
Если же говорить о децентрализованном случае, т. е. о том случае, когда агентам необходимо действовать индивидуально (например, нет устойчивой связи с центральным контроллером), опираясь лишь на собственные (локальные) наблюдения и опыт, то с хорошими решениями задачи становится гораздо сложнее. Когда я говорю «хорошие решения», я имею в виду прежде всего такие алгоритмы, которые бы давали стройные теоретические гарантии в общем случае. Хотя бы гарантии того, что каждый агент дойдёт (за конечное время) до своей цели. Тем не менее, задача интересная и специалисты из индустрии и академии её пытаются решать.
В этом посте я расскажу о наших свежих наработках в этой области, а именно о гибридном методе, которые сочетает в себе принципы классического эвристического поиска (A*) и обучения с подкреплением (PPO). Метод получился неплохим, превосходящим многие современные аналоги по результатам экспериментов, а соответствующая статья была принята на The 38th AAAI Conference on Artificial Intelligence (пока доступен только препринт). Это одна из топовых академических конференций по искусственному интеллекту, которая в этом (2024) году проходила в Канаде (спойлер: я сам визу получить не успел, но моим коллегам и со‑авторам, кто имел ранее выданные Канадские визы, удалось принять личное участие и достойно представить нашу науку на мировом уровне).

Пять лет назад из обычного продакт-менеджмента я перешла в команду с дата-сайентистами. И весь процесс моей работы сильно изменился.
Раньше после определения потребностей пользователя я приходила к команде разработки с готовой задачей и дизайн-макетами. А после разработки забирала готовый продукт, чтобы отдать его в A/B-тест.
В ML все работает иначе. Команда включается уже на этапе исследования, погружается в бизнес-цели и техническую постановку задачи. Именно исследования занимают львиную долю времени дата-сайентистов, и только после начинается разработка.
Ну, или не начинается. Или разработка начинается, но совсем не той идеи, которая была вначале.
Я — Саша Пургина, руковожу развитием продуктов на основе данных в Lamoda Tech. В этой статье я расскажу на примере Lamoda, почему разработка ML-продуктов — это сложность и риск. И приведу примеры ошибок, когда хороший продакт в команде может увеличить шансы на успех, имея определенные знания и навыки.
Серебряной пули не ждите, но пара интересных мыслей должна найтись!

Всё течёт, всё изменяется. Особенно информация — она очень быстро устаревает. В e‑com неактуальные данные о товарах могут сильно подпортить клиентский опыт. Если удовлетворенность пользователей — важный фокус вашей работы, мне есть чем поделиться:)
Всем привет! Я Григорий Фрольцов, Product Lead машинного обучения в команде контента в СберМаркете. В этой статье я расскажу, какие «сюрпризы» могут происходить с данными об ассортименте, а также о том, с помощью каких продуктовых решений мы эти сложности решаем. Цель моей работы — добиваться максимально актуальной информации на витринах сервиса: с помощью ML и не только.
Расскажу про типовые и нетиповые проблемы. Опишу, какие инструменты используем, чтобы минимизировать рассинхрон в передаче знаний между оффлайн‑точкой и онлайн‑площадкой для торговли. Если вы аналитик или биздев в e‑com, продакт‑менеджер интернет‑магазина или работаете над эффективностью операций, точно найдёте для себя интересный инсайты.

«Анекдот, характеризующий наш промышленный подход: если индусу поставить задачу через месяц что‑то сделать, то через месяц он принесет идиотскую программу, которая будет плохо работать. А если русскому математику поставить аналогичную задачу — через месяц сделать программу, примерно через 25 дней он пришлет сообщение, что задача поставлена неправильно и ее надо ставить совершенно по‑другому». О чем это мы? Через призму юмора и науки говорим о нейронных сетях, искусственном интеллекте, приводя лишь отрывок из нового выпуска подкаста «Синий экран смерти». В программе принял участие Владимир Львович Арлазаров — советский и российский ученый, доктор технических наук, член‑корреспондент РАН, директор по науке Smart Engines.
В ходе беседы пионер в области искусственного интеллекта в СССР и мире рассказал о работе над программой «Каисса», которая 50 лет назад победила на первом чемпионате мира среди компьютерных программ, поделился мнением о научном обмене и высказал теории о будущем искусственного интеллекта.

Весь мир — это модель, а LLM в нём — бэкенд
На любом этапе развития AI активно идут философские или около того рассуждения. Сейчас, например, мы спорим насчет того, что такое AGI или world model. Последняя концепция впервые появилась, наверное, несколько десятков лет назад, но на новый уровень её вывел Ян Лекун.
Как сделать, чтобы машины обучались настолько же эффективно, как люди или животные? Как машины могут обучиться репрезентациям и планировать действия на нескольких уровнях абстракции? Для этого, по мнению Лекуна, машине нужна такая же внутренняя модель мира, которая есть у животных. Когда в 2022 году он высказался о своем дальнейшем видении AI, вопросов было больше чем ответов. С тех пор концепция world model постепенно вошла в оборот, хотя до сих пор не совсем понятно, что же имеется в виду (совсем недавно Лекун дал что-то вроде формального определения модели мира — скрины ниже) Но тем не менее, что-то, что называют world model появляется.

Краткое содержание. Модели машинного обучения, обученные на данных участников без каких-либо гарантий конфиденциальности, могут допустить утечку чувствительной информации.
Наша модель верифицируемого конфиденциального обучения под названием Confidential-DPproof (Confidential proof of differentially private training) способствует более конфиденциальному обучению и не раскрывает никакой информации об использованных данных и самой модели.
Confidential-DPproof доступна с открытым исходным кодом и может использоваться организациями для предоставления гарантий верифицируемой конфиденциальной защиты клиентских данных в продуктах на основе машинного обучения.
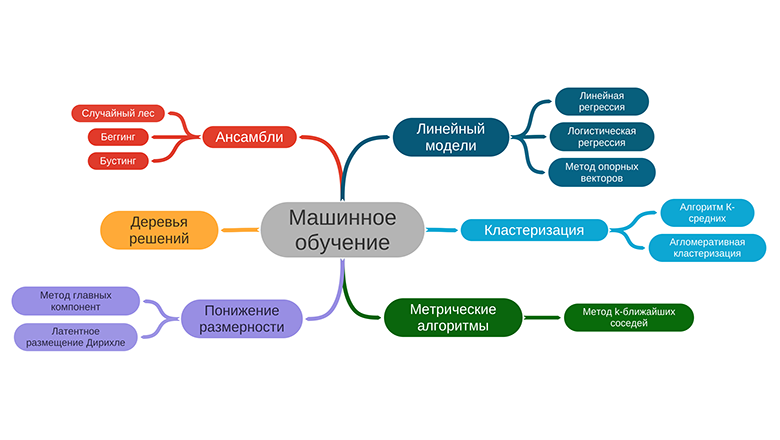
Краткий обзор курса, который я недавно закончил пилить на степике. Курс хардкорный :) В нем необходимо с нуля писать алгоритмы машинного. Наверное это один из лучший способов досконально разобраться в алгоритме.
Курс бесплатный: https://stepik.org/course/68260/promo

Линейный дискриминантный анализ (Linear Discriminant Analysis или LDA) — алгоритм классификации и понижения размерности, позволяющий производить разделение классов наилучшим образом. Основная идея LDA заключается в предположении о многомерном нормальном распределении признаков внутри классов и поиске их линейного преобразования, которое максимизирует межклассовую дисперсию и минимизирует внутриклассовую. Другими словами, объекты разных классов должны иметь нормальное распределение и располагаться как можно дальше друг от друга, а одного класса — как можно ближе.

Наивный байесовский классификатор (Naive Bayes classifier) — вероятностный классификатор на основе формулы Байеса со строгим (наивным) предположением о независимости признаков между собой при заданном классе, что сильно упрощает задачу классификации из-за оценки одномерных вероятностных плотностей вместо одной многомерной.
Помимо теории и реализации с нуля на Python, в данной статье также будет приведён небольшой пример использования наивного Байеса в контексте фильтрации спама со всеми подробными расчётами вручную.

Представьте себе игру с полностью открытым и бесконечным миром, этот мир живет своей жизнью, и игрок полностью свободен делать всё, что заблагорассудиться, а игра просимулирует результаты его действий. Такой, open world со своей уникальной вселенной. Интересная такая идея для петпроекта, не правда ли? В этой статье я расскажу о своей попытке реализовать подобную игру, по крайней мере её фундамент.

Выставка CES (Consumer Electronics Show), каждый год проходящая в январе в Лас-Вегасе, считается крупнейшей выставкой в мире высоких технологий. Часто она задает тренды на весь оставшийся год, как это было когда-то, например, с плоскими экранами или умным домом. Иногда яркие тренды CES вскоре угасают — как в случае с 3D-телевизорами. В этом году тоже не обошлось без телевизоров (в центре внимания оказались OLED-панели), но доминирующей темой стал искусственный интеллект. Далее мы вкратце расскажем про некоторые примечательные новинки в этой сфере, продемонстрированные на CES.
В прошлом году чуть ли не на каждой бизнес-конференции говорили, что ИИ изменит всё. Но когда доходило до подробностей, как же он всё изменит, спикеры обычно терялись.

Метод опорных векторов (Support Vector Machines или просто SVM) — мощный и универсальный набор алгоритмов для работы с данными любой формы, применяемый не только для задач классификации и регрессии, но и также для выявления аномалий. В данной статье будут рассмотрены основные подходы к созданию SVM, принцип работы, а также реализации с нуля его наиболее популярных разновидностей.








Владислав Урих, продуктовый аналитик Авито Работы, рассказал, как мы придумали новый подход к оценке актуальности резюме, и, благодаря этому, увеличили количество сделок, повысили retention работодателей в повторную покупку, и выросли в выручке категории.
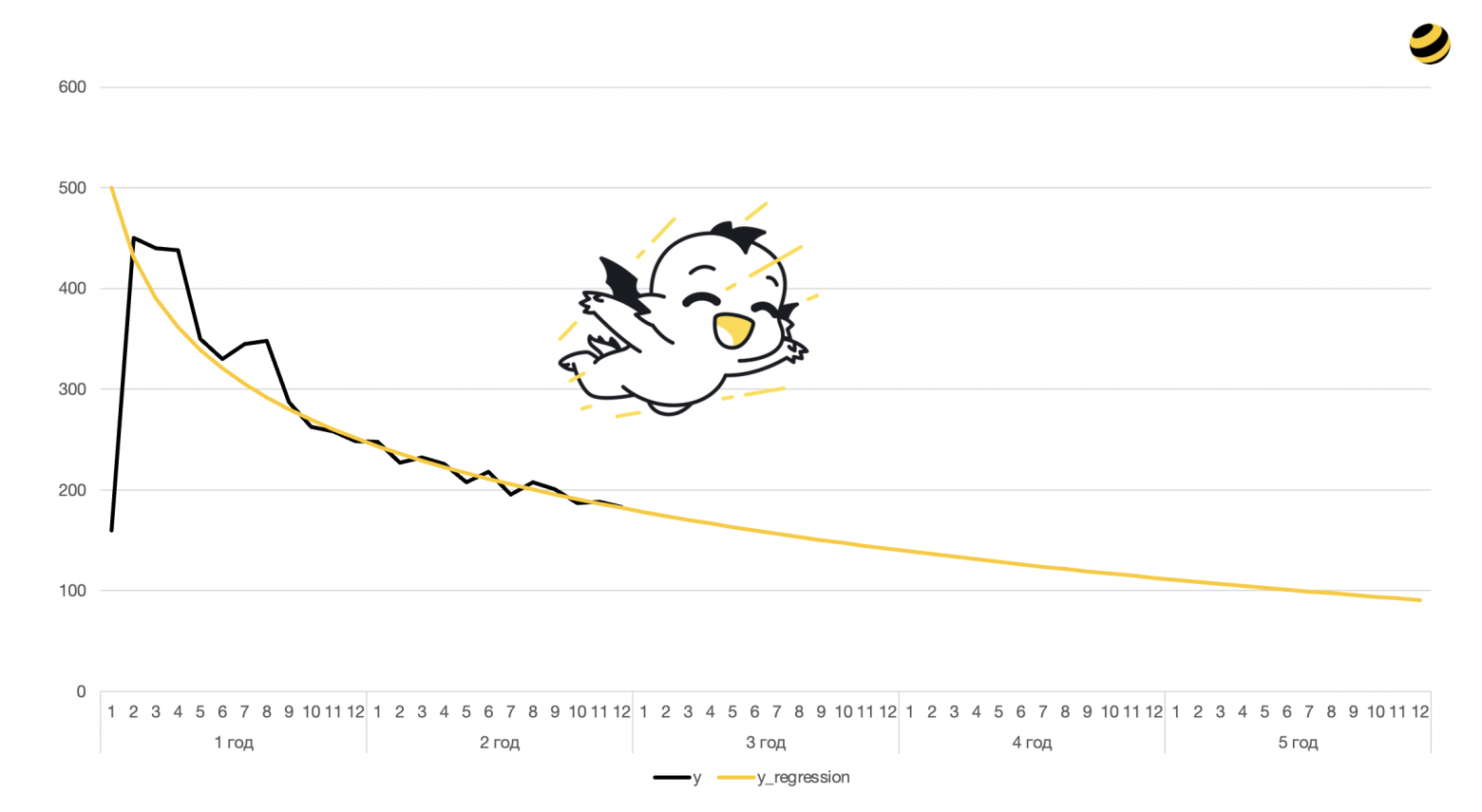
Эта статья описывает, как из прогнозов ряда ML-моделей получить ценность клиента с горизонтом в 5 лет. Напомним, что показатель CLTV представляет из себя композицию прогнозов ее компонент (подробнее в статье). В нашей реализации максимальный период прогнозирования моделей - 24 месяца. Важно отметить, что чем выше горизонт прогнозирования, тем менее точный прогноз способна сделать модель. А показатель CLTV интересен бизнесу на более длинном горизонте, в нашем случае - пять лет. Как же из прогнозов на два года получить прогноз на пять лет? Ответ прост: экстраполировать прогнозы.
Основная идея продления (экстраполяции) прогнозов - это разбиение пользователей на несколько групп, а в каждой группе единообразно продлить ряд прогноза.
Далее мы обсудим:
- подходы к экстраполяции ряда, их достоинства и проблемы
- как выбирать группы и подготовить данные для экстраполяции
- достоинства выбранного подхода к продлению прогнозов на 5 лет, трудности и пути их решения.
Человечество не умеет жить без мечты. Глобальной, размашистой, такой — чтобы всё или ничего. Люди мечтали летать, как птицы, видеть, как звери, обгонять самых быстрых, создавать золото из олова, не болеть, лечить рак, чинить гены, жить вечно, летать в космос, дотронуться до Луны… Что-то получается, что-то не сразу, что-то — и вовсе нет. Вторую половину XX и пока весь XXI век человечество мечтает…научиться думать. Только не головами, которые как раз мечтают и воплощают мечты в конкретные решения, а железными мозгами: создать компьютеры, обрабатывающие информацию по тому же принципу, что и люди, а то и способные к абстракции и воображению, — обучить машину думать. Это весьма практичная мечта, которая по задумке должна сделать мир лучше и перевернуть медицину, психологию, культуру, искусство, инженерию и почти всё, где мы используем мысль и речь. Догадались, о чём речь?

К-ближайших соседей (K-Nearest Neighbors или просто KNN) — алгоритм классификации и регрессии, основанный на гипотезе компактности, которая предполагает, что расположенные близко друг к другу объекты в пространстве признаков имеют схожие значения целевой переменной или принадлежат к одному классу.

Несколько лет назад увидеть DDoS-атаку было целым событием. Если такое и случалось, то инцидент тщательно анализировала целая команда специалистов, а каждая извлечённая крупица информации использовалась для обучения моделей, формирования новых факторов и улучшения подходов для защиты от новых потенциальных атак.
Но постепенно число атак увеличивалось, и в какой-то момент отбить очередной DDoS стало обычным делом. Только за прошедший 2023 год мы в Яндексе отразили 1002 атаки. В этом нам помогло инхаус-решение — Антиробот, который работает на уровне L7 сетевой модели OSI.
В этом посте я хочу рассказать о том, как работает, на чём обучается Антиробот и с какими атаками ему приходится иметь дело. А ещё расскажу, почему важно системно подходить к анализу каждой атаки и как ML помогает отражать их.

Дерево решений CART (Classification and Regressoin Tree) — алгоритм классификации и регрессии, основанный на бинарном дереве и являющийся фундаментальным компонентом случайного леса и бустингов, которые входят в число самых мощных алгоритмов машинного обучения на сегодняшний день. Деревья также могут быть не бинарными в зависимости от реализации. К другим популярным реализациям решающего дерева относятся следующие: ID3, C4.5, C5.0.

В данной статье даётся общее описание векторного представления вложений слов - модель word2vec. Также рассматривается пример реализации модели word2vec с использованием библиотеки PyTorch. Приведена реализация как архитектуры skip-gram так и CBOW.