Пять лет назад из обычного продакт-менеджмента я перешла в команду с дата-сайентистами. И весь процесс моей работы сильно изменился.
Раньше после определения потребностей пользователя я приходила к команде разработки с готовой задачей и дизайн-макетами. А после разработки забирала готовый продукт, чтобы отдать его в A/B-тест.
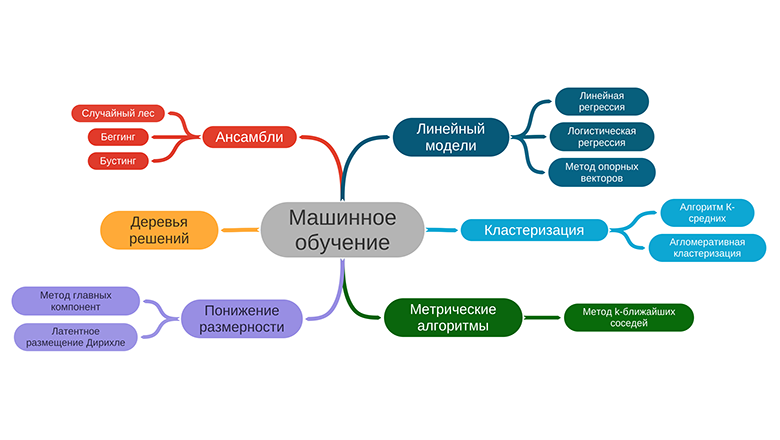
В ML все работает иначе. Команда включается уже на этапе исследования, погружается в бизнес-цели и техническую постановку задачи. Именно исследования занимают львиную долю времени дата-сайентистов, и только после начинается разработка.
Ну, или не начинается. Или разработка начинается, но совсем не той идеи, которая была вначале.
Я — Саша Пургина, руковожу развитием продуктов на основе данных в Lamoda Tech. В этой статье я расскажу на примере Lamoda, почему разработка ML-продуктов — это сложность и риск. И приведу примеры ошибок, когда хороший продакт в команде может увеличить шансы на успех, имея определенные знания и навыки.
Серебряной пули не ждите, но пара интересных мыслей должна найтись!