Если значительная часть бизнес логики Вашего приложения располагается в базе данных, вас наверняка посещала мысль о модульном тестировании хранимых процедур и функций. Опустим обсуждение вопроса о том, хорошо это или плохо — выносить логику в хранимые процедуры, и разберемся — как тестировать хранимый код. В этой статье я расскажу о tSqlt — замечательном бесплатном фреймворке unit-тестов с открытым исходным кодом для Sql Server.

Microsoft SQL Server *
Система управления реляционными базами данных
Решения разработки баз данных
5 мин
Добрый день! В процессе развития проекта приходится сталкиваться с проблемой производительности баз данных, т.к. объём данных растёт, и волей неволей выплывают проблемные участки.
В данном посте описаны не очень удачные решения, которые незаметны на ранних стадиях проекта. И решения, которые могут в дальнейшем в разы повысить производительность.
Пост больше рассчитан на более опытных разработчиков, которые уже возможно ищут решения, поэтому буду краток.
В данном посте описаны не очень удачные решения, которые незаметны на ранних стадиях проекта. И решения, которые могут в дальнейшем в разы повысить производительность.
Пост больше рассчитан на более опытных разработчиков, которые уже возможно ищут решения, поэтому буду краток.
Data Mining. Оптимизация заказов товаров в аптеке (аптечном пункте)
6 мин
В небольшом аптечном пункте существует потребность гибкой системы заказов лекарственных средств и пара-фармацевтических товаров чувствительной к постоянным колебаниям рынка. В рамках современной действительности одиночные аптечные пункты не обладают достаточными складскими помещениями (материальными комнатами), что накладывает свой отпечаток и заставляет человека, ответственного за заказы, делать их ежедневно из сводного прайс-листа по нескольким поставщикам, не допуская дублирования, по минимальным ценам, исключая товары с неподходящими сроками годности. При этом общая номенклатура составляет несколько десятков тысяч единиц.
Мы живем в современном мире, где рутинные операции за нас выполняет компьютер. Поэтому Вы можете сказать: «Давайте используем компьютер, и он сделает всю черную работу за нас!». «У вас же есть база данных, содержащая статистику продаж различных лекарств?» – продолжите Вы – «Так почему же не использовать эту статистику для прогноза продаж и создания автоматической заявки на требуемые препараты?»
Мы живем в современном мире, где рутинные операции за нас выполняет компьютер. Поэтому Вы можете сказать: «Давайте используем компьютер, и он сделает всю черную работу за нас!». «У вас же есть база данных, содержащая статистику продаж различных лекарств?» – продолжите Вы – «Так почему же не использовать эту статистику для прогноза продаж и создания автоматической заявки на требуемые препараты?»
Как отобразить 350 миллионов строк из базы данных на Web-форме
5 мин
Заголовок этой статьи — это краткое резюме того, что просил заказчик. Я в это время был в отпуске, а мой руководитель, не вдаваясь в детали, дал добро на реализацию. Хорошо отдохнув и выйдя на работу, я почувствовал себя в шкуре ёжика, который попал в туман в одном известном мультфильме. А ситуация требовала Волшебника изумрудного города.
Обзор компонентов управления памятью в SQL Server
7 мин
Материал посвящен описанию использования подсистемы памяти в MS SQL server. Данный обзор дает только общее представление о структуре управления. Следует помнить, что продукты компании Microsoft поставляются с закрытыми кодами и детальные сведения отсутствуют в общедоступных источниках (насколько удалось выяснить нам, если Вам удалось большее – сообщите, пожалуйста). Общий обзор необходим для понимания описываемых далее возможных проблем SQL server и используемых средств тестирования и измерения производительности.
Memory manager (ММ) является основным элементом, который управляет распределением памяти в SQL сервере. Данный компонент автоматически распределяет доступную SQL серверу память, снижая необходимость ручной настройки. После загрузки SQL ММ определяет первоначальный объем распределенной памяти и далее по мере изменения нагрузки динамически резервирует или освобождает оперативную память. Таким образом, ММ управляет взаимодействием SQL сервера с операционной системы в контексте управления памятью. Memory manager является частью SQLOS. Подробнее можно посмотреть здесь.
Memory manager
Memory manager (ММ) является основным элементом, который управляет распределением памяти в SQL сервере. Данный компонент автоматически распределяет доступную SQL серверу память, снижая необходимость ручной настройки. После загрузки SQL ММ определяет первоначальный объем распределенной памяти и далее по мере изменения нагрузки динамически резервирует или освобождает оперативную память. Таким образом, ММ управляет взаимодействием SQL сервера с операционной системы в контексте управления памятью. Memory manager является частью SQLOS. Подробнее можно посмотреть здесь.
Reporting Services 2008 под Sharepoint 2010
4 мин
В данной статье я хочу рассказать о моем опыте развертывания и использования SSRS 2008 в крупной компании. Процесс настройки и развертывания был 3 года назад, а сама система Reporting Services используется организацией уже 4 года.
Разработка для Microsoft SQL Server: Unix way
5 мин
Туториал
Привет, Хабр!
Средние и крупные проекты, в которых целиком, либо значительная часть бизнес-логики реализована в хранимых процедурах СУБД, имеют ряд неудобств по управлению кодом модулей. А именно:
Да, есть коммерческие продукты, решающие эти проблемы полностью или частично, однако, на взгляд автора, делают это не эффективно и не элегантно. В виду этого, реализовано отображение модулей и структуры БД на файловую систему, с помощью FUSE (Filesystem in Userspace), в проекте SQLFuse. Теперь последователи Unix way смогут пройти и здесь.
Рассмотрим последовательность действий для монтирования опытной БД.
Средние и крупные проекты, в которых целиком, либо значительная часть бизнес-логики реализована в хранимых процедурах СУБД, имеют ряд неудобств по управлению кодом модулей. А именно:
- Отсутствие управления версиями и отслеживание изменений кода;
- Сложности при синхронизация тестовой и рабочей инфраструктуры;
- Скудность средств по поиску, навигации и обзору кода.
Да, есть коммерческие продукты, решающие эти проблемы полностью или частично, однако, на взгляд автора, делают это не эффективно и не элегантно. В виду этого, реализовано отображение модулей и структуры БД на файловую систему, с помощью FUSE (Filesystem in Userspace), в проекте SQLFuse. Теперь последователи Unix way смогут пройти и здесь.
Рассмотрим последовательность действий для монтирования опытной БД.
Как SQL Server каждые два-три часа переключался на использование не оптимального плана выполнения запроса
3 мин
Последние пару дней работал над интересной задачей и хотел бы поделиться интересным опытом с сообществом.
В чём проявляется проблема:
Запускаю хранимую процедуру (хранимку) по выборке данных для отчета — выполняется три секунды, смотрю профайлером на бою — у пользователей те же результаты. Но проходит три часа и та же хранимка, с теми же параметрами выполняется уже 2 минуты, и аналогично у пользователей. Причём данные в используемые таблицы не вставлялись/удалялись, окружение не меняли и админы не делали настроек.
В чём проявляется проблема:
Запускаю хранимую процедуру (хранимку) по выборке данных для отчета — выполняется три секунды, смотрю профайлером на бою — у пользователей те же результаты. Но проходит три часа и та же хранимка, с теми же параметрами выполняется уже 2 минуты, и аналогично у пользователей. Причём данные в используемые таблицы не вставлялись/удалялись, окружение не меняли и админы не делали настроек.
In-Memory OLTP в SQL Server 2014. Часть II
9 мин
В первой части мы кратко рассмотрели основные возможности SQL Server по in-memory обработке применительно к аналитическим и транзакционным и приложениям, сконцентрировавшись на последних, поскольку in-memory OLTP (Hekaton) является наиболее существенным нововведением в SQL Server 2014. В данной статье мы продолжим обзор функциональности Гекатона на примере ранее созданной БД.
In-Memory OLTP в SQL Server 2014. Часть I
9 мин
Функциональность In-Memory OLTP (проект Hekaton) призвана ускорить обработку типовых OLTP-операций в SQL Server. Как известно, нагрузку, приходящуюся на сервер баз данных, будь то Microsoft SQL Server или Oracle/MySQL или SAP/Sybase или IBM DB2 и т.д., можно условно разбить на два класса: сбор данных и анализ того, что собрали, потому что зачем в противном случае было собирать? Первый класс задач называется OLTP (On-Line Transactional Processing). Для него характерны короткие обновляющие транзакции, затрагивающие относительно небольшое число таблиц в базе. Примеры таких приложений — операционный день в банке, биллинг в телекоме и т.д. Второй класс задач называется OLAP (On-Line Analytical Processing) и характеризуется массивным длительным чтением, охватывающим значительное количество таблиц и собирающим из них, как правило, по максимуму записей, изобилующим предикатами связывания, сортировки, группирования, агрегатными функциями и т.д. Как правило, структуры данных для разных классов задач разделяют, чтобы не мешали друг другу, и если первая структура базы строится с учетом многочисленных правил Кодда, то вторая, напротив, денормализована и выполняется по схеме «звезда (снежинка)».
Устремление СУБД в память проявилось в начале нового тысячелетия, когда выяснилось, что несмотря на закон Мура тактовая частота и быстродействие процессоров растут отнюдь не по экспоненте, а наоборот, выходят на плоскую прямую насыщения невзирая на ILP и прочие ухищрения. В то же время цены на оперативную память, когда-то неприлично дорогую, катастрофически снижаются и по сравнению с 90-ми упали в тысячи раз. Ага, сказали себе производители серверов баз данных. В 2005-м Oracle прикупил in-memory СУБД TimesTen, IBM в 2007-м — компанию Solid, а в Microsoft в данном случае ничего со стороны брать не стали, потому что решили воспитать в своем коллективе.
Устремление СУБД в память проявилось в начале нового тысячелетия, когда выяснилось, что несмотря на закон Мура тактовая частота и быстродействие процессоров растут отнюдь не по экспоненте, а наоборот, выходят на плоскую прямую насыщения невзирая на ILP и прочие ухищрения. В то же время цены на оперативную память, когда-то неприлично дорогую, катастрофически снижаются и по сравнению с 90-ми упали в тысячи раз. Ага, сказали себе производители серверов баз данных. В 2005-м Oracle прикупил in-memory СУБД TimesTen, IBM в 2007-м — компанию Solid, а в Microsoft в данном случае ничего со стороны брать не стали, потому что решили воспитать в своем коллективе.
Как развернуть отказоустойчивый кластер MS SQL Server 2012 на Windows Server 2012R2 для новичков
4 мин
Туториал
Данный топик будет интересен новичкам. Бывалые гуру и все, кто уже знаком с этим вопросом, вряд ли найдут что-то новое и полезное. Всех остальных милости прошу под кат.
Задача, которая стоит перед нами, – обеспечить бесперебойную работу и высокую доступность базы данных в клиент-серверном варианте развертывания.
Тип конфигурации — active/passive.
P.S. Вопросы резервирования узлов не относящихся к MSSQL не рассмотрены.
Задача, которая стоит перед нами, – обеспечить бесперебойную работу и высокую доступность базы данных в клиент-серверном варианте развертывания.
Тип конфигурации — active/passive.
P.S. Вопросы резервирования узлов не относящихся к MSSQL не рассмотрены.
Практическое применение Master Data Services в MS SQL Server 2012
8 мин
В этой статье я хотел бы поделиться своим первым профессиональным опытом применения Master Data Services (MDS) в MS SQL Server 2012. До недавнего времени я был знаком с этим продуктом, входящим в состав MS SQL Server 2012 (Business Intelligence and Enterprise editions), только в теории и ждал удачного случая, чтобы проверить его на практике, и вот такой случай представился.

Find invalid objects
7 мин
Туториал
 В обязанности администратора баз данных входит много разных задач, которые, в основном, направлены на поддержку работоспособности и целостности базы данных. И если целостность данных можно проверить через команду CHECKDB, то с поиском невалидных объектов в схеме не все так гладко.
В обязанности администратора баз данных входит много разных задач, которые, в основном, направлены на поддержку работоспособности и целостности базы данных. И если целостность данных можно проверить через команду CHECKDB, то с поиском невалидных объектов в схеме не все так гладко.Если проводить аналогии с Oracle, то в SQL Server нельзя так же легко получить список невалидных объектов:
SELECT owner, object_type, object_name
FROM all_objects
WHERE status = 'INVALID'
В большинстве ситуаций, узнать о том, что скриптовый объект является невалидным, можно только при его выполнении. Конечно, такое положение дел, может не всех устроить, поэтому предлагаю написать скрипт по поиску невалидных объектов в базе данных.
Ближайшие события







Firebird Conf: конференция для разработчиков и администраторов СУБД Firebird
6 июня
09:00 – 20:00
Москва
Смотрите онлайн-трансляцию конференции Data Platform Day о платформе SQL Server 2014
1 мин
Сегодня 24 апреля в 10:00 по московскому времени приглашаем вас подключиться к онлайн трансляции ключевого события года в мире серверных и облачный решений – конференции Data Platform Day.

В рамках глобальной стратегии развития Microsoft Cloud OS** Вам будет представлена универсальная платформа SQL Server 2014, устанавливающая новые стандарты в области хранения и управления данными любого типа и объема.
Ведущие эксперты Microsoft и компаний-партнеров продемонстрируют:
В рамках глобальной стратегии развития Microsoft Cloud OS** Вам будет представлена универсальная платформа SQL Server 2014, устанавливающая новые стандарты в области хранения и управления данными любого типа и объема.
Ведущие эксперты Microsoft и компаний-партнеров продемонстрируют:
- новейшие технологии, обеспечивающие работу критически важных приложений;
- современные решения по сбору, анализу и виртуализации данных, в том числе по работе с Большими Данными (Big Data);
- новые возможности по построению гибридных ИТ-систем.
Подключиться к онлайн-трансляции
Как заполнить базу данных MS SQL разнородными случайными данными или 17 часов ожидания
7 мин
Доброго дня,
Перед разработчиком часто возникает задача провести тест базы данных на больших объемах данных, но откуда взять эти самые данные? Ведь всем известно, что структура базы может достигать over 50 таблиц, которые не очень хочется заполнять руками. А если подумать о внешних ключах и составных первичных ключах значения которых связаны с другими таблицами, то голова начинает нагреваться пропорционально старому AMD с отключенным охлаждением.
В интернете существует много решений заполнения базы данный случайными значениями с использованием средств .NET, C++, Java и.д. В данной статье будет освещена тема заполнения базы данных случайными значениями средствами T-SQL под управлением MS SQL Server.
Перед разработчиком часто возникает задача провести тест базы данных на больших объемах данных, но откуда взять эти самые данные? Ведь всем известно, что структура базы может достигать over 50 таблиц, которые не очень хочется заполнять руками. А если подумать о внешних ключах и составных первичных ключах значения которых связаны с другими таблицами, то голова начинает нагреваться пропорционально старому AMD с отключенным охлаждением.
В интернете существует много решений заполнения базы данный случайными значениями с использованием средств .NET, C++, Java и.д. В данной статье будет освещена тема заполнения базы данных случайными значениями средствами T-SQL под управлением MS SQL Server.
32-битный Excel и 64-битный SQL Server
6 мин
Прочитать в SQL Server табличку из Excel… В самом деле, что может быть проще? Для этого существует масса возможностей. Есть инструмент Integration Services, который бывшие DTS, есть мастер импорта/экспорта, который «за сценой» то же самое, можно по-быстрому сваять собственное ADO.NET-приложение, наконец, если неохота стрелять из пушек по воробьям, можно воспользоваться механизмом прилинкованных серверов, известным, как DTS, еще со времен семерки, который позволяет легко и элегантно увидеть теоретически любой ODBC/OLE DB-достижимый источник в виде таблицы (совокупности таблиц) или результата непосредственного (ad hoc) запроса. Так было до тех пор, пока 64-битная архитектура не перестала быть чем-то из области hi end и пришла на ноутбуки разработчиков и пользователей. Обычный пользователь, наверное, все-таки вряд ли будет ставить себе сервер баз данных, но для разработчика отнюдь не экзотична ситуация, когда на одной х64-машине уживаются 64-битный SQL Server с 32-битным MS Office. В этом случае создание прилинкованного сервера на Excel или Access вызывает проблему, потому что драйвера для них, понятно, 32-битные, которые SQL Server, будучи 64-битным, не понимает. Нет у него в списке известных ему провайдеров ничего похожего, хотя офис со всеми прибамбасами, включая connectivity, на компе стоит.
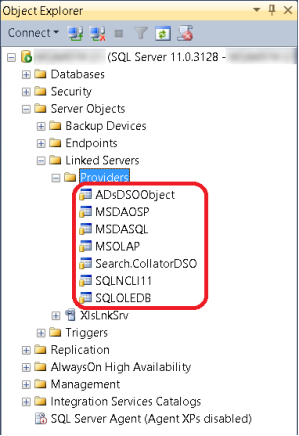
Рис.1
Соответственно, попытка использовать прилинкованный сервер на Excel, как описано в документации, приводит к ошибке Msg 7302, Level 16, State 1, Line 1
Cannot create an instance of OLE DB provider «Microsoft.ACE.OLEDB.12.0» for linked server…
Возникает извечный вопрос «что делать»?
Рис.1
Соответственно, попытка использовать прилинкованный сервер на Excel, как описано в документации, приводит к ошибке Msg 7302, Level 16, State 1, Line 1
Cannot create an instance of OLE DB provider «Microsoft.ACE.OLEDB.12.0» for linked server…
Возникает извечный вопрос «что делать»?
Вышла финальная версия Microsoft SQL Server 2014
1 мин
Сегодня стала доступна новая версия Microsoft SQL Server.
Сбор статистики производительности и вывод результатов в SSMS в виде пользовательских отчетов
5 мин
Туториал
Итак, у нас появилась задача по сбору статистики производительности SQl-сервера и дальнейший анализ результатов. Для чего это надо? Например, вы хотите перенести с одного сервера на другой некую базу данных, и вам надо просчитать производительность до переноса и после.
Чуть подробнее. Есть некий сервер, назовем его server-sql-001, на котором крутятся базы данных CRM и ERP компании. И есть еще сервер, назовем его server-sql-1c, на котором крутятся БД 1С. Server-sql-001 – это новый брендовый сервер, с современными характеристиками и т.д. А server-sql-1c – это довольно средний по современным меркам сервер. И вот, вся бухгалтерия жаждет переехать на server-sql-001, дабы наступило им счастье, увеличилась производительность и скорость работы отличной желтой программы. Вот и встала задача проверить, а правда ли наступит всем счастье? Или же после переезда пострадает производительность и CRM и ERP и 1С? Вот один из примеров, по которым нам необходимо собрать и проанализировать статистику.
Да, можно средствами системного монитора собрать всю необходимую статистику в excel-файл, затем построить графики и т.д. Но что если сбор статистики продолжает неделю, месяц? А еще с интервалом 10 секунд? Удобно будет работать с таким файлом? Ну смотрите сами.
Чуть подробнее. Есть некий сервер, назовем его server-sql-001, на котором крутятся базы данных CRM и ERP компании. И есть еще сервер, назовем его server-sql-1c, на котором крутятся БД 1С. Server-sql-001 – это новый брендовый сервер, с современными характеристиками и т.д. А server-sql-1c – это довольно средний по современным меркам сервер. И вот, вся бухгалтерия жаждет переехать на server-sql-001, дабы наступило им счастье, увеличилась производительность и скорость работы отличной желтой программы. Вот и встала задача проверить, а правда ли наступит всем счастье? Или же после переезда пострадает производительность и CRM и ERP и 1С? Вот один из примеров, по которым нам необходимо собрать и проанализировать статистику.
Да, можно средствами системного монитора собрать всю необходимую статистику в excel-файл, затем построить графики и т.д. Но что если сбор статистики продолжает неделю, месяц? А еще с интервалом 10 секунд? Удобно будет работать с таким файлом? Ну смотрите сами.
Передача табличных данных из хранимой процедуры
11 мин
Речь пойдет о методах получения результатов работы процедуры в виде таблиц для последующей работы с ними в SQL. Думаю, большинство здесь изложенного может пригодиться только в приложениях со сложной SQL логикой и объемными процедурами. Не берусь утверждать, что данные методы самые эффективные. Это всего лишь то, что я использую в своей работе. Всё это работает под Microsoft SQL Server 2008.
Тем, кто знаком с темой предлагаю пролистать пост до пятого метода.
Тем, кто знаком с темой предлагаю пролистать пост до пятого метода.
Работа с SQL Server в сценариях гибридного Облака. Часть 2
5 мин
Как правило, в публичном Облаке хранится обезличенная информация, а персонализируюшая часть — в частном. В связи с чем возникает вопрос — как скомбинировать обе части, чтобы по запросу пользователя выдать единый результат? Предположим, имеется таблица клиентов, поделенная вертикально. Обезличенные колонки отнесены в таблицу, расположенную в Windows Azure SQL Database, а колонки с чувствительной информацией (напр., ФИО) остались в локальном SQL Server. Нужно связать обе таблицы по ключу CustomerID. Поскольку они лежат в разных базах на разных серверах, использование SQL-оператора с JOIN не проходит. В качестве возможного решения мы рассмотрели в предыдущем материале сценарий, при котором связывание происходило на локальном SQL Server. Он выступал в качестве своеобразной точки входа для приложений, и облачный SQL Server был заведен на нем как прилинкованный. В этом материале мы рассмотрим случай, когда и локальный, и облачный серверы с точки зрения приложения равноправны, а объединение данных происходит непосредственно в нем, т.е. на уровне бизнес-логики.