В эту пятницу, 18 мая, состоится профессиональная конференция веб-разработчиков DevConf 2018. Приглашаем принять участие. Очень кратко про программу:
DevConf::BackEnd: Агрегатное мышление, переписывание проекта с Drupal 8 на Yii 2, Yii 2.1, PHP и фреймворки, Service Oriented Architecture, отправка уведомлений, sample profiling, open tracing, Business Intelligence.
DevConf::FrontEnd: HOC в React, WebRTC: видеозвонки из браузера, Headless Chrome, архитектура большого легаси проекта, JSON API, Фреймворк для индивидуального дизайна, Тестируй это, Node.js и бесплатный митап LuaInMoscow.
DevConf::Storage: MySQL/MariaDB/Percona Server: что нового, логическая репликация в PostgreSQL, SphinxSearch, ClickHouse, ProxySQL для отказоустойчивости MySQL, обзорный доклад про разные механизмы сжатия данных от Андрея Аксенова.
DevConf::BackEnd: Агрегатное мышление, переписывание проекта с Drupal 8 на Yii 2, Yii 2.1, PHP и фреймворки, Service Oriented Architecture, отправка уведомлений, sample profiling, open tracing, Business Intelligence.
DevConf::FrontEnd: HOC в React, WebRTC: видеозвонки из браузера, Headless Chrome, архитектура большого легаси проекта, JSON API, Фреймворк для индивидуального дизайна, Тестируй это, Node.js и бесплатный митап LuaInMoscow.
DevConf::Storage: MySQL/MariaDB/Percona Server: что нового, логическая репликация в PostgreSQL, SphinxSearch, ClickHouse, ProxySQL для отказоустойчивости MySQL, обзорный доклад про разные механизмы сжатия данных от Андрея Аксенова.

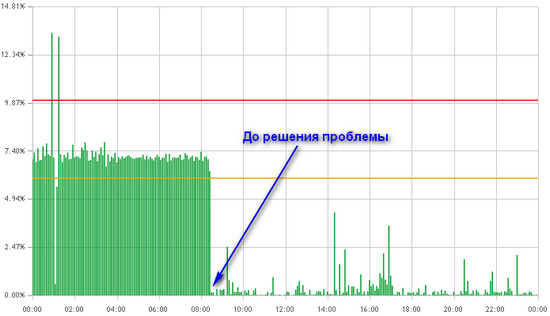




 В этой статье я решил собрать сборную солянку из советов о том, как разрабатывать высоконагруженные сервисы, полученных практическим путем. Для каждого совета я постараюсь приводить небольшое обоснование, без подробностей (иначе статья бы получилась бы сравнима по размеру с войной и миром). Поскольку обоснований я буду приводить не очень много, не стоит воспринимать эту статью, как догму — в каждом конкретном случае приведенные здесь советы могут быть вредны. Всегда думайте своей головой перед тем, как что-то делать.
В этой статье я решил собрать сборную солянку из советов о том, как разрабатывать высоконагруженные сервисы, полученных практическим путем. Для каждого совета я постараюсь приводить небольшое обоснование, без подробностей (иначе статья бы получилась бы сравнима по размеру с войной и миром). Поскольку обоснований я буду приводить не очень много, не стоит воспринимать эту статью, как догму — в каждом конкретном случае приведенные здесь советы могут быть вредны. Всегда думайте своей головой перед тем, как что-то делать.