
Крутой varanio буквально на прошлой неделе прочитал на DevConf забойный доклад для всех кто пересел на Посгрес с MySQL, но до сих пор не использует новую базу данных в полной мере. По мотивам выступления родилась эта публикация.
Мы рады сообщить, что подготовка к PG Day'17 Russia идет полным ходом! Мы опубликовали полное расписание предстоящего мероприятия. Приглашаем всех желающих прийти и похоливарить с Антоном лично
Поскольку доклад на DevConf вызвал в целом положительные отзывы, я решил оформить его в виде статьи для тех, кто по каким-то причинам не смог присутствовать на конференции.
Почему вообще возникла идея такого доклада? Дело в том, что PostgreSQL сейчас явно хайповая технология, и многие переходят на эту СУБД. Иногда — по объективным причинам, иногда — просто потому что это модно.
Но сплошь и рядом складывается такая ситуация, когда какой-нибудь условный программист Вася вчера писал на MySQL, а сегодня вдруг начал писать на Посгресе. Как он будет писать? Да в целом также, как и раньше, используя лишь самый минимальный набор возможностей новой базы. Практика показывает, что проходят годы, прежде чем СУБД начинает использоваться более менее полноценно.


 17 июня в Москве, Измайлово пройдет конференция
17 июня в Москве, Измайлово пройдет конференция 









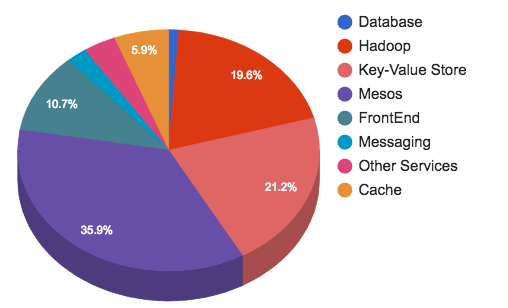

 В этой статье мы рассмотрим способы создания поиска по базе туров (тур из себя представляет набор из отеля и перелета) и рассмотрим две опции —
В этой статье мы рассмотрим способы создания поиска по базе туров (тур из себя представляет набор из отеля и перелета) и рассмотрим две опции —  В далекие времена, до фейсбука и гугла, когда 32 мегабайта RAM было дофига как много, security была тоже… немножко наивной. Вирусы выдвигали лоток CD-ROM-а и играли Янки Дудль. Статья «Smashing the stack for fun and profit» уже была задумана, но еще не написана. Все пользовались telnet и ftp, и только особо продвинутые параноики знали про ssh.
В далекие времена, до фейсбука и гугла, когда 32 мегабайта RAM было дофига как много, security была тоже… немножко наивной. Вирусы выдвигали лоток CD-ROM-а и играли Янки Дудль. Статья «Smashing the stack for fun and profit» уже была задумана, но еще не написана. Все пользовались telnet и ftp, и только особо продвинутые параноики знали про ssh.