
В последние пол года у меня создается двойственное впечатление от использования MySQL. Не хочется давать оценку работе проведённой Oracle, как управляющей компанией, но очень хочется высказаться по поводу того, что уже 5 релизов не могу дождаться стабильной версии MySQL, которая позволит нормально работать.
Поприветствуйте вашего старого нового друга
4 мин
Перевод
Сегодня разнообразные открытые СУБД встают лицом к лицу против массивных, неуклюжих и дорогостоящих «корпоративных» систем, таких как SQL Server и Oracle. Часто открытые СУБД прекрасно работают лучше закрытых систем, не уступая даже в функциональных возможностях.
Из всех открытых систем управления базами данных самой умной, производительной и функциональной системой является Postgres, которая заслуженно привлекает всё больше и больше внимания.
Из всех открытых систем управления базами данных самой умной, производительной и функциональной системой является Postgres, которая заслуженно привлекает всё больше и больше внимания.
MySQL в миллион раз быстрее MemSQL
2 мин
Пару дней назад по мировой технологической прессе распространился пиар MemSQL — базы данных нового поколения от Никиты Шамгунова (shamg), которая якобы показывает скорость в 30 раз выше, чем MySQL и при этом «надёжна по дефолту» (durable by default), как сказано у них на сайте.
Представители MySQL не снизошли до ответа на эти очевидные маркетинговые лозунги. Но вот бывший сотрудник MySQL, Домас Митузас (Domas Mituzas), ныне специалист по базам данных в Facebook и Wikipedia, всё-таки не выдержал и решил разобраться, как именно нас обманывают — и ответить тем же, то есть показать примеры, где MemSQL работает в сотни, тысячи и даже миллион раз медленнее, чем MySQL.
Представители MySQL не снизошли до ответа на эти очевидные маркетинговые лозунги. Но вот бывший сотрудник MySQL, Домас Митузас (Domas Mituzas), ныне специалист по базам данных в Facebook и Wikipedia, всё-таки не выдержал и решил разобраться, как именно нас обманывают — и ответить тем же, то есть показать примеры, где MemSQL работает в сотни, тысячи и даже миллион раз медленнее, чем MySQL.
Оптимизация связки Nginx, Apache, PHP, MySql
9 мин
Неожиданно поступила задача разобраться почему определенный сайт не работает столь быстро сколь хочется. В основе его CakePHP, в связке с Apache и MySQL. В статье описание процесса поиска узких мест и приведение в порядок на столько, на сколько это возможно.
Название сайта светить не буду — думаю, программисты сами узнают. Скажу лишь, что это приложение для социальной сети нагрузкой 70-150 тысяч посетителей в обычное время. Все усложняется тем, что периодически производится рекламная рассылка, которая привлекает около 200-300 тысяч посетителей за пару часов.
Итак, под катом описание всей борьбы на протяжении 4 дней.
Название сайта светить не буду — думаю, программисты сами узнают. Скажу лишь, что это приложение для социальной сети нагрузкой 70-150 тысяч посетителей в обычное время. Все усложняется тем, что периодически производится рекламная рассылка, которая привлекает около 200-300 тысяч посетителей за пару часов.
Итак, под катом описание всей борьбы на протяжении 4 дней.
Смешная уязвимость в MySQL под Linux 64-bit
2 мин
В субботу координатор по безопасности проекта MariaDB Сергей Голубчик (petropavel) сообщил об интересной уязвимости в MySQL/MariaDB до версий 5.1.61, 5.2.11, 5.3.5, 5.5.22.
Суть в том, что при подключении пользователя MariaDB/MySQL вычисляется токен (SHA от пароля и хэша), который сравнивается с ожидаемым значением. При этом функция memcmp() должна возвращать значение в диапазоне -128..127, но на некоторых платформах (похоже, в glibc в Linux с оптимизацией под SSE) возвращаемое значение может выпадать из диапазона.
В итоге, в 1 случае из 256 процедура сравнения хэша с ожидаемым значением всегда возвращает значение true, независимо от хэша. Другими словами, система уязвима перед случайным паролем с вероятностью 1/256.
Суть в том, что при подключении пользователя MariaDB/MySQL вычисляется токен (SHA от пароля и хэша), который сравнивается с ожидаемым значением. При этом функция memcmp() должна возвращать значение в диапазоне -128..127, но на некоторых платформах (похоже, в glibc в Linux с оптимизацией под SSE) возвращаемое значение может выпадать из диапазона.
В итоге, в 1 случае из 256 процедура сравнения хэша с ожидаемым значением всегда возвращает значение true, независимо от хэша. Другими словами, система уязвима перед случайным паролем с вероятностью 1/256.
Простая замена phpMyAdmin для гиков
2 мин
Довольно часто возникает ситуация, когда надо быстренько запустить пару запросов к MySQL базе у клиента на сервере. При этом есть только FTP и параметры соединения с СУБД. Самый простой выход — загрузить туда phpMyAdmin, ну а дальше дело техники. Обычно все это проиcходит на фоне того, что у клиента уже установлена какая-то CMS — WordPress, Drupal, Joomla…
Я люблю простые, красивые и удобные вещи. Я тепло отношусь к phpMyAdmin но в 90% моих Use Cases мне он не нужен. Нужно что-то простое. В идеале такое, что можно просто залить на сервер и открыть в браузере — не настраивая.
Пара вечеров и пакет готов.
Я люблю простые, красивые и удобные вещи. Я тепло отношусь к phpMyAdmin но в 90% моих Use Cases мне он не нужен. Нужно что-то простое. В идеале такое, что можно просто залить на сервер и открыть в браузере — не настраивая.
Пара вечеров и пакет готов.
Девушка с татуировкой ANSI
2 мин
Специалисты по СУБД с сайта Oracle WTF заинтересовались, что же такое печатает в терминале юный хакер в фильме «Девушка с татуировкой дракона». По сюжету, это были запросы к базе данных полицейского отделения, с помощью которых она раскрыла убийства 40-летней давности.

10 лучших инструментов для разработки и администрирования MySQL
6 мин
Многие компании создают различные многофункциональные приложения для облегчения управления, разработки и администрирования баз данных.
Большинство реляционных баз данных, за исключением MS Access, состоят из двух отдельных компонентов: «back-end», где хранятся данные и «front-end» — пользовательский интерфейс для взаимодействия с данными. Этот тип конструкции достаточно умный, так как он распараллеливает двухуровневую модель программирования, которая отделяет слой данных от пользовательского интерфейса и позволяет сконцентрировать рынок ПО непосредственно на улучшении своих продуктов. Эта модель открывает двери для третьих сторон, которые создают свои приложения для взаимодействия с различными базами данных.
В Интернете каждый может найти много продуктов для разработки и администрирования баз данных MySQL. Мы решили собрать 10 самых популярных инструментов в одной статье, чтобы вы смогли сэкономить свое время.
Большинство реляционных баз данных, за исключением MS Access, состоят из двух отдельных компонентов: «back-end», где хранятся данные и «front-end» — пользовательский интерфейс для взаимодействия с данными. Этот тип конструкции достаточно умный, так как он распараллеливает двухуровневую модель программирования, которая отделяет слой данных от пользовательского интерфейса и позволяет сконцентрировать рынок ПО непосредственно на улучшении своих продуктов. Эта модель открывает двери для третьих сторон, которые создают свои приложения для взаимодействия с различными базами данных.
В Интернете каждый может найти много продуктов для разработки и администрирования баз данных MySQL. Мы решили собрать 10 самых популярных инструментов в одной статье, чтобы вы смогли сэкономить свое время.
Кластерные и «обычные» индексы MySQL (InnoDB)
5 мин
Все мы помним хрестоматийное объяснение «что такое индексы в БД и как они облегчают задачи поиска нужных строк». Уверен, у большинства из вас перед глазами встаёт нечто подобное:
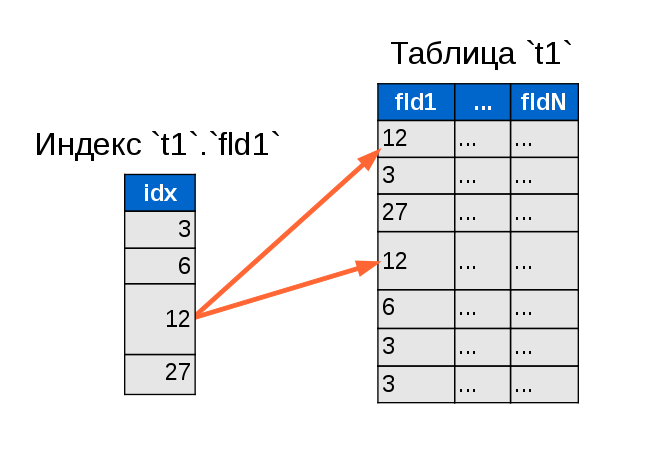
И сразу становится очевидно, насколько меньше данных нужно перелопатить для поиска двух-трёх нужных строк. Гениально. Просто. Понятно.
И лично мне всегда казалось, что улучшать эту схему некуда… Пока я не познакомился с кластерными индексами. Оказалось, что всё не так уж радужно с «обычными» индексами.
Итак, что же такое кластерный индекс, чем он лучше некластерного, и как с ним обстоит дело у MySQL.
И сразу становится очевидно, насколько меньше данных нужно перелопатить для поиска двух-трёх нужных строк. Гениально. Просто. Понятно.
И лично мне всегда казалось, что улучшать эту схему некуда… Пока я не познакомился с кластерными индексами. Оказалось, что всё не так уж радужно с «обычными» индексами.
Итак, что же такое кластерный индекс, чем он лучше некластерного, и как с ним обстоит дело у MySQL.
Оптимизация ORDER BY — о чем многие забывают
2 мин
На тему оптимизации MySQL запросов написано очень много, все знают как оптимизировать SELECT, INSERT, что нужно джоинить по ключу и т.д. и т.п.
Но есть один момент, тоже неоднократно описанный во всех мануалах, но почему-то про него все забывают.
Но есть один момент, тоже неоднократно описанный во всех мануалах, но почему-то про него все забывают.
Резервное копирование данных в MySQL
5 мин
Резервное копирование базы данных — это такая штука, которую вечно приходится настраивать для уже работающих проектов прямо на «живых» production-серверах.
Подобная ситуация легко объяснима. В самом начале любой проект еще пуст и там просто нечего копировать. В фазе бурного развития головы немногочисленных разработчиков заняты исключительно прикручиванием фишек и рюшек, а также фиксом критических багов с дедлайном «позавчера». И только когда проект «взлетит», приходит осознание, что главная ценность системы — это накопленная база данных, и её сбой станет катастрофой.
Эта обзорная статья — для тех, чьи проекты уже достигли этой точки, но жареный петух ещё не клюнул.
Подобная ситуация легко объяснима. В самом начале любой проект еще пуст и там просто нечего копировать. В фазе бурного развития головы немногочисленных разработчиков заняты исключительно прикручиванием фишек и рюшек, а также фиксом критических багов с дедлайном «позавчера». И только когда проект «взлетит», приходит осознание, что главная ценность системы — это накопленная база данных, и её сбой станет катастрофой.
Эта обзорная статья — для тех, чьи проекты уже достигли этой точки, но жареный петух ещё не клюнул.
Оптимизация запросов MySQL с использованием пользовательских переменных
14 мин
Введение. В современном мире существует большое количество задач, в рамках которых приходится обрабатывать большие массивы однотипных данных. Яркими примерами являются системы для анализа биржевых котировок, погодных условий, статистики сетевого трафика. Многие из этих систем используют различные реляционные базы данных, в таблицах которых содержатся такие объемы данных, что правильное составление и оптимизация запросов к этим таблицам становится просто необходимым для нормального функционирования системы. В этой статье описаны методы решения ( и сравнительные временные характеристики используемых методов ) нескольких задач по получению данных из таблиц СУБД MySQL, содержащих статистику о проходящем через маршрутизаторы одного из крупных российских сетевых провайдеров сетевом трафике. Интенсивность потока данных, поступающего с главного маршрутизатора такова, что ежесуточно в таблицы базы данных используемой системы мониторинга сетевого трафика поступает в среднем от 400 миллионов до миллиарда записей, содержащих информацию о транзакциях TCP/IP (рассматриваемый маршрутизатор экспортирует данные по протоколу netflow). В качестве СУБД для системы мониторинга используется MySQL.
Все врут или почему в MySQL лучше не использовать партиции
8 мин
Начиная с версии 5.1 в MySQL появилась такая полезная фича как партиции. Конечно же большинство разработчиков БД сразу не побрезговали ей воспользоваться. Спустя пару лет работы я наконец пожал плоды всей ущербности реализации этой технологии специалистами MySQL AB …
Ближайшие события



Firebird Conf: конференция для разработчиков и администраторов СУБД Firebird
6 июня
09:00 – 20:00
Москва

Стратегия оптимизации веб-проекта с использованием MySQL
5 мин
Введение
В жизни любого крупного веб-проекта, особенно на PHP, но, в целом, это касается любого серверного ЯП, пригодного для веб-разработки, обычно наступает понимание, что «так дальше жить нельзя», и что настал момент, когда нужно провести оптимизацию работы сайта, чтобы он перестал тормозить (хотя бы на production).
Интересно, что, как правило, даже тяжелые фреймворки (вроде Symfony или RoR) на «медленных» языках, в production-окружении работают достаточно сносно по скорости, а основные «тормоза» вызываются SQL-запросами и неграмотным кешированием (к примеру, инициализация достаточно сложной и большой конфигурации проекта на Symfony занимает около 80 мс, а времена исполнения страницы, при этом, иногда достигают секунды и более).
Если вы смогли определить, что это — ваш случай, и ваш проект на MySQL, то эта статья может вам помочь принять конкретные меры и исправлению ситуации с закреплением результата и предотвращением возникновения откровенных проблем с СУБД впоследствии.
8123 байта хватит каждому
2 мин
Сегодня во время перевода одного сайта с таблиц MyISAM на InnoDB, у последних выяснилась одна интересна особенность. Запрос на изменение движка для двух таблиц возвращал странную ошибку «Got error 139 from storage engine». После поиска информации на эту тему, было выяснено, что данная ошибка возникает тогда, когда какая-либо строка таблицы не вмещается в половину страницы памяти, с которыми работает MySQL. Страницы эти равны 16 Кб, а половина, стало быть, 8 Кб.
Само по себе ограничение довольно странное, но на первый взгляд кажется трудно достижимым, ведь как известно, MySQL хранят текстовые данные в хранилище, отдельном от табличных строк. Оказалось, что это верно только на половину. На самом деле InnoDB хранит в отдельном хранилище только «излишки», к коим он не относит первые 768 байтов каждого текстового поля. Т.е. любой текст будет отъедать от длины строки столько байт, сколько он содержит, но не больше 768. Несложно подсчитать, что максимальное число текстовых полей длиной от 768 байт, которое можно безопасно хранить в одной таблице — 10. И действительно, если запустить пример, все пройдет гладко. Но стоит увеличить количество полей хотя бы на одно, и мы получим ту же ошибку, что и в начале.
Само по себе ограничение довольно странное, но на первый взгляд кажется трудно достижимым, ведь как известно, MySQL хранят текстовые данные в хранилище, отдельном от табличных строк. Оказалось, что это верно только на половину. На самом деле InnoDB хранит в отдельном хранилище только «излишки», к коим он не относит первые 768 байтов каждого текстового поля. Т.е. любой текст будет отъедать от длины строки столько байт, сколько он содержит, но не больше 768. Несложно подсчитать, что максимальное число текстовых полей длиной от 768 байт, которое можно безопасно хранить в одной таблице — 10. И действительно, если запустить пример, все пройдет гладко. Но стоит увеличить количество полей хотя бы на одно, и мы получим ту же ошибку, что и в начале.
Как MySQL оптимизирует ORDER BY, LIMIT и DISTINCT
16 мин
Есть задачи, которые в рамках реляционных СУБД не имеют универсальных решений и для того чтобы получить хоть какой-то приемлемый результат, приходится придумывать целый набор костылей, который ты потом гордо называешь “Архитектура”. Не так давно мне как раз встретилась именно такая.

Предположим, имеется некоторые сущности А и Б, связанные между собой по принципу One-to-Many. Количество экземпляров данных сущностей достаточно велико. При отображении сущностей для пользователя необходимо применить ряд независимых критериев, как для сущности А так и для сущности Б. Причем результатом применения критериев являются множества достаточно большой мощности — порядка нескольких миллионов записей. Критерии фильтрации и принцип сортировки задается пользователем. Как (я бы ещё спросил: Зачем им миллионы записей на одном экране? — но говорят надо) показать все это пользователю за время 0 секунд?
Решать такие задачи всегда интересно, но их решение сильно зависит от СУБД, под управлением которой крутится твоя база данных. Если у тебя в рукаве козырной туз в виде Oracle, то есть шанс, что эти костыли он подставит сам. Но спустимся на землю — у нас есть только MySQL, так что придется почитать теорию.
Предположим, имеется некоторые сущности А и Б, связанные между собой по принципу One-to-Many. Количество экземпляров данных сущностей достаточно велико. При отображении сущностей для пользователя необходимо применить ряд независимых критериев, как для сущности А так и для сущности Б. Причем результатом применения критериев являются множества достаточно большой мощности — порядка нескольких миллионов записей. Критерии фильтрации и принцип сортировки задается пользователем. Как (я бы ещё спросил: Зачем им миллионы записей на одном экране? — но говорят надо) показать все это пользователю за время 0 секунд?
Решать такие задачи всегда интересно, но их решение сильно зависит от СУБД, под управлением которой крутится твоя база данных. Если у тебя в рукаве козырной туз в виде Oracle, то есть шанс, что эти костыли он подставит сам. Но спустимся на землю — у нас есть только MySQL, так что придется почитать теорию.
История восстановления базы MySQL из файлов (InnoDB)
10 мин
Как говорит народная мудрость, “админы делятся на две категории: те, которые делают бэкапы, и те, которые уже делают”. В моем случае ответственность за несделанный бэкап упала на разработчика, то есть на меня самого. Данная статья посвящена тому, как найти выход из ситуации, подобной описанной. Надеюсь она будет полезна тем, кто не имея такого опыта, может столкнуться с подобной ситуацией.
Использование событий MySQL на практике
3 мин
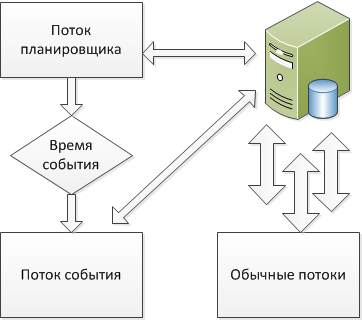 Для тех, кто активно пользуется MySQL, не секрет, что начиная с версии 5.1, MySQL поддерживает события (events). Если вам нужно выполнять запросы или отдельные процедуры по расписанию, а перейти с запуска консоли на встроенный функционал MySQL
Для тех, кто активно пользуется MySQL, не секрет, что начиная с версии 5.1, MySQL поддерживает события (events). Если вам нужно выполнять запросы или отдельные процедуры по расписанию, а перейти с запуска консоли на встроенный функционал MySQL MySQL is NoSQL!
2 мин
У MySQL, как известно, есть два недостатка*. Во-первых, язык запросов — SQL. Это исправляется с помощью HandlerSocket, о котором уже были статьи на хабре. Во-вторых, у него нет встроенного яваскрипта.
* — на самом деле, это шутка. недостатков у MySQL вряд ли именно два, но и заключаются они совершенно не в том, в чём я написал. а отсутствие яваскрипта — это, конечно, не недостаток. однако, если представить, что у MySQL нет SQL интерфейса вообще, то сравнивать его (как NoSQL-решение) нам придётся, в частности, с MongoDB, в котором интерпретатор яваскрипта есть.
Итак, я начал работы по второму направлению и уже получил кое-какой результат:

* — на самом деле, это шутка. недостатков у MySQL вряд ли именно два, но и заключаются они совершенно не в том, в чём я написал. а отсутствие яваскрипта — это, конечно, не недостаток. однако, если представить, что у MySQL нет SQL интерфейса вообще, то сравнивать его (как NoSQL-решение) нам придётся, в частности, с MongoDB, в котором интерпретатор яваскрипта есть.
Итак, я начал работы по второму направлению и уже получил кое-какой результат:
Исследуем производительность JOIN в MySQL
4 мин
Я думаю, ни для кого не секрет, что JOIN считается достаточно дорогой операцией, и многих начинающих программистов (которые юзают MySQL) любят запугивать, что JOIN — это плохо, и лучше всего обойтись без них, если есть возможность.
Давайте исследуем этот вопрос более подробно и посмотрим, действительно ли JOIN — это плохо, и когда вообще стоит задумываться об этом.
Давайте исследуем этот вопрос более подробно и посмотрим, действительно ли JOIN — это плохо, и когда вообще стоит задумываться об этом.