
В статье ниже я попытаюсь кратко рассказать о том, что такое Tarantool и как начать его использовать в уже существующем проекте если вы программируете на Java. Если же вы программируете на другом языке, то вам могут быть интересны некоторые инструменты доступные в коннекторе, такие как возможность редактирование xlog файлов и создание snap файлов из любых данных. Если вы не знаете, что такое Tarantool, то лучше прочитать этот пост.
Как устроена apache cassandra
13 мин

В этом топике я хотел бы рассказать о том, как устроена кассандра (cassandra) — децентрализованная, отказоустойчивая и надёжная база данных “ключ-значение”. Хранилище само позаботится о проблемах наличия единой точки отказа (single point of failure), отказа серверов и о распределении данных между узлами кластера (cluster node). При чем, как в случае размещения серверов в одном центре обработки данных (data center), так и в конфигурации со многими центрами обработки данных, разделенных расстояниями и, соответственно, сетевыми задержками. Под надёжностью понимается итоговая согласованность (eventual consistency) данных с возможностью установки уровня согласования данных (tune consistency) каждого запроса.
NoSQL базы данных требуют в целом большего понимания их внутреннего устройства чем SQL. Эта статья будет описывать базовое строение, а в следующих статьях можно будет рассмотреть: CQL и интерфейс программирования; техники проектирования и оптимизации; особенности кластеров размещённых в многих центрах обработки данных.
Почему нужно 1000 раз подумать, прежде чем использовать noSQL
6 мин
Зачем я пишу эту статью? Во-первых я хотел бы внести свой вклад в понимание людьми сути nosql и того, почему выбирать такой тип хранилища нужно осознанно. Во-вторых, я буду рад встретить единомышленников, противников и, возможно, подискутировать. А если Вам понравилась эта статья, то буду рад услышать вопросы, которые можно раскрыть более подробно в новых статьях:)
Несмотря на то, что nosql решений сейчас тьма, люди неохотно переходят на новые типы хранилищ. Правильно ли это? На мой взгляд – да. И я постараюсь сказать почему, на примере разных nosql хранилищ, которые встретились на моём профессиональном пути.
Несмотря на то, что nosql решений сейчас тьма, люди неохотно переходят на новые типы хранилищ. Правильно ли это? На мой взгляд – да. И я постараюсь сказать почему, на примере разных nosql хранилищ, которые встретились на моём профессиональном пути.
Транзакции в MongoDB
5 мин
Туториал
 MongoDB — замечательная база данных, которая становится все популярнее в последнее время. Все больше людей с SQL опытом начинают её использовать, и один и первых вопросов, который у них возникает: MongoDB transactions?.
MongoDB — замечательная база данных, которая становится все популярнее в последнее время. Все больше людей с SQL опытом начинают её использовать, и один и первых вопросов, который у них возникает: MongoDB transactions?. Если поверить ответам со stackoverflow, то все плохо.
MongoDB doesn't support complex multi-document transactions. If that is something you absolutely need it probably isn't a great fit for you.
If transactions are required, perhaps NoSQL is not for you. Time to go back to ACID relational databases.
Но мы не поверим и реализуем транзакции (ACID*) основанные на MVCC. Ниже будет рассказ о том, как эти транзакции работают, а тем, кому не терпится посмотреть код — добро пожаловать на GitHub (осторожно, java).MongoDB does a lot of things well, but transactions is not one of those things.
Пост не о MongoDB, а о том, как использовать compare-and-set для создания транзакций, а durability обеспчивается ровно в той степени, в которой её обеспечивает хранилище.
Тезисы к докладу на Highload++ «Опыт создания собственных key/value хранилищ для небольших высоконагруженных проектов»
1 мин
Под катом тезисы, хочется знать, что из этого вызовет интерес, а что сократить
NoSQL базы данных: понимаем суть
9 мин
В последнее время термин “NoSQL” стал очень модным и популярным, активно развиваются и продвигаются всевозможные программные решения под этой вывеской. Синонимом NoSQL стали огромные объемы данных, линейная масштабируемость, кластеры, отказоустойчивость, нереляционность. Однако, мало у кого есть четкое понимание, что же такое NoSQL хранилища, как появился этот термин и какими общими характеристиками они обладают. Попробуем устранить этот пробел.

Графовая база данных Neo4j в PHP
5 мин
В последнее время я все чаще слышу о NoSQL и о графовых базах данных в частности. Но воспользовавшись хабропоиском с удивлением обнаружил, что статей на эту тему не так и много, а по запросу «Neo4j», так вообще 4 результата, где косвенно упоминается это название в тексте статей.

Neo4j — это высокопроизводительная, NoSQL база данных основанная на принципе графов. В ней нет такого понятия как таблицы со строго заданными полями, она оперирует гибкой структурой в виде нод и связей между ними.
Уже более года я не использовал в своих проектах SQL, с того времени, как попробовал документо-ориентированную СУБД "MongoDB". После MySQL моей радости не было предела, как все просто и удобно можно делать в MongoDB. За год, в нашей студии создания сайтов, переписали тройку CMS, использующих основные фишки Mongo c её документами, и с десяток сайтов работающих на их основе. Всё было хорошо, и я уже начал забывать, что такое писать запросы в полсотни строк на каждое действие с БД и все бы ничего пока на мою голову не свалился проект с кучей отношений, которые ну никак не укладывались в документы. Возвращаться к SQL очень не хотелось, и пару дней я потратил чисто на поиск NoSQL решения, позволяющего делать гибкие связи — на графовые СУБД. И по ряду причин мой выбор остановился на Neo4j, одна из главных причин — это то, что мой движок был написан на PHP, а для неё был написан хороший драйвер "Neo4jPHP", который охватывает почти 100% REST-интерфейса, предоставляющегося сервером Noe4j.
Что такое Neo4j?
Neo4j — это высокопроизводительная, NoSQL база данных основанная на принципе графов. В ней нет такого понятия как таблицы со строго заданными полями, она оперирует гибкой структурой в виде нод и связей между ними.
Как я докатился до этого?
Уже более года я не использовал в своих проектах SQL, с того времени, как попробовал документо-ориентированную СУБД "MongoDB". После MySQL моей радости не было предела, как все просто и удобно можно делать в MongoDB. За год, в нашей студии создания сайтов, переписали тройку CMS, использующих основные фишки Mongo c её документами, и с десяток сайтов работающих на их основе. Всё было хорошо, и я уже начал забывать, что такое писать запросы в полсотни строк на каждое действие с БД и все бы ничего пока на мою голову не свалился проект с кучей отношений, которые ну никак не укладывались в документы. Возвращаться к SQL очень не хотелось, и пару дней я потратил чисто на поиск NoSQL решения, позволяющего делать гибкие связи — на графовые СУБД. И по ряду причин мой выбор остановился на Neo4j, одна из главных причин — это то, что мой движок был написан на PHP, а для неё был написан хороший драйвер "Neo4jPHP", который охватывает почти 100% REST-интерфейса, предоставляющегося сервером Noe4j.
Релиз MongoDB 2.2.0
1 мин
Вчера состоялся долгожданный релиз NoSQL базы данных MongoDB 2.2.0.
Среди самых важных нововведений стоит отметить:
Aggregation Framework
Инструмент, оптимизирующего обработку больших массивов данных без map-reduce (больше информации на хабре)
TTL-коллекций
TTL-коллекции позволяют удалять из коллекции данные, у которых вышло время жизни, установленое с помощью специального индекса(удобно, например, для хранения логов, сессий и подобной информации). При использовании таких коллекций создается дополнительный фоновый процесс для реализации соответсвующей проверки
docs.mongodb.org/manual/release-notes/2.2
Среди самых важных нововведений стоит отметить:
Aggregation Framework
Инструмент, оптимизирующего обработку больших массивов данных без map-reduce (больше информации на хабре)
TTL-коллекций
TTL-коллекции позволяют удалять из коллекции данные, у которых вышло время жизни, установленое с помощью специального индекса(удобно, например, для хранения логов, сессий и подобной информации). При использовании таких коллекций создается дополнительный фоновый процесс для реализации соответсвующей проверки
docs.mongodb.org/manual/release-notes/2.2
Первый опыт установки и использования MongoDb
2 мин
Этот пост может быть полезен тем, кто решил попробовать Mongodb в своем проекте (использует его впервые).
Mongodb может быть хорошим решением (по сравнению с СУБД), если вам нужно хранить объекты со сложной структурой или не однотипные объекты. Также, возможности mapReduce полезны для генерации разнообразной статистики, использование mapReduce может быть гораздо удобнее использования агрегирующих функций и написания процедур в SQL.
Mongodb может быть хорошим решением (по сравнению с СУБД), если вам нужно хранить объекты со сложной структурой или не однотипные объекты. Также, возможности mapReduce полезны для генерации разнообразной статистики, использование mapReduce может быть гораздо удобнее использования агрегирующих функций и написания процедур в SQL.
ZooKeeper или пишем сервис распределенных блокировок
10 мин
disclaimer Так получилось, что последний месяц я разбираюсь с ZooKeeper, и у меня возникло желание систематизировать то, что я узнал, собственно пост об этом, а не о сервисе блокировок, как можно было подумать исходя из названия. Поехали!
При переходе от многопоточного программирования к программированию распределенных систем многие стандартные техники перестают работать. Одной из таких техник являются блокировки (synchronized), так как область их действия ограничена одним процессом, следовательно, они не только не работают на разных узлах распределенной системы, но так же не между разными экземплярами приложения на одной машине; получается, что нужен отдельный механизм для блокировок.
От распределенного сервиса блокировок разумно требовать:
Создать подобный сервис нам поможет ZooKeeper
 В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами:
В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами:
При переходе от многопоточного программирования к программированию распределенных систем многие стандартные техники перестают работать. Одной из таких техник являются блокировки (synchronized), так как область их действия ограничена одним процессом, следовательно, они не только не работают на разных узлах распределенной системы, но так же не между разными экземплярами приложения на одной машине; получается, что нужен отдельный механизм для блокировок.
От распределенного сервиса блокировок разумно требовать:
- работоспособность в условиях моргания сети (первое правило распределенных систем —
никому не говорить о распределенных системахсеть ненадежна) - отсутствие единой точки отказа
Создать подобный сервис нам поможет ZooKeeper
В википедии написано, что ZooKeeper — распределенный сервис конфигурирования и синхронизации, не знаю как вам, но мне данное определение мало что раскрывает. Оглядываясь на свой опыт, могу дать альтернативное определение ZooKeeper, это распределенное key/value хранилище со следующими свойствами:- пространство ключей образует дерево (иерархию подобную файловой системе)
- значения могут содержаться в любом узле иерархии, а не только в листьях (как если бы файлы одновременно были бы и каталогами), узел иерархии называется znode
- между клиентом и сервером двунаправленная связь, следовательно, клиент может подписываться как изменение конкретного значения или части иерархии
- возможно создать временную пару ключ/значение, которая существует, пока клиент её создавший подключен к кластеру
- все данные должны помещаться в память
- устойчивость к смерти некритического кол-ва узлов кластера
Cassandra глазами Operations
9 мин
Основной проект компании, в которой я работаю, посвящен оптимизации показов рекламы в приложениях на фейсбуке и на мобильных устройствах. На сегодняшний день проект обслуживает до 400 миллионов уникальных посетителей в месяц, работает на тысяче с лишним виртуальных серверов. Количество серверов и обьемы данных, которые должны обрабатываться двадцать четыре часа в сутки, ставит перед разработчиками ряд интересных проблем, связанных с масштабируемостью и устойчивостью системы.
Оптимизация показов — большой процесс, одной из частей которого является сохранение и анализ цепочки событий, связанных с жизненным циклом баннера — показ, клик, конверсия, … всё это начинается с сохранения записей о событиях. Каждое из событий происходит на одном из множества серверов, причем, по понятной причине мы стараемся обслужить всю цепочку в одном месте — в этом случае не нужно заботиться о том как собрать в целое разбросанные части. Но в реальной жизни случается что угодно — сервера падают, сеть не работает, софт апгрейдится или перегружен — в общем, по многим причинам обслуживание последовательных событий иногда происходит на разных серверах и даже в разных датацентрах и к этому нужно быть готовым.
Задача которую нужно было решать — каким образом хранить, искать, модифицировать информацию о последовательности событий при следующих условиях:
Последние два пункта очень важны для бизнеса и просто жизненно важны для опс инженеров если они хотят спокойно выполнять свои обязанности днём, и спокойно спать ночью.
Оптимизация показов — большой процесс, одной из частей которого является сохранение и анализ цепочки событий, связанных с жизненным циклом баннера — показ, клик, конверсия, … всё это начинается с сохранения записей о событиях. Каждое из событий происходит на одном из множества серверов, причем, по понятной причине мы стараемся обслужить всю цепочку в одном месте — в этом случае не нужно заботиться о том как собрать в целое разбросанные части. Но в реальной жизни случается что угодно — сервера падают, сеть не работает, софт апгрейдится или перегружен — в общем, по многим причинам обслуживание последовательных событий иногда происходит на разных серверах и даже в разных датацентрах и к этому нужно быть готовым.
Задача которую нужно было решать — каким образом хранить, искать, модифицировать информацию о последовательности событий при следующих условиях:
- события могут происходить на разных серверах и в разных датацентрах (восточный и западный берег США, Европа)
- интервал между событиями — от долей секунды до нескольких дней
- к моменту получения завершающего события (например конверсия) информация обо всей цепочке должна быть на руках
- время жизни информации — примерно десять дней, после чего она должна быть удалена, желательно автоматически, через TTL
- темп чтения/записи событий — сотни или тысячи в секунду
- Время ответа: желательное — до 10мс, допустимое — в пределах 50мс, максимальное — до 100мс
- информация должна быть доступна «всегда» — независимо от аварий железа, сети, апгрейдов
- система должна легко масштабироваться: добавление новых серверов, датацентров должно происходить прозрачно для остальных сервисов (допустима деградация времени ответа в заданных пределах).
Последние два пункта очень важны для бизнеса и просто жизненно важны для опс инженеров если они хотят спокойно выполнять свои обязанности днём, и спокойно спать ночью.
MemSQL has launched!
2 мин
MemSQL — это база данных следующего поколения, решающая проблемы наиболее ограничивающего для большинства нынешних приложений компонента— диска.
Настало время пощупать базу данных следующего поколения MemSQL!

От создателя проекта, Никиты Шамнугова:
«MemSQL — это база данных следующего поколения, решающая проблемы наиболее ограничивающего для большинства нынешних приложений компонента— диска. Предлагая всем знакомый SQL интерфейс к данным хранящимся в памяти, MemSQL дает возможность при разработке масштабных веб-приложений иметь дело с большим трафиком и быстрым ростом. MemSQL на порядки улучшает производительность чтения и записи и заметно упрощает разработку и поддержку приложений. Разрабатывается MemSQL в далекой Калифорнии, Сан Франциско, частной компанией при частичной поддержке First RoundCapital и NEA.»
Настало время пощупать базу данных следующего поколения MemSQL!
От создателя проекта, Никиты Шамнугова:
«MemSQL — это база данных следующего поколения, решающая проблемы наиболее ограничивающего для большинства нынешних приложений компонента— диска. Предлагая всем знакомый SQL интерфейс к данным хранящимся в памяти, MemSQL дает возможность при разработке масштабных веб-приложений иметь дело с большим трафиком и быстрым ростом. MemSQL на порядки улучшает производительность чтения и записи и заметно упрощает разработку и поддержку приложений. Разрабатывается MemSQL в далекой Калифорнии, Сан Франциско, частной компанией при частичной поддержке First RoundCapital и NEA.»
Ближайшие события






Firebird Conf: конференция для разработчиков и администраторов СУБД Firebird
6 июня
09:00 – 20:00
Москва

ObjectDB — система управления базами данных для Java приложений
4 мин
Recovery Mode
ObjectDB является объектно-ориентированной, написанной на Java СУБД, которая при всех своих впечатляющих тестах на скорость и используемая (как следует из рекламы на официальном сайте) такими организациями как HP и Novell малознакома для многих программистов (Сам я об этой базе узнал буквально месяц назад, и использовал ее только один раз в рамках учебного проекта, да и мой препод узнал о ней как раз из моего проекта). За продолжением прошу под кат.
Релиз GlobalsDB 2012.2
6 мин
15 мая вышла новая версия бесплатной NoSQL СУБД GlobalsDB 2012.2.
Что нового?
Добавлен ожидаемый многими Node.JS API интерфейс для Windows, и сразу же для Windows 64-bit.
Реализованы небольшие дополнения и устранены некоторые ошибки.
Об этом и остальном
Что нового?
Добавлен ожидаемый многими Node.JS API интерфейс для Windows, и сразу же для Windows 64-bit.
Реализованы небольшие дополнения и устранены некоторые ошибки.
Об этом и остальном
Не БД
6 мин
Перевод
Автор рассказывает о перипетиях пивоваров, производителей СУБД, себя и кратко о том как правильно проектировать приложения. Мне показалась полезной поучительная часть статьи.
Моделирование данных в MongoDB
5 мин
Перевод
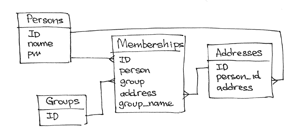 Одна из самых разрекламированных фич MongoDB — это гибкость. Я сам не раз подчеркивал это в бесчисленных разговорах о MongoDB. Однако, гибкость — это палка о двух концах: большая гибкость подразумевает более широкий выбор решений для моделирования данных. Тем не менее, мне нравится гибкость, которую предоставляет MongoDB, просто нужно иметь ввиду некоторые рекомендации, прежде чем начать разрабатывать модель данных.
Одна из самых разрекламированных фич MongoDB — это гибкость. Я сам не раз подчеркивал это в бесчисленных разговорах о MongoDB. Однако, гибкость — это палка о двух концах: большая гибкость подразумевает более широкий выбор решений для моделирования данных. Тем не менее, мне нравится гибкость, которую предоставляет MongoDB, просто нужно иметь ввиду некоторые рекомендации, прежде чем начать разрабатывать модель данных.В этой статье мы рассмотрим, как смоделировать структуру, содержащую списки рассылок и данные о людях, которые входят в эти списки.
List-функции в CouchDB
3 мин
На Хабре часто встречается комментарий о том, что документацию разработчики не дочитывают до конца. Столкнулся с этим сам, когда открыл для себя List-функции в CouchDB.
Мне показался вопрос достаточно сложным и не очень хорошо объясненным в документации, решил поделиться с уважаемым сообществом своим исследованием.
List-функции в design-документах CouchDB нужны для того, чтобы иметь возможность обработать всю базу данных одной функцией. Т.е. это некий аналог Full Table Scan в реляционных базах.
Мне показался вопрос достаточно сложным и не очень хорошо объясненным в документации, решил поделиться с уважаемым сообществом своим исследованием.
List-функции в design-документах CouchDB нужны для того, чтобы иметь возможность обработать всю базу данных одной функцией. Т.е. это некий аналог Full Table Scan в реляционных базах.
Структуры данных, используемые в Redis
4 мин
Перевод
От переводчика:
Хочу представить вашему вниманию перевод ответа одного из разработчиков Redis, на вопрос о том, какие структуры данных используются внутри Redis. Оригинальную дискуссию вы можете найти на stackoverflow.
Я попробую ответить на вопрос, но начну с того, что на первый взгляд может показаться странным: если вы не интересуетесь внутренностями Redis, вы не должны заботиться о том, как реализованы структуры данных изнутри. Причина этому проста — сложность каждой команды Redis вы можете найти в документации, и если у вас есть набор операций и их вычислительная сложность, то единственное, что вам нужно, это некоторое представление об использовании памяти (и потому, что мы делаем много оптимизаций, в зависимости от данных, лучший способ получить эти последние цифры это тесты в реальных условиях)
Но поскольку вы спросили, вот внутренние реализации каждой структуры данных Redis:
Хочу представить вашему вниманию перевод ответа одного из разработчиков Redis, на вопрос о том, какие структуры данных используются внутри Redis. Оригинальную дискуссию вы можете найти на stackoverflow.
Я попробую ответить на вопрос, но начну с того, что на первый взгляд может показаться странным: если вы не интересуетесь внутренностями Redis, вы не должны заботиться о том, как реализованы структуры данных изнутри. Причина этому проста — сложность каждой команды Redis вы можете найти в документации, и если у вас есть набор операций и их вычислительная сложность, то единственное, что вам нужно, это некоторое представление об использовании памяти (и потому, что мы делаем много оптимизаций, в зависимости от данных, лучший способ получить эти последние цифры это тесты в реальных условиях)
Но поскольку вы спросили, вот внутренние реализации каждой структуры данных Redis:
- Строки реализованы с использованием библиотеки динамических строк C, так что мы не платим (говоря асимптотически) за выделение памяти в операциях добавления. Таким образом мы получаем сложность добавления O(N), вместо, например, квадратичной.
- Списки реализованы как связные списки.
- Множества и Хэши реализованы как хэш-таблицы.
- Упорядоченные множества реализованы как списки с пропусками (особый тип сбалансированных деревьев)