

Redis — одна из самых популярных NoSQL баз данных. Рассказываем о функциональности и практиках использования.

Работа с геопространственными данными заведомо сложная задача, хотя бы потому что широта и долгота это числа с плавающей запятой и они должны быть очень высокоточными. К тому же, казалось бы, широта и долгота могут быть представлены в виде сетки, но на самом деле нет, не могут, просто потому что Земля не плоская, а математика - сложная наука.
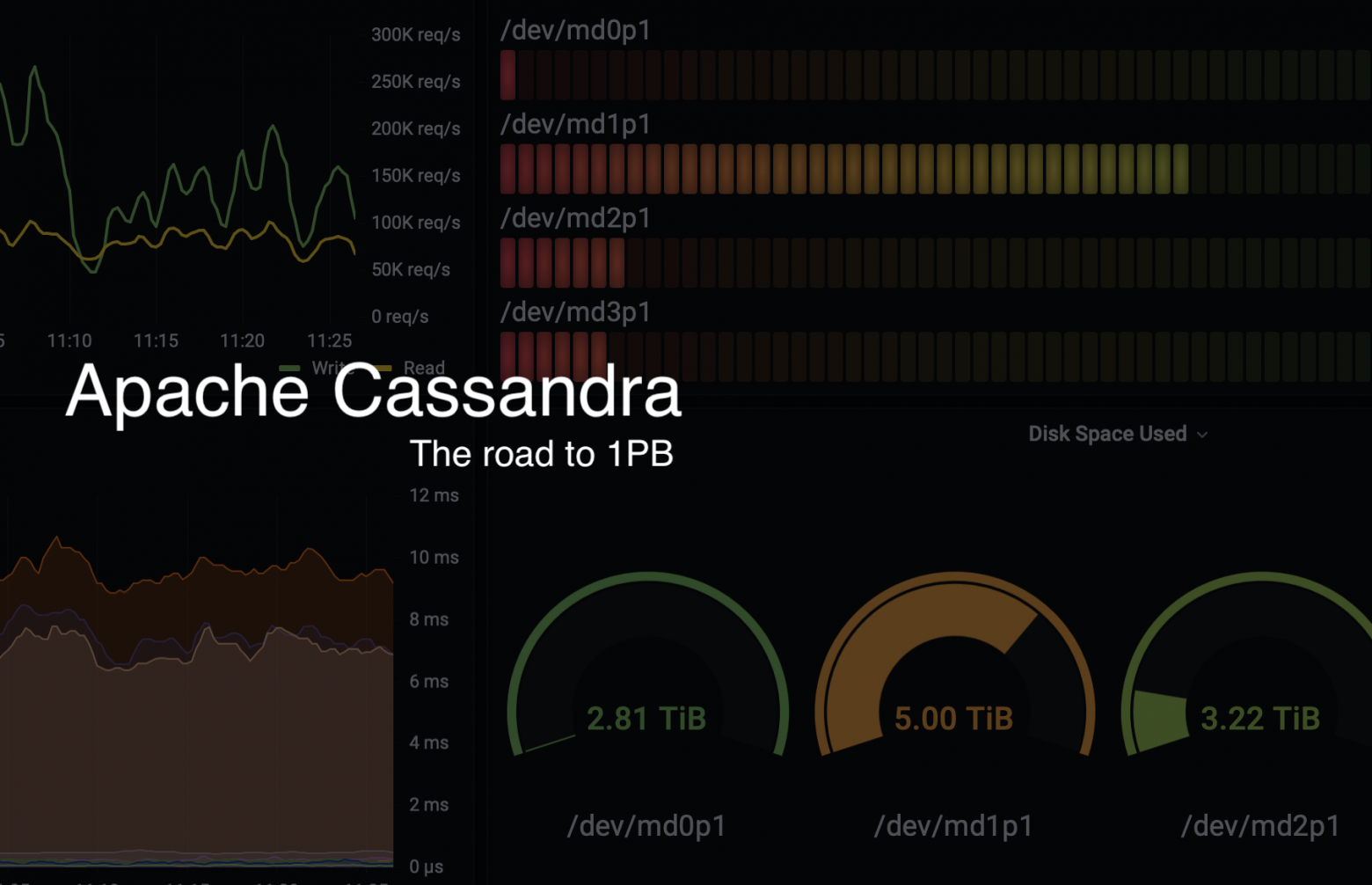
Центр Развития Перспективных Технологий - компания разработчик системы мониторинга товаров. Как IT компания с большим количеством данных мы используем множество NoSQL решений в своей повседневной работе. Одним из таких решений является Apache Cassandra.
Суммарно, во всех кластерах Cassandra мы храним 0.4PB данных при общей емкости 0.9PB, стабильно производим 0.7млн операций записи и доступа к данным и 1.1млн когда необходимо разогнаться в трудные времена, при этом продолжаем непрерывно расширяться.
Отсюда лежит и название статьи, к моменту публикации последней главы из цикла петабайтный барьер емкости будет взят.
Материал подразумевает, что вы уже начали знакомиться с этой замечательной базой данных, хотите найти примеры её использования в российском сегменте интернета и будет полезен тем, кто постоянно ищет способ обучиться за счёт чужих ошибок. Ошибок мы совершили не мало, добро пожаловать!

Сердцем любого backend являются данные. Существует два сценария использования данных. В одном из них данные изменяются редко, но при этом активно используются в сыром или агрегированном виде и применяются для целей аналитики в реальном времени (такие системы принято называть OLAP). В других системах важно обеспечить сохранение с высокой скоростью большого количество неструктурированных или полуструктурированных объектов, поступающих от устройств Интернета вещей, из источников произвольных событий, наблюдений за активностью пользователя (такие системы называются OLTP - Online Transaction Processing, ориентированные на большое количество транзакций с минимальной задержкой обработки). Для таких систем важно обеспечить надежность хранения данных, поддержку распределенного хранения на нескольких серверах и/или дата-центрах и сохранение консистентности распределенного хранилища.
При этом сами объекты могут отличаться от привычной реляционной модели данных и представляться, например, в виде json-документов с произвольной схемой, объектов с полями со множественными значениями или графов. Разумеется это приводит к необходимости изучения новых подходов к поиску и добавлению данных, использованию специальных драйверов. Но что если соединить распределенное надежное хранилище и синтаксис запросов, близкий к SQL? В этой статье мы познакомимся с проектом Apache Cassandra и обсудим на примере разработки API на Kotlin для сбора телеметрии с датчиков, расположенных по всему миру (с поддержкой отказоустойчивости и управляемой репликации между дата-центрами).

Neo4j без преувеличения является самой распространенной графовой базой данных. Подход «schema free», гибкий язык запросов «cypher» — познакомиться с ней стоит хотя бы для расширения кругозора. Мы в компании Bimeister с целью повышения производительности провели серию экспериментов по переезду на Neo4j. Под катом я рассмотрю одну из сторон возможного апгрейда — импорт данных в графовую БД, проведу оценку ее преимуществ и недостатков и оценю время загрузки каждым из способов.

О том, как мы столкнулись с огромными проблемами легаси сервиса фильтрации каталога и срочно начали думать, как это исправить переписать. О том, что у нас вышло с помощью redis, rabbit, bitrix - в статье.

Неделю назад вышла новая версия модуля CRUD для Tarantool. В 0.11.0 появилось множество нововведений, просьбы о которых поступали от наших пользователей. Что изменилось, как этим пользоваться и кому это может быть полезно? Расскажем обо всём.
Tarantool — это платформа in-memory вычислений с гибкой схемой данных, функциональность которой расширяется с помощью модулей. Одними из самых популярных являются vshard, предназначенный для распределённого хранения данных, и cartridge, который организует работу с кластером Tarantool. CRUD также можно считать членом этого семейства: он предназначен для написания запросов при работе с распределёнными данными. Мы в Tarantool активно используем его при разработке готовых решений и нередко упоминаем в статьях (например, здесь и здесь).
Приветствую, читатель! Хотелось бы осветить свою небольшую библиотеку для C++, которая призвана помочь Вам создавать динамические структуры в shared-памяти. Далее - под катом.
Весной 2021 года во французском Страсбурге случилось яркое событие: полностью сгорел дата-центр одного из крупнейших европейских хостинг-провайдеров (OVH). Всего за несколько часов пожар отрубил доступ к миллиону популярных сайтов и онлайн-сервисов во всём мире. Одна из вероятных причин — человеческий фактор. В результате под угрозой существования оказался не только сам ЦОД, но и весь бизнес провайдера. К слову, и в России ЦОДы тоже горят. К сожалению, пожар — не единственная проблема больших данных. Не менее опасно — highload системы. Это когда, например, приложение перестаёт справляться с моментальной нагрузкой, а вся инфраструктура работает на пределе возможностей, и запаса для роста у неё нет. Забегая вперед, скажу, что решение есть у каждой из перечисленных проблем. Но, обо всём по порядку.

Использовать стандартные библиотеки и общеизвестные реализации алгоритмов — признак хорошего тона. Вместо изобретения своего алгоритма шифрования данных или своей хэш функции лучше взять уже готовое решение. Избегаем ошибок и не изобретаем велосипед заново. Но что если готового решения нет? В наше время это что-то невероятное. Есть github.com, есть набор платных решений.Тем интереснее обсудить необычную проблему. В данной статье расскажу о своем опыте оптимизации работы с данными, которые по своей природе представляют граф. А точнее сеть — разновидность графов.
«Традиционно, самым узким местом в архитектуре любой информационной системы является система управления базами данных (СУБД). Можно сколько угодно оптимизировать прикладное программное обеспечение (ПО), но все равно упремся в ограничения в части производительности запросов». В своем материале я рассказываю о том, как построить архитектуру системы без слабых мест, и кого для этого стоит принести в жертву.

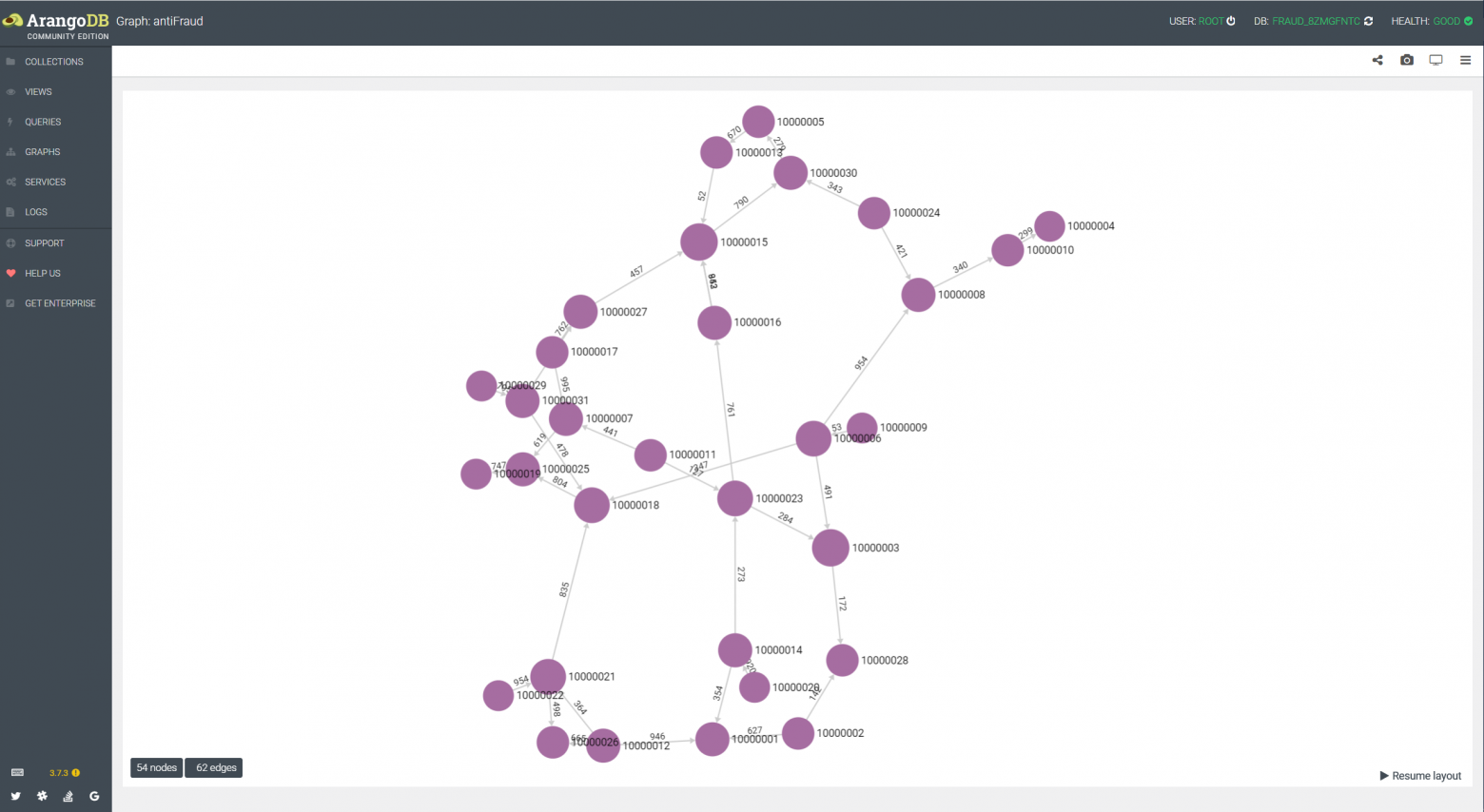
Про ArangoDB было уже несколько статей на Хабре, так что подробно расписывать, что это такое тут не буду. Скажу только, что это мультимодельная база данных (графовая и документная). Может возникнуть вопрос - "зачем" и для "каких задач" надо использовать ArangoDB по сравнению с популярными и хорошо известными реляционными или документными базами данных. И сегодня мы посмотрим, как с использованием его графовых возможностей можно решать практические задачи.

Говорят, что вакцины стали жертвами собственной эффективности. Будто если бы мы видели, как странновато одетый кучер раз в неделю забирал бы трупы нескольких соседей, умерших, как и десятки до них, довольно неприятной смертью, может, и вакцинировались бы охотнее.
Я не ученый вирусолог/эпидемиолог/фармацевт, я зарабатываю себе не хлеб тем, что пишу программы. Иногда мне кажется, что делаю это довольно успешно. Сегодня в очередной раз я услышал фразу, что привел в эпиграфе, а вчера в баре под укоризненные взгляды друзей рассказывал, как я отбился в проекте от использования какой-то нереляционки и у меня в голове щелкнуло и я сел набирать этот текст.
С середины прошлого века мы работаем над реляционными базами данных. И они прекрасны. Но сейчас все чаще любят использовать NoSQL всех видов и мастей. И они иногда неплохо ложатся и затыкают собой какое-то мелкое место в проекте. Если я ценю свои данные и мне нужна какая-то надежность, то мне нужны ACID гарантии. Если это всего лишь кеш, данные из которого нужны чтобы ускорить приложение то я с радостью возьму Redis или аналоги. Ведь если он упадет или данные рассогласуются я смогу их восстановить из нормальной базы.









Одним из трендов при проектировании сервисов в последнее время выступает использование в качестве баз данных NoSQL-систем. Мы также стараемся идти в ногу со временем и, конечно же, имеем в своем IT-ландшафте несколько таких решений. Одно из них — шардированный кластер MongoDB. Эксплуатация этой СУБД сопряжена с проблемами производительности, архитектуры, взаимодействия и т.д. Удивительно, но факт - зачастую, все мы сталкиваемся с тем, что ошибаются разработчики самой СУБД. Кто бы мог подумать.., что после штатной перезагрузки узла конфигурационного сервера MongoDB в процессе обновления может произойти аварийное завершение работы сервиса базы данных и наш стенд превратится в «тыкву»!
Об одном из таких случаев хотим рассказать в этой статье и, возможно, уберечь наших читателей от опрометчивых шагов при работе с MongoDB.
Дисклеймер: нижеописанные события произошли после того, как была опубликована рекомендация производителя не использовать версию 4.4.4.

Привет, меня зовут Игорь и я работаю в команде Tarantool. При разработке мне часто требуется быстрое прототипирование приложений с базой данных, например, для тестирования кода или для создания MVP. Конечно же хочется, чтобы такой прототип требовал минимальных усилий по доработке, если вдруг будет решено пустить его в работу.
Мне не нравится тратить время на настройку SQL базы данных, думать, как управлять шардированием данных, тратить много времени на изучение интерфейсов коннекторов. Хочется просто написать несколько строчек кода и запустить его, чтобы все работало из коробки. В быстрой разработке распределенных приложений мне помогает Cartridge — фреймворк для управления кластерными приложениями на основе NoSQL базы данных Tarantool.
Сегодня я хочу рассказать о том, как можно быстро написать приложение на Cartridge, покрыть его тестами и запустить. Статья будет интересна всем, кто устал тратить много времени на прототипирование приложений, а также людям, которые хотят попробовать новую NoSQL технологию.

Всем привет, меня зовут Артём и я алкоголик долгое время не понимал базы данных. Ну, то есть я понимал концепт и как с ними работать, но всегда воспринимал их как чёрный ящик с понятным интерфейсом, который может сохранять и отдавать данные, если знать, как его об этом попросить. Механизмы, позволяющие магии случаться, были совершенно не понятны. И честно говоря, меня это особо не волновало. Бизнесу нужно, чтобы ты фичи фигачил, а не вот это вот всё.
Однако недавно я понял, что хватит это терпеть и настало время разобраться что происходит под капотом, как это происходит и зачем. Статья подойдёт тем, кто каждый день работает с базами данных и не особо вникает в подробности, людям, кто как и я заинтересовался тем, как всё работает и не знает откуда начать копать или просто тем, кто хочет немного освежить своё понимание баз данных.

После публикации статьи “Какую СУБД выбрать и почему? (Статья 1)” ко мне поступили справедливые комментарии о том, что я не упомянул такие типы СУБД, как Time Series и Spatial. В этой статье я кратко опишу их и добавлю еще два типа — Search engines и Object-oriented (объектные).

Всем привет! В компании Querify Labs мы создаем компоненты СУБД, включая оптимизаторы SQL-запросов.
Любой SQL-запрос может быть выполнен множеством способов. Задача оптимизатора - найти эффективный план выполнения запроса.
В этой статье мы обсудим rule-based оптимизацию - популярную архитектуру оптимизатора, в котором планирование запроса разбито на последовательность атомарных трансформации. Мы рассмотрим особенности реализации данного подхода в Apache Calcite, Presto, и CockroachDB.

MongoDB — это NoSQL-база данных, которую в том или ином виде используют более четверти разработчиков. MongoDB и другие NoSQL-базы данных привлекают своей гибкостью: вместо жесткой схемы и вертикального масштабирования, у вас есть возможность развивать схему постепенно и масштабироваться горизонтально. Компания MongoDB вышла на биржу в 2017 году и сегодня стоит более 17 миллиардов долларов.
Документные базы данных используют вместо реляционных таблиц и столбцов вложенные пары ключ-значение. Одно из преимущество такого подхода в том, что вам не нужно преобразовать данные для взаимодействия с фронтендом — данные уже хранятся в необходимом виде (плюс-минус .map или .reduce).
Работа с MongoDB через командную строку не всегда удобна, и в этом посте мы рассмотрим доступные графические инструменты.

Первая часть в серии статей про СУБД, в которых будут представлены простые и понятные критерии, на основе которых можно будет получить подсказку, какую СУБД выбрать для своего проекта.
В данной статье разберем типы СУБД, какие наиболее популярны, в чем их предназначение и уникальность. Подскажу при каких условиях нужно выбирать ту или иную СУБД, а когда не нужно.