Здравствуйте, Хабр.
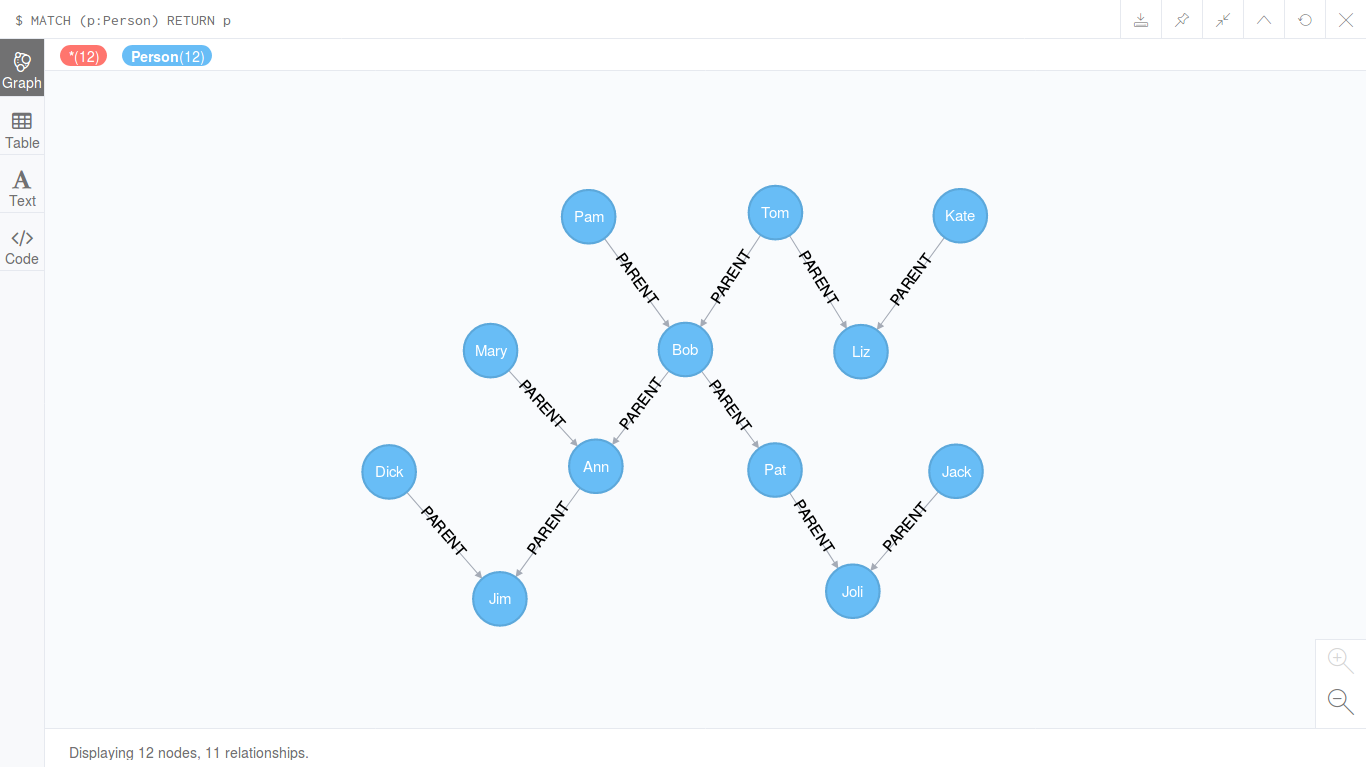
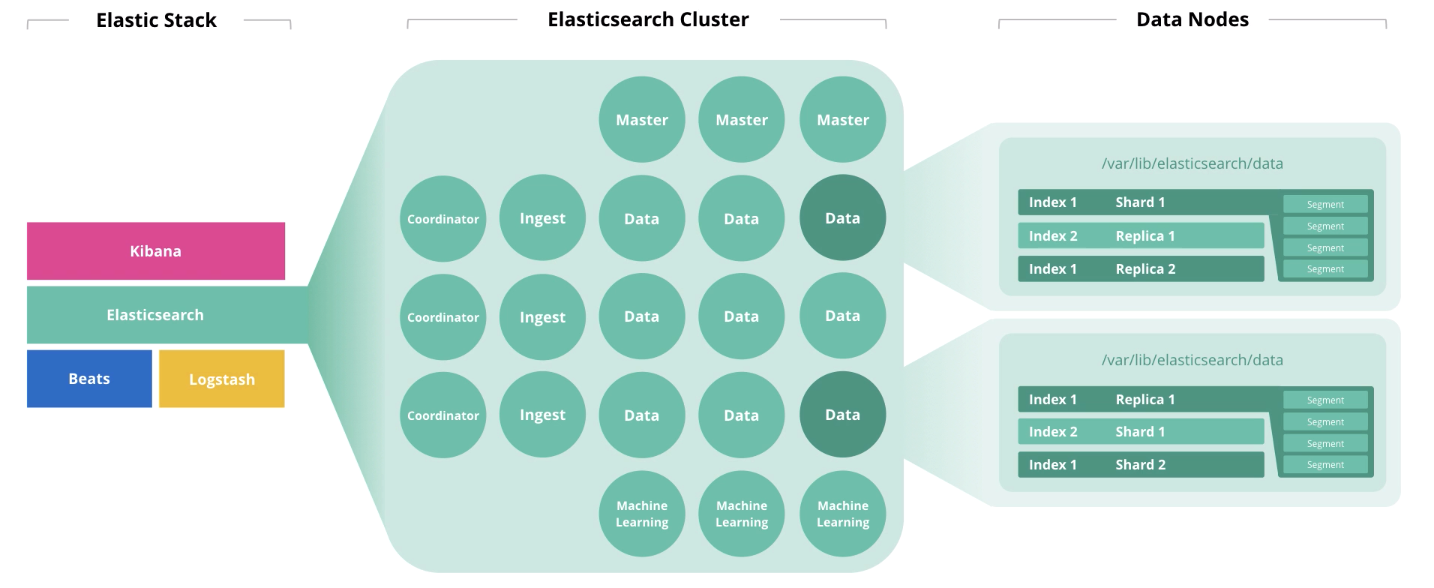
Сегодня мы предлагаем вашему вниманию перевод статьи из блога MemSQL, которая исходно является рекламной (посвящена достоинствам MemSQL, обновлена по состоянию на начало января 2020 года). Но мы решили все-таки перевести ее в сокращенном виде, поскольку она подробно объясняет, почему мы пока так и не собрались издавать ничего ни по MongoDB, ни по Cassandra, ни по прочим нереляционным базам данных. Может быть, мы были правы, ограничившись весьма успешной книгой "MySQL по максимуму".
Сегодня мы предлагаем вашему вниманию перевод статьи из блога MemSQL, которая исходно является рекламной (посвящена достоинствам MemSQL, обновлена по состоянию на начало января 2020 года). Но мы решили все-таки перевести ее в сокращенном виде, поскольку она подробно объясняет, почему мы пока так и не собрались издавать ничего ни по MongoDB, ни по Cassandra, ни по прочим нереляционным базам данных. Может быть, мы были правы, ограничившись весьма успешной книгой "MySQL по максимуму".