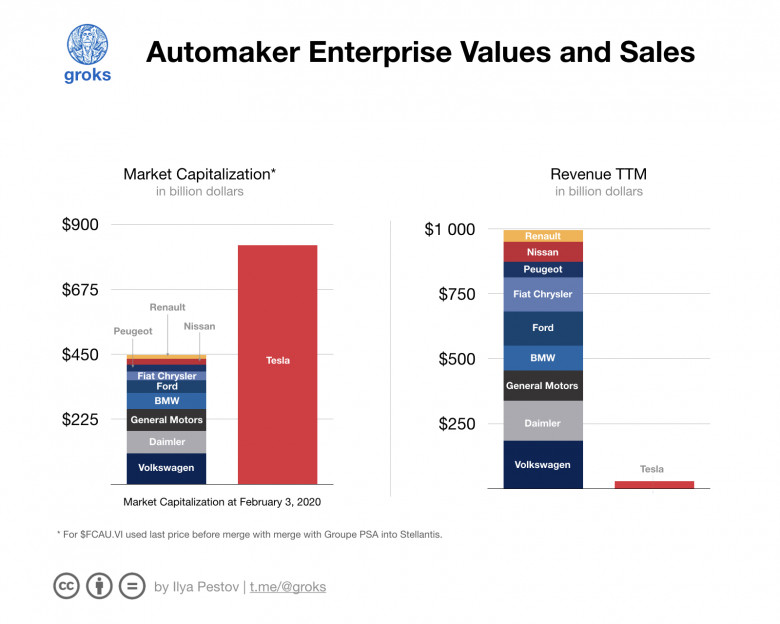
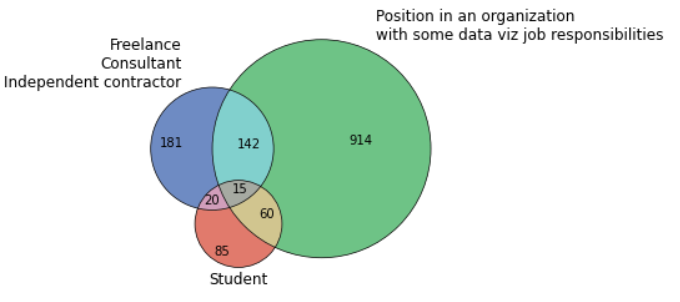
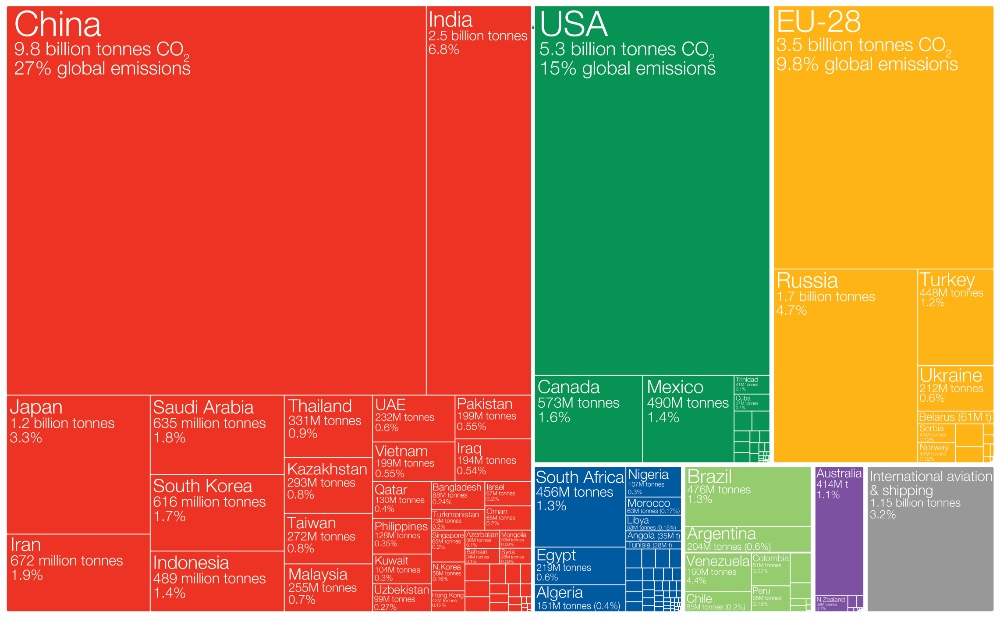
Для принятия правильных решений в различных жизненных ситуациях очень полезно иметь адекватную модель мира. В частности, бывает полезна возможность сопоставить популярность различных предметов и оценить динамику этой популярности. Например, вы издатель, и вам предлагают перевести и издать книгу по языку программирования Fortran. Его ведь всё ещё используют, издаётся англоязычная литература, а у нас давно ничего не выходило. Или, скажем, по языку Julia. Книжек по актуальной версии языка на русском ещё нет. Можно взять какую-нибудь самую популярную английскую, перевести, издать и сорвать куш. В подобных ситуациях полезно иметь возможность подглядеть, какова популярность этих языков относительно других и какова динамика этой популярности. Пример с языками программирования приведён просто для наглядности, подобные задачи возникают и при анализе популярности различных программ, технологий, научных концепций.