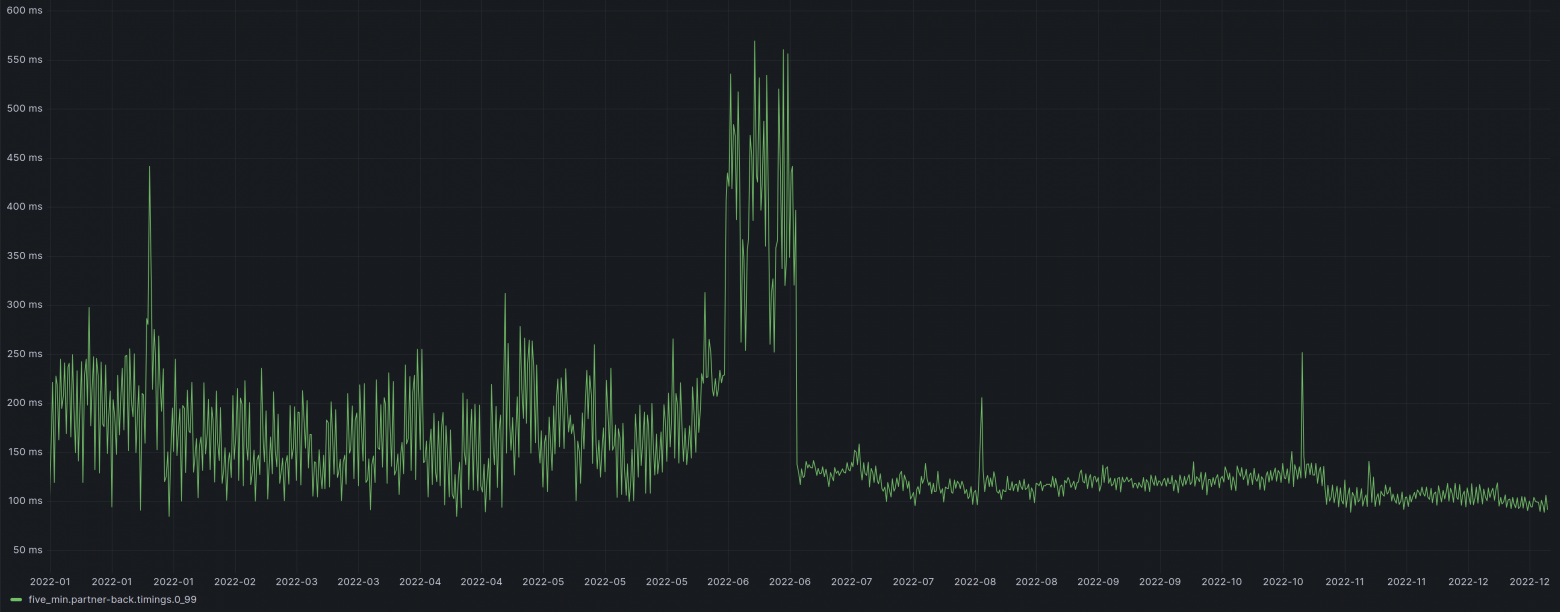
Рассказывать, какие есть кэши, что такое Result Cache, как он сделан в Oracle и в других базах данных не очень интересно и довольно шаблонно. Но все приобретает совершенно другие краски, когда речь идет о конкретных примерах.
Александр Токарев (
shtock) построил свой доклад на Highload++ 2017 исходя из кейсов. И именно опираясь на кейсы, рассказал, когда может быть удобен самодельный кэш, в чем боль server-side Result Cache и как заменить его клиентским, и вообще вывел ряд полезных советов по настройке Result Cache в Oracle.
О спикере: Александр Токарев работает в компании DataArt и занимается вопросами, связанными с базами данных как в части построения систем «с нуля», так и оптимизации имеющихся.
Начнем с нескольких риторических вопросов. Вы работали с Oracle Result Cache? Вы верите, что Oracle — это база данных, удобная на все случаи? По опыту Александра большинство людей на последний вопрос отвечает отрицательно,
на сто суровых прагматиков приходится один мечтатель. Но благодаря его вере двигается прогресс.
Кстати, у Oracle уже 14 баз данных — пока 14 — что будет в будущем, неизвестно.
Как уже говорилось, все проблемы и решения будут проиллюстрированы конкретным кейсами. Это будет два кейса из проектов DataArt, и один сторонний пример.