Мне оказали честь — пригласили выступить на первой конференции
C++ 2015 Russia 27-28 февраля. Я был насколько наглым, что запросил 2 часа на выступление вместо положенного одного и заявил тему, наиболее меня интересующую — конкурентные ассоциативные контейнеры. Это hash set/map и деревья. Организатор
sermp пошел навстречу, за что ему большое спасибо.
Как подготовиться ко столь ответственному
испытанию выступлению? Первое — нарисовать презентацию, то есть кучу картинок, желательно близко к теме. Но надо ещё и два часа озвучивать картинки, — как все это запомнить? Как избежать глубокомысленных «ээээмммм», «здесь мы видим», «на этом слайде показано», несвязных прыжков повествования и прочих вещей, характеризующих выступающего c не очень хорошей стороны в части владения родным языком (это я про русский, с C++ я разобрался быстро — никакого кода в презентации, только картинки)?
Конечно, надо записать свои мысли, глядя на слайды. А если что-то написано, то не худо бы и опубликовать. А если публиковать, — то на хабре.
Итак, по следам
C++ 2015 Russia! Авторское изложение, надеюсь, без авторского косноязычия, без купюр и с отступлениями по теме, написанное до наступления события, в нескольких частях.

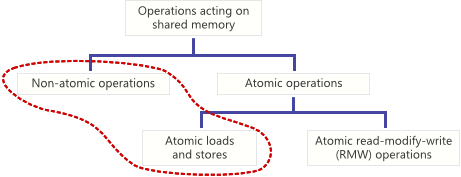
 Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.
Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.