От переводчика: Джефф Прешинг (Jeff Preshing) — канадский разработчик программного обеспечения, последние 12 лет работающий в Ubisoft Montreal. Он приложил руку к созданию таких известных франшиз как Rainbow Six, Child of Light и Assassin’s Creed. У себя в блоге он часто пишет об интересных аспектах параллельного программирования, особенно применительно к Game Dev. Сегодня я бы хотел представить на суд общественности перевод одной из статей Джеффа.
Поток должен ждать. Ждать до тех пор, пока не удастся получить эксклюзивный доступ к ресурсу или пока не появятся задачи для исполнения. Один из механизмов ожидания, при котором поток не ставится на исполнение планировщиком ядра ОС, реализуется при помощи семафора.
Раньше я думал, что семафоры давно устарели. В 1960‑х, когда еще мало кто писал многопоточные программы, или любые другие программы, Эдсгер Дейкстра предложил идею нового механизма синхронизации — семафор. Я знал, что при помощи семафоров можно вести учет числа доступных ресурсов или создать неуклюжий аналог мьютекса, но этим, как я считал, область их применения ограничивается.
Поток должен ждать. Ждать до тех пор, пока не удастся получить эксклюзивный доступ к ресурсу или пока не появятся задачи для исполнения. Один из механизмов ожидания, при котором поток не ставится на исполнение планировщиком ядра ОС, реализуется при помощи семафора.
Раньше я думал, что семафоры давно устарели. В 1960‑х, когда еще мало кто писал многопоточные программы, или любые другие программы, Эдсгер Дейкстра предложил идею нового механизма синхронизации — семафор. Я знал, что при помощи семафоров можно вести учет числа доступных ресурсов или создать неуклюжий аналог мьютекса, но этим, как я считал, область их применения ограничивается.










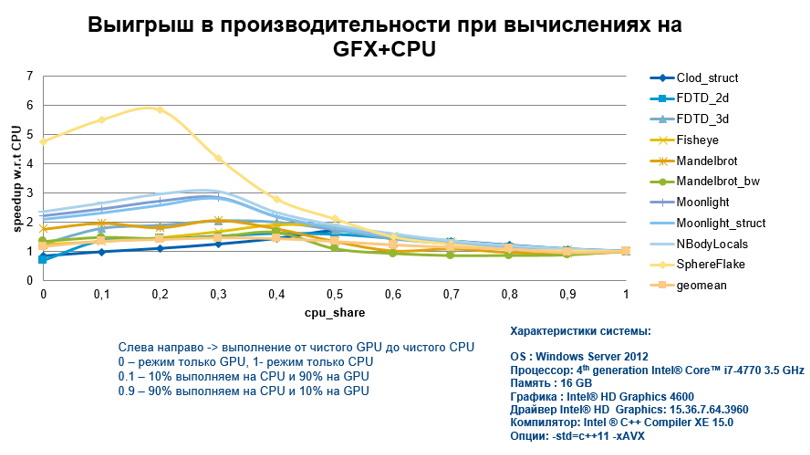
 Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.
Это последняя, на сегодняшний день, статья из цикла про внутреннее устройство конкурентных ассоциативных контейнеров. В предыдущих статьях рассматривались hash map, был построен алгоритм lock-free ordered list и контейнеры на его основе. За бортом остался один важный тип структур данных — деревья. Пришло время немного рассказать и о них.