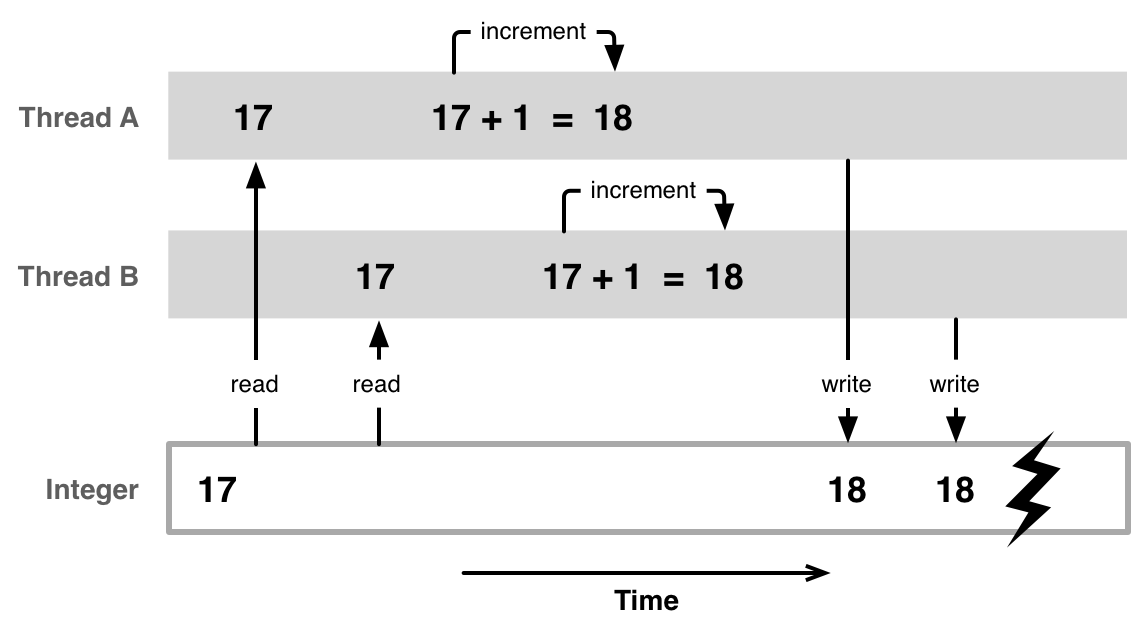
Привет, коллеги! В этой статье я покажу свой подход к написанию многопоточного кода, который помогает избежать типовых ошибок, связанных с использованием базовых примитивов синхронизации.
Демонстрация идеи будет проходить на живых примерах кода на современном C++. Большинство описанных решений я применял сначала на собственных проектах, а теперь часть этих подходов уже используется в нашей собственной микроядерной операционной системе «Лаборатории Касперского» (KasperskyOS).
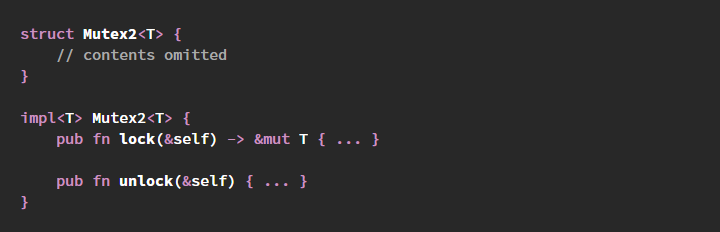
Сразу хочу оговориться, что тема многопоточности — очень большая и серьезная. И эта статья — не полноценный анализ проблем многопоточки, а только частНЫе (но довольно частЫе) кейсы, когда мы вынуждены использовать мьютексы.
Демонстрация идеи будет проходить на живых примерах кода на современном C++. Большинство описанных решений я применял сначала на собственных проектах, а теперь часть этих подходов уже используется в нашей собственной микроядерной операционной системе «Лаборатории Касперского» (KasperskyOS).
Сразу хочу оговориться, что тема многопоточности — очень большая и серьезная. И эта статья — не полноценный анализ проблем многопоточки, а только частНЫе (но довольно частЫе) кейсы, когда мы вынуждены использовать мьютексы.