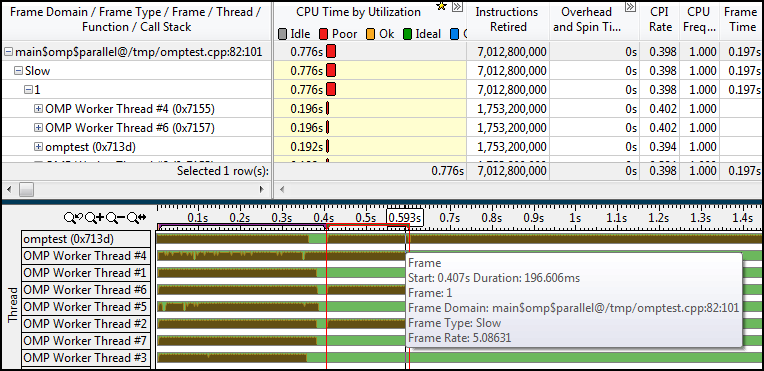
С давних времён я был большим поклонником System.Collections.Concurrent и BlockingCollection в особенности. Сколько раз это чудо инженерной мысли выручало в самых разнообразнейших ситуациях — не счесть.
С чуть менее давних времён в обиход прочно вошли async/await. Казалось бы, жизнь прекрасна, но есть одно «но»: асинхронный код миксовать с блокирующим кодом как-то не очень-то хочется. А BlockingCollection, как несложно догадаться (хотя бы из названия), в ряде случаев поток блокирует.
С чуть менее давних времён в обиход прочно вошли async/await. Казалось бы, жизнь прекрасна, но есть одно «но»: асинхронный код миксовать с блокирующим кодом как-то не очень-то хочется. А BlockingCollection, как несложно догадаться (хотя бы из названия), в ряде случаев поток блокирует.
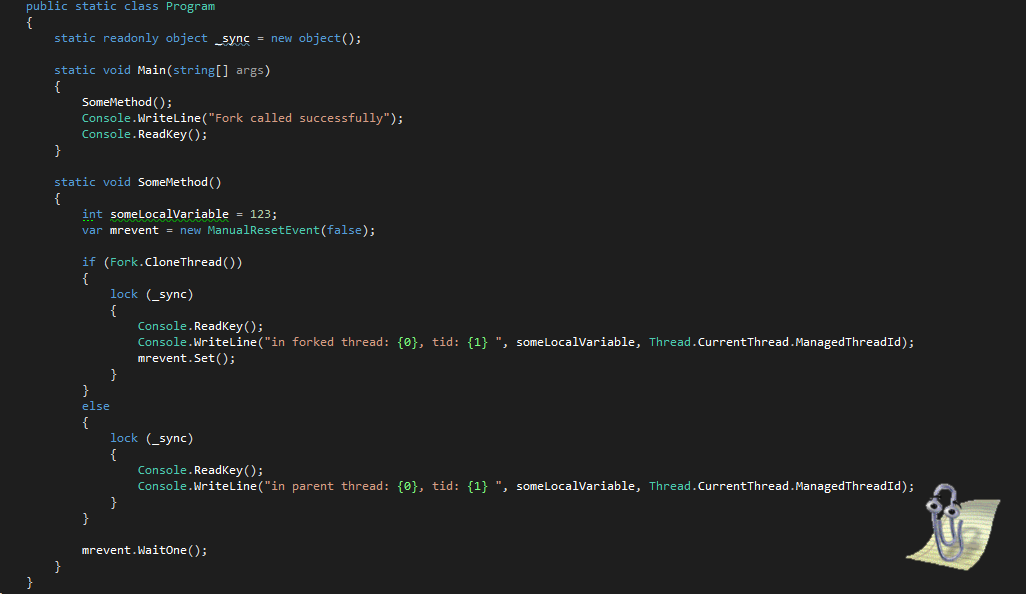

 Делаем отгружаемые сборки: взаимодействуем между доменами без маршаллинга
Делаем отгружаемые сборки: взаимодействуем между доменами без маршаллинга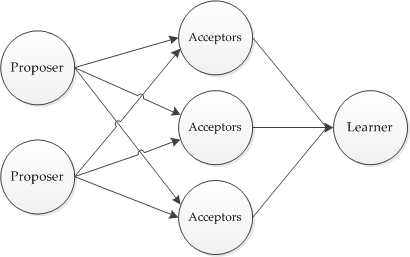












 Эта статья посвящена
Эта статья посвящена 
 C января этого года Билл Макклоски вместе с Дэвидом Андерсоном работали над тем, чтобы сделать «Файерфокс» мультипроцессовым, в этом им помогали Том Шустер (evilpie), Фелипе Гомез и Марк Хаммонд. И теперь настал момент, когда они
C января этого года Билл Макклоски вместе с Дэвидом Андерсоном работали над тем, чтобы сделать «Файерфокс» мультипроцессовым, в этом им помогали Том Шустер (evilpie), Фелипе Гомез и Марк Хаммонд. И теперь настал момент, когда они