Сегодня утром, пролистывая ленты социальных сетей, я уже в который раз встретила утверждение, что у PDF-документа есть максимально допустимый размер.
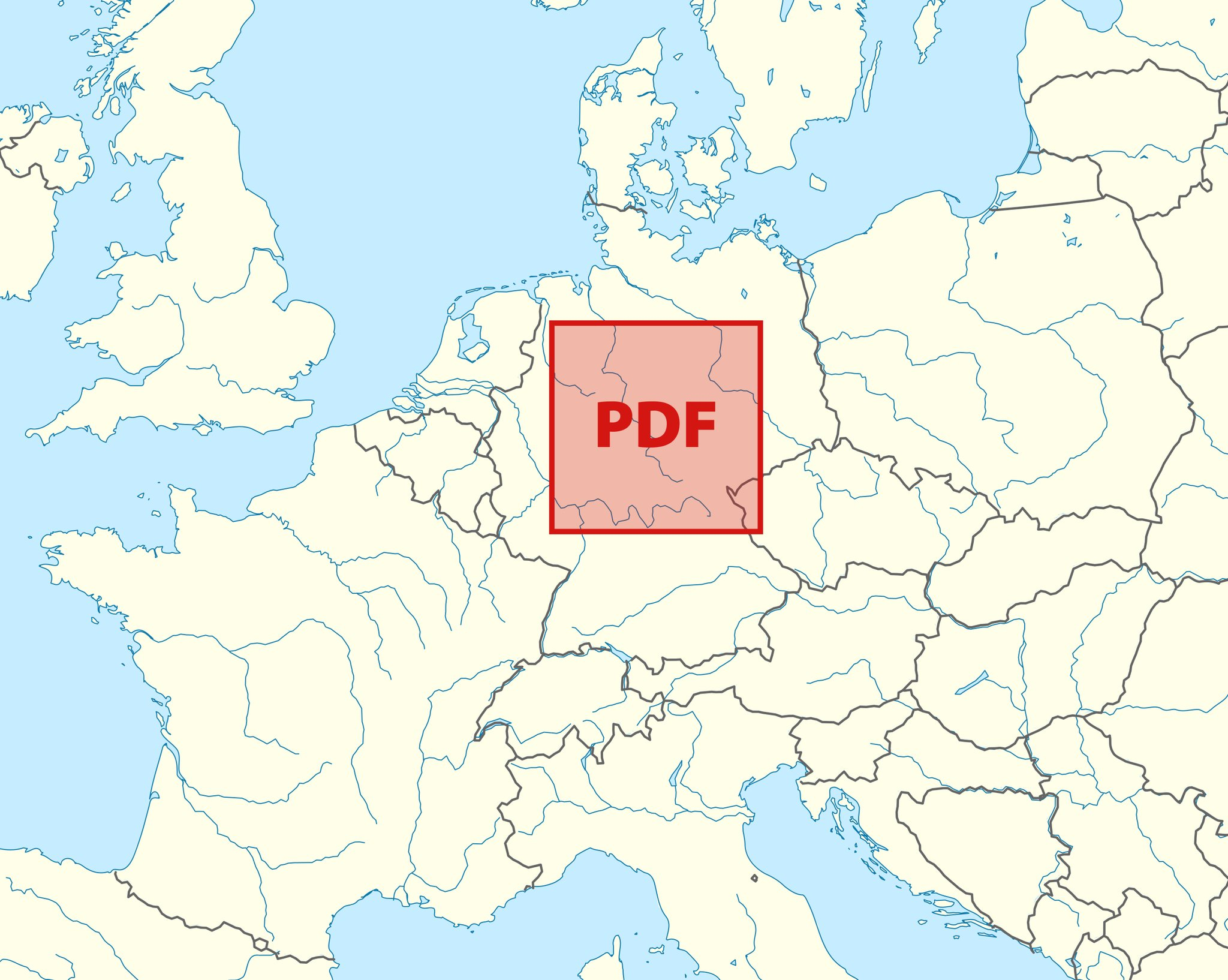
Подобное утверждение появилось на просторах интернета ещё в 2007 году. Этот твит является характерным примером постов с аналогичным заявлением, в которых оно преподносится как твёрдый факт без каких-либо подтверждающих свидетельств или объяснений. То есть мы должны просто принять, что один PDF может покрыть лишь около половины площади Германии, и нам никак не объясняют, почему его магический предел составляет 381 километр.
Тут мне стало интересно – а создавал ли кто-нибудь такой большой PDF? Насколько это сложно? А можно ли сделать документ ещё больше?
Несколько лет назад я из праздного любопытства немного поигралась с PostScript, предшественником PDF, и это оказалось очень увлекательным! Ранее мне не доводилось изучать внутреннее устройство PDF, так что здесь у меня возник для этого хороший повод.
Приступим!