Только что закончил разработку парсера pod (plain old documentation) для Perl 5, написанного на Perl 6. Грамматику сделать получилось на удивление легко – спасибо Perl 6, ведь я сам-то не особенно какой гений программирования. С помощью ребят из #perl6 я узнал много всего интересного по ходу дела, и хочу поделиться этим со всеми. Ну и код, конечно, тоже прилагается.
Кстати, рекомендую прочесть сначала моё
введение в грамматики в Perl 6, и многое в этой статье станет более ясным.
Разработка грамматики
В Perl 6 грамматика – особый тип классов для разбора текстов. Идея в том, чтобы объявить последовательность регулярок и назначить им токены, которые затем можно использовать для разбора ввода. Для Pod::Perl5::Grammar я подробно проработал спецификацию perlpod, добавляя по мере исследования стандартов нужные токены.
Конечно, есть несколько проблем. Во-первых, как определить регулярку для списков? В pod списки могут содержать списки – может ли определение включать себя? Оказывается, что рекурсивные определения возможны, если только они не совпадают со строкой нулевой длины, что приведёт к бесконечному циклу. Вот определение:
token over_back { <over>
[
<_item> | <paragraph> | <verbatim_paragraph> | <blank_line> |
<_for> | <begin_end> | <pod> | <encoding> | <over_back>
]*
<back>
}
token over { ^^\=over [\h+ <[0..9]>+ ]? \n }
token _item { ^^\=item \h+ <name>
[
[ \h+ <paragraph> ]
| [ \h* \n <blank_line> <paragraph>? ]
]
}
token back { ^^\=back \h* \n }
Токен over_back описывает весь список с начала до конца. Проще говоря, там написано, что лист должен начинаться с =over и заканчиваться с =back, а посередине может быть много всякого, включая ещё один over_back!
Для простоты я обычно называл токены так, как они пишутся в pod, хотя иногда это не получалось из-за пересечений пространств имён.


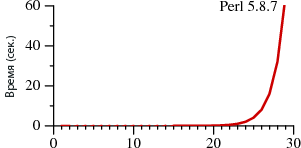
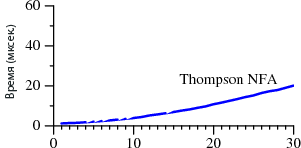

 Давным-давно, еще на заре существования Вечности, где-то в 300-х Столетиях был изобретен дубликатор массы…
Давным-давно, еще на заре существования Вечности, где-то в 300-х Столетиях был изобретен дубликатор массы…