
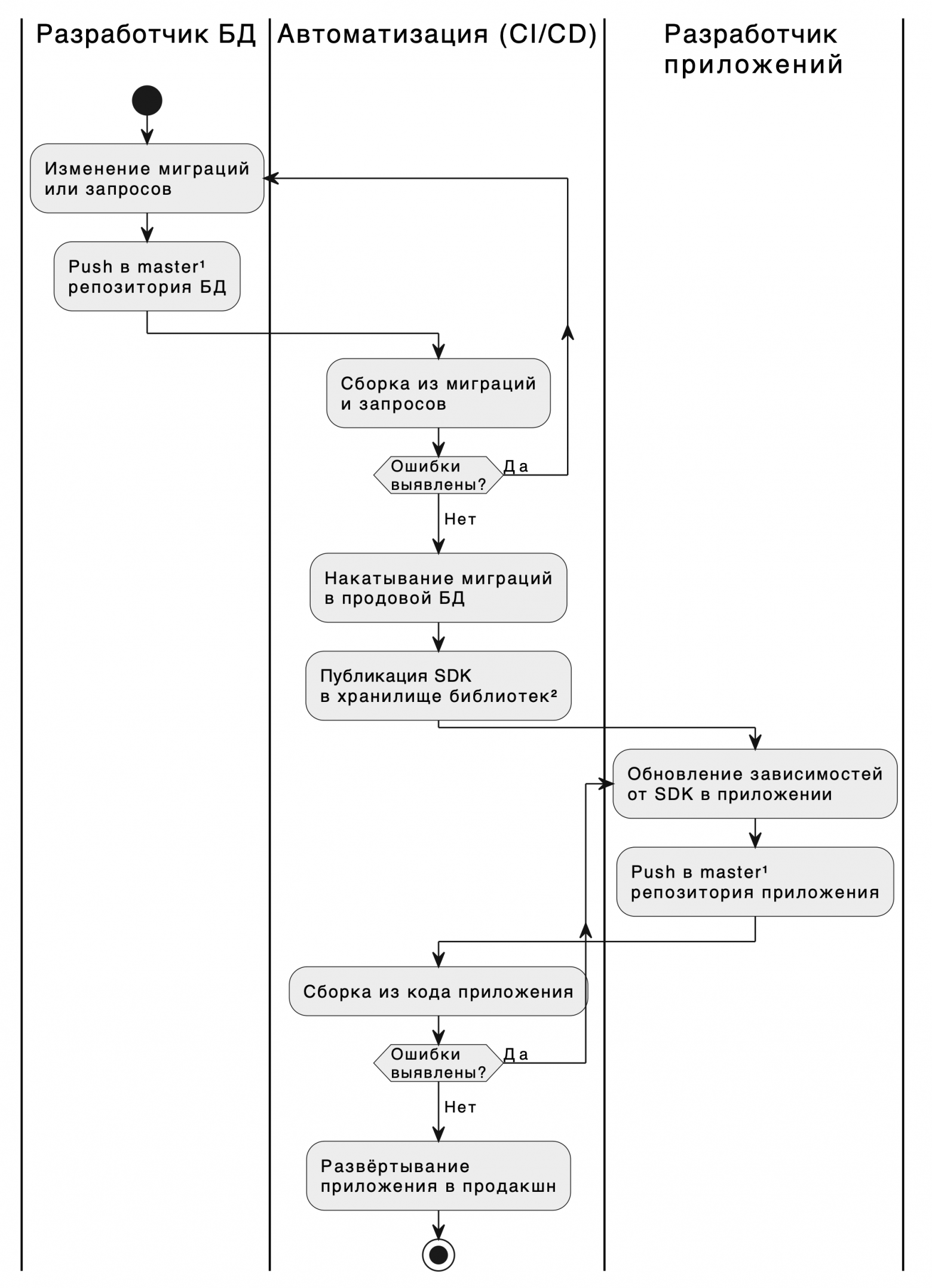
В статье рассматривается Continuous Deployment для БД с бесшовными релизами за счёт обратно-совместимых обновлений и автоматизации проверок совместимости с помощью подхода DB-First.
В статье рассматривается Continuous Deployment для БД с бесшовными релизами за счёт обратно-совместимых обновлений и автоматизации проверок совместимости с помощью подхода DB-First.

В данной публикации я поделюсь двумя основными причинами, по которым я предпочитаю избегать использования автоинкрементных полей в PostgreSQL и MySQL в будущих проектах. Вместо этого я предпочитаю использовать UUID-поля, за исключением случаев, когда есть очень веские аргументы против этого подхода.

В данной статье обсудим создание REST-сервиса в “реактивном” исполнении. Приведу примеры кода на Kotlin в двух вариантах: Reactor и coroutines

Когда я начинал писать своих первых ботов с использованием базы данных, их код был очень плохим: он расходовал лишние ресурсы, а также была плохая архитектура проекта. Поэтому я хочу поделиться с вами своими знаниями, чтобы вы не наступали на те грабли, на которые наступал я. В проекте бота, который будет использован в качестве примера в данной статье, я использовал такие технологии, как aiogram, SQLAlchemy, alembic и Docker. В качестве СУБД выступает PostgreSQL. Приятного чтения!
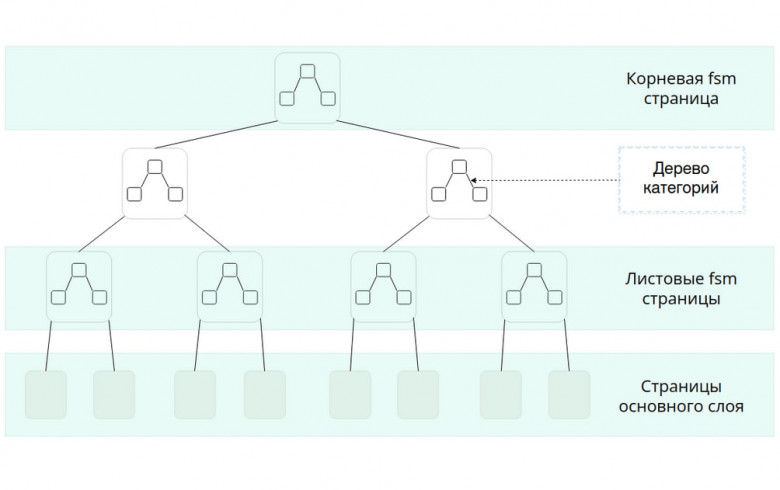
СУБД PostgreSQL способна бысто работать с огромными массивами данных благодаря множеству различных механизмов, таких как карта свободного пространства, позволяющая за короткий промежуток времени найти страницу из основного слоя с необходимым свободным пространством для вставки новых версий строк.
В этой статье мы разберемся в устройстве карты свободного пространства, а также познакомимся с алгоритмом получения страницы с необходимым свободным пространством.

Привет, Хабр!
При работе с PostgreSQL (да и в целом с любой БД) важно правильно настраивать и управлять ресурсами, такими как память, процессорное время и дисковые операции, и так далее для обеспечения лучшей производительности и стабильности работы БД.
В этой статье мы как раз и рассмотрим кратко о том, как управлять ресурсами в PostgreSQL.

Сегодня обсудим общие вопросы, связанные с миграцией баз данных на новую платформу. Как обычно, акцент сделан на системах 1С:Предприятие, как самых популярных на российском рынке. Но многие рекомендации универсальны и годятся для всех ИТ-систем.

Продолжим разбор проверок структуры базы данных, на примере PostgeSQL. Данная статья будет посвящена проверкам связанным с ограниением FOREIGN KEY (FK). Часть проверок целесообразно выполнять на регулярной основе, а некоторые позволяют лучше понять структуру проекта при первом знакомстве и применяются только один раз.


Стартует уже совсем скоро: 8 апреля, а завершится 9-го. Можно просмотреть расписание и список докладов.
Первый доклад после открытия - директора нашего отдела образования Павла Лузанова - PostgreSQL 17:
В этом году даты проведения конференции совпадают с завершением релизного цикла 17 версии. 8 апреля в 15:00 MSK прием изменений завершится. А мы сможем обсудить, что ожидать в осеннем релизе. Здесь и инкрементальное резервное копирование, изменения в логической репликации, триггер на подключение и наверняка появится что-то любопытное в начале апреля.
Следующий доклад в конференц-зале - Про-Shardman, Алексей Борщев и П. Конотопов. То, что он идёт вторым после обзорного, показывает, какое значение придают этой новой СУБД в компании. Интерес к ней действительно огромный. Они расскажут о Шардмане с точки зрения SQL разработчиков и архитекторов БД:
что такое Шардман;
чем отличается от обычного Постгреса;
типы таблиц и их использование;
как адаптировать схему БД для работы на шардах.
Конечно, будет рассказано и о других новинках компании: доклад Pooler, load balancer, proxy. Что их объединяет? Артём Галонский, pgpro_rp (приоритизация ресурсов, доложит Александр Попов) и других.

Всем привет! Меня зовут Егор, я стажёр backend-разработчик в зарплатном проекте Росбанка (он же Payroll). В этой статье я расскажу про путь становления от «зеленого» стажера до боевой единицы в команде: через что мне пришлось пройти, с какими трудностями я столкнулся и как прокачал свои скилы.
Всем привет! Я Сергей, работаю в B2B-команде Яндекс Маркета последние 3,5 года. Как уже понятно из заголовка, сейчас я вам расскажу про yet-another-миграцию с базы на базу, которая началась в середине 2021 года и заняла почти год. Получается, мемуары.
Вас ждёт рассказ о том, как мы:
- несколько месяцев чинили тесты и делали трансформер;
- десятки раз переливали данные;
- чинили баги незаметно для пользователей;
- заставили сервис работать на PostgreSQL быстрее, чем он работал на Oracle.








Продолжаю публикацию расширенных транскриптов лекционного курса "PostgreSQL для начинающих", подготовленного мной в рамках "Школы backend-разработчика" в "Тензоре".
В этой лекции мы узнаем, что такое план выполнения запроса, как и зачем его читать (и почему это совсем непросто), и о каких проблемах с производительностью базы он может сигнализировать. Разберем, что такое Seq Scan, Bitmap Heap Scan, Index Scan и почему Index Only Scan бывает нехорош, чем отличается Materialize от Memoize, а Gather Merge от "просто" Gather.
Как обычно, для предпочитающих смотреть и слушать, а не читать - доступна видеозапись (часть 1, часть 2).

Привет, Хабр!
О том, как правильно готовить кластеризацию для PostgreSQL, написано уже достаточно. А потому сегодня вашему вниманию предлагается небольшой сборник рекомендаций, как администратору СУБД под управлением Patroni гарантированно проснуться в три часа ночи от звонка из отдела мониторинга.

Чего у меня не отнять, дак это мастерства заголовка...
В какой-то момент при локальной разработке (да, в общем-то и при тестировании на иных стендах) задумываешься о том, как бы избавиться от довольно монотонных действий. Одним из них является ввод пароля в рамках процесса аутентификации в PostgreSQL. В этой статье я расскажу как слегка автоматизировать данный процесс.
Данная статья является легким переосмыслением того, что я написал на медиуме. Ибо думать я продолжаю на русском.
TL;DR исходники к вашим услугам.
В рамках любых взаимодействий мы сталкиваемся с такими сущностями как авторизация и аутентификация. Повторять в 100500 раз что есть что я не буду (но мне не лень такую длинную ремарку напечатать, ага). В рамках PostgreSQL первое обеспечивается через Roles, а второе через Privileges.
Привет, я Паша, разработчик в Yandex Infrastructure, и я катаю гусей. С 2019 года я развиваю S3-хранилище как для внутренних пользователей Яндекса, так и для клиентов Yandex Cloud. А «гусём» называется наш бэкенд S3 API: он написан на Go, а из словосочетания Go + S3 получился goose. Возможно, вы также слышали про GeeseFS — это наш высокопроизводительный FUSE-клиент для S3. C его помощью вы можете на своём ноутбуке или виртуалке подмонтировать папку, которая будет работать с бакетом S3.
Для чего нам «гуси» и прочая орнитология? Яндексовая инсталляция хранилища S3 хранит миллиарды файлов. Это огромные объёмы данных, а также метаданных. Для хранения метаданных мы научились использовать умное шардирование, и теперь сами управляем распределением занятого места и нагрузкой между шардами баз.
Так что сегодня я расскажу, как сделать так, чтобы ни один клиент, даже с самым неудобным паттерном нагрузки, не положил сервис.
Материал подойдет для студентов и тех кто только начинает создавать распределенные базы данных.
Всем доброго дня, дорогие Хабровчане! Решил поделиться созданием связаннх серверов, поскольку информации в интеренете много, но не везде описываются все мелочи.
Будучи одной из самых популярных баз данных, SQL Server славится простотой установки и настройки, функциями безопасности, среди которых есть шифрование, великолепными возможностями восстановления данных и множеством удобных инструментов.
Однако из-за ряда ограничений SQL Server постепенно теряет своих пользователей. SQL Server имеет достаточно сковывающую лицензию и стоимость обслуживания, растущую по мере увеличения размера базы данных или числа клиентов. Ее максимальный размер составляет 10 ГБ, а буферный кэш — 1 МБ. Она работает только под Windows.
Переманить же пользователей SQL Server может PostgreSQL — полностью бесплатная база данных с открытым исходным кодом. Эта база данных может похвастаться поддержкой международного сообщества и доступна под Windows, Mac, Linux, FreeBSD и Solaris. Кроме того, для нее существуют множество опенсорсных дополнений.
Я начну эту статью со знакомства с двумя бесплатными инструментами для миграции с SQL Server на PostgreSQL, затем поэтапно продемонстрирую, как выполнить миграцию между этими двумя базами данных, а в конце расскажу о полноценном решении для резервного копирования с защитой для управления сразу несколькими базами данных.
