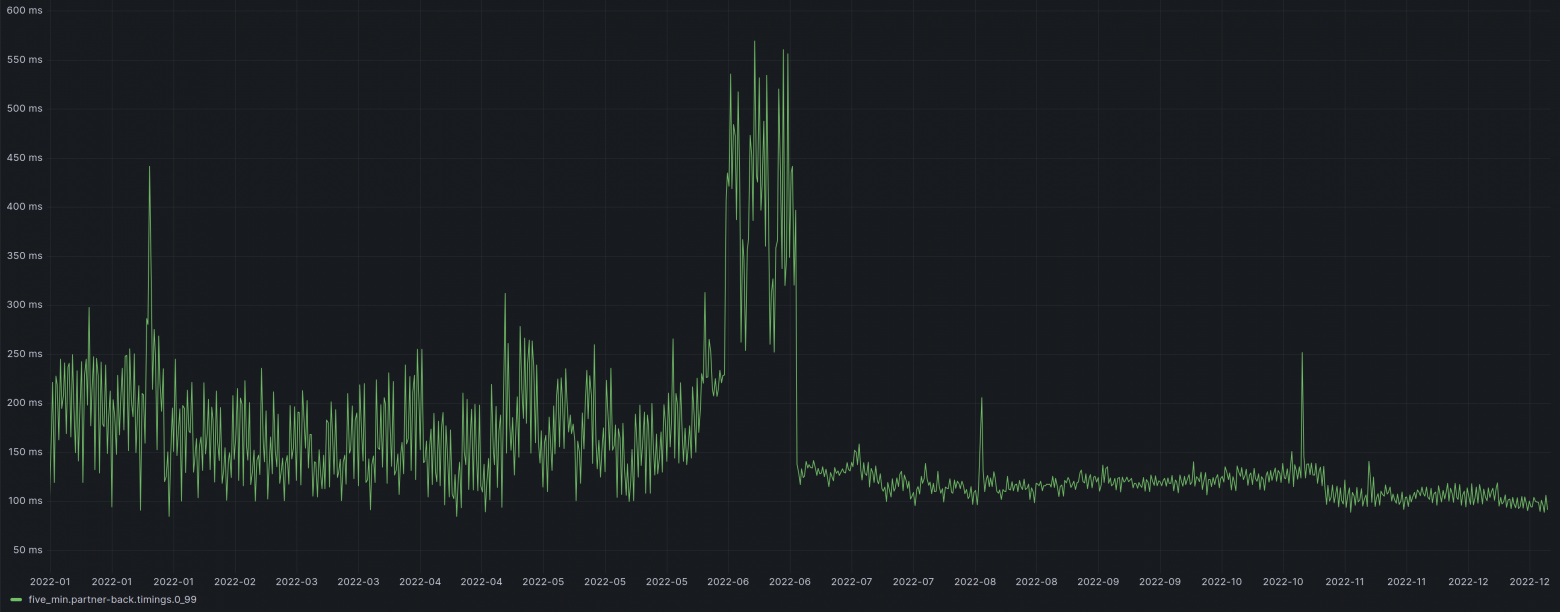
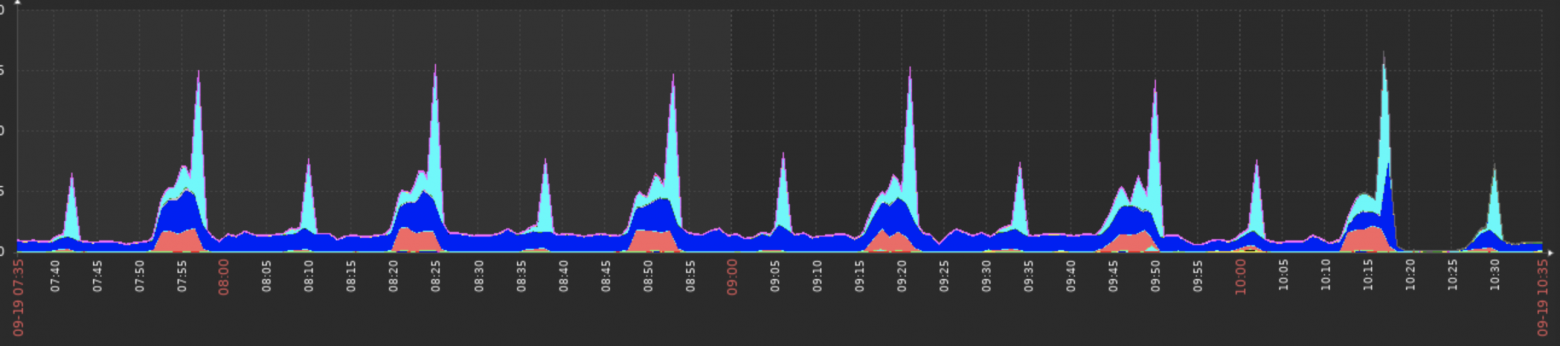
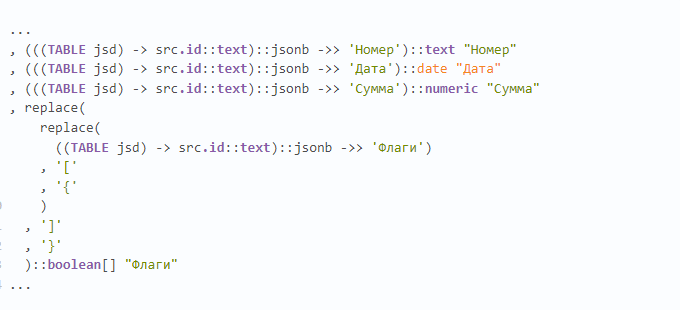
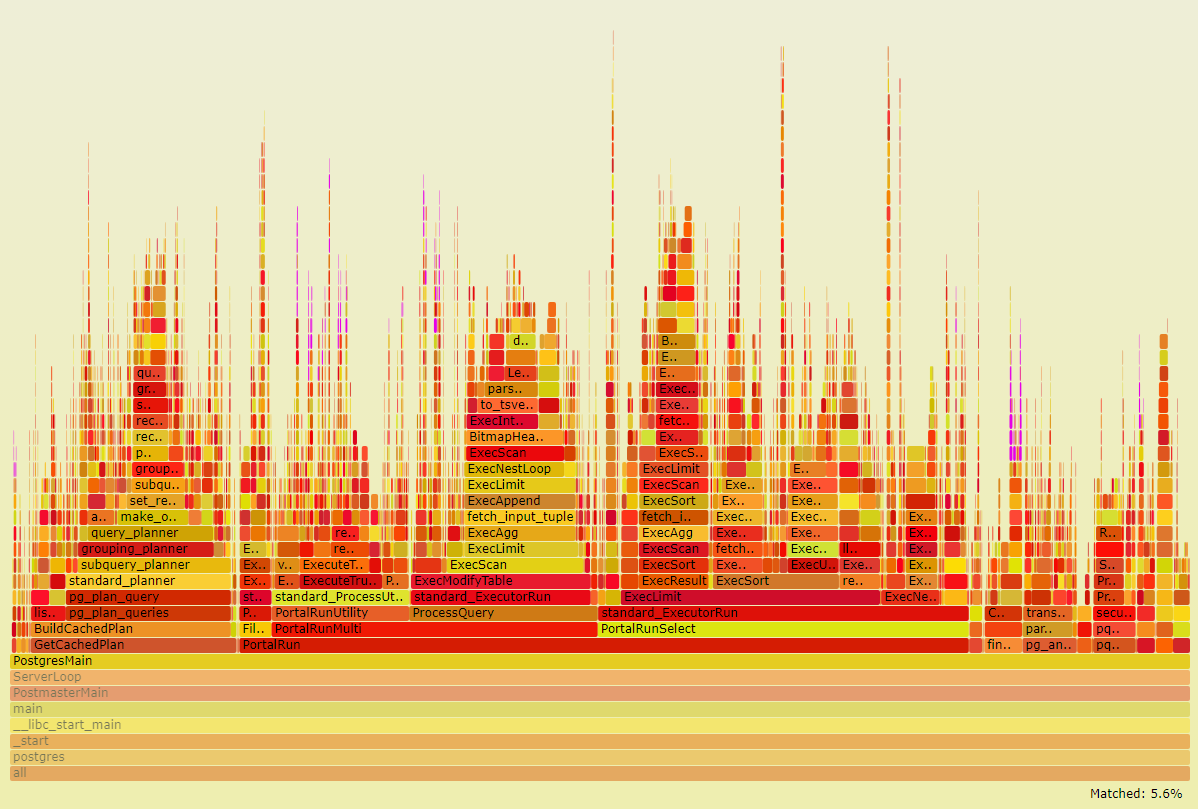
Мы много лет уже используем в качестве основной базы данных PostgreSQL. За это время он зарекомендовал себя быстрой и надежной СУБД. Однако, есть в PostgreSQL одна проблема, с которой приходится сталкиваться достаточно часто. К сожалению, реализация логики временных таблиц в нем имеет ряд недостатков, которые отрицательно сказываются на производительности системы.
Одним из свидетельств наличия проблемы является то, что для временных таблиц в Postgres Pro была добавлена специальная функция fasttrun, а в Postgres Pro Enterprise существенно доработана работа с ними (см. пункт 4).
Наиболее активно временные таблицы используют платформы, в которых разработчик не работает напрямую с базой данных, а таблицы и запросы генерируются непосредственно самой платформой. В частности, к ним относится платформа 1С или ее открытый и бесплатный аналог - платформа lsFusion.
В этой статье я опишу почему приходится использовать временные таблицы, в чем суть проблемы, и как улучшить производительность путем настроек операционной системы и PostgreSQL.