

В этой статье, посвященной Python streaming с использованием Spark и Kafka мы рассмотрим основные шаги по настройке окружения и запуску первых простых программ
В этой статье, посвященной Python streaming с использованием Spark и Kafka мы рассмотрим основные шаги по настройке окружения и запуску первых простых программ

Друзья, разбираем задачи прошедшего квеста на миллион. Для простоты, в разборе будем использовать формализованные формулировки задачи. Ознакомиться с исходными формулировками можно в самом квесте. Квест открыт и доступен для прохождения.

В главе 2 я создал простой шаблон для домашней страницы приложения и использовал поддельные объекты в качестве заполнителей для того, чего у меня еще нет, например, пользователей и записей в блоге. В этой главе я собираюсь устранить одно из многих недостатков, которые у меня все еще есть в этом приложении, в частности, как принимать входные данные от пользователей через веб-формы.
Python - это мощный язык программирования, который широко используется в области анализа данных, включая анализ погодных данных. Давайте на примере анализа годовых температур в Москве разберемся как с его помощью можно выгрузить, предобработать и визуализировать данные новичку в этом деле.
Для начала, вам потребуется получить доступ к погодным данным. Вы можете использовать API, такие как OpenWeatherMap API, для получения данных о погоде. OpenWeatherMap API предоставляет доступ к текущим и историческим данным о погоде по всему миру.

Работа с pandas.DataFrame может превратиться в неловкую кучу старого (не очень) доброго спагетти-кода. Я и мои коллеги часто используем эту библиотеку, и хотя мы стараемся придерживаться хороших практик программирования, иногда мы все равно мешаем друг другу, создавая запутанный код.
Я собрала несколько советов и подводных камней, которых следует избегать, чтобы сделать код на pandas чистым. Надеюсь, вам они тоже будут полезны. Также я буду ссылаться на классическую книгу Роберта Мартина «Чистый код: создание, анализ и рефакторинг».

Небольшой дисклеймер: перед прочтением данной статьи ознакомьтесь с первой частью, дабы вникнуть в суть происходящего. Желаю вам приятного прочтения :)
Это вторая часть о том, как я писал и продолжаю писать и улучшать эмулятор Intel 4004 с очень ограниченным функционалом на языке Python. В этот раз я решился переписать эмулятор с нуля, исправив довольно весомые ошибки предыдущего эмулятора..
SupperMapping - это класс Python, который предоставляет удобный интерфейс для работы со словарями с возможностью обратного отображения.
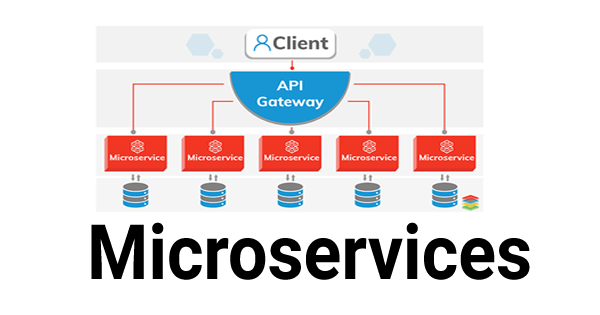
Микросервис — это подход к разбиению большого монолитного приложения на отдельные приложения, специализирующиеся на конкретной услуге/функции. Этот подход часто называют сервис-ориентированной архитектурой или SOA.
В монолитной архитектуре каждая бизнес-логика находится в одном приложении. Службы приложений, такие как управление пользователями, аутентификация и другие функции, используют одну и ту же базу данных.
В микросервисной архитектуре приложение разбивается на несколько отдельных служб, которые выполняются в отдельных процессах. Существует другая база данных для разных функций приложения, и службы взаимодействуют друг с другом с использованием HTTP, AMQP или двоичного протокола, такого как TCP, в зависимости от характера каждой службы. Межсервисное взаимодействие также может осуществляться с использованием очередей сообщений, таких как RabbitMQ , Kafka или Redis .

В Отусе я прошла курс ML Advanced и открыла для себя интересные темы, связанные с анализом временных рядов, а именно, их сегментацию и кластеризацию. Я решила позаимствовать полученные знания для своей дипломной университетской работы по ивент-анализу социальных явлений и событий и описать часть этого исследования в данной статье.
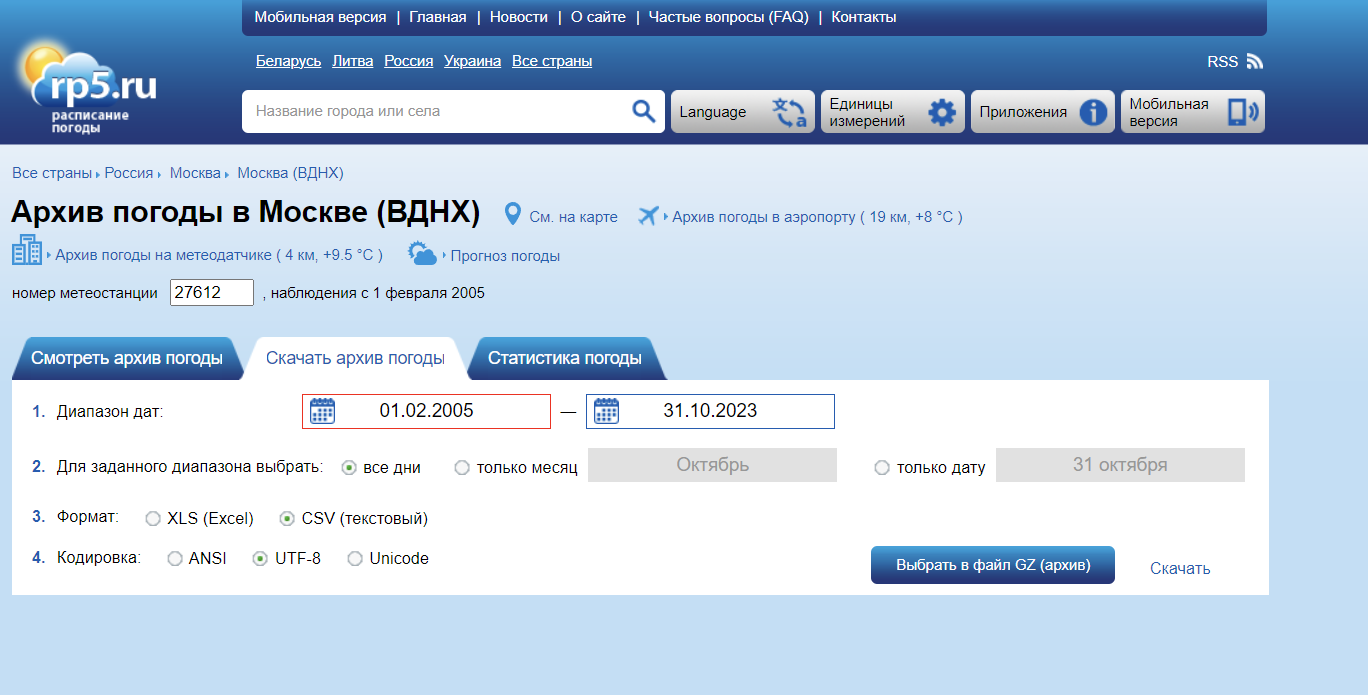
Шаг 1. Сбор данных
В качестве источника данных я взяла информационно-новостной ресурс Лента.ру, так как с него легко парсить данные, новости разнообразны и пополняются в большом объеме ежедневно. Для теста я спарсила новости за последний год (март 2023 – март 2024) с помощью питоновских BeautifulSoup и requests.
В коде происходит процедура сбора заголовка, даты и тематики новостей:

Литературы никогда не бывает много — ни художественной, ни технической. Это касается и книг по языкам программирования, включая Python. Разработчикам, как начинающим, так и опытным, нужны надёжные руководства для того, чтобы повышать свой профессиональный уровень. В сегодняшней подборке — пять книг, которые могут быть полезны для любого Python-разработчика.

project.toml или requirements.txt? Теперь у вашего языка есть возможность поэтапной типизации с помощью аннотаций типов. Хотите ей воспользоваться? Как вы реализуете конкурентность: с помощью многопоточности, Tokio или std::async? gofmt, но и о его стандартной библиотеке и согласованности. В Kotlin вам приходится гадать, что лучше использовать для ошибок: исключения или объекты Result? В случае же Go вам всё ясно – ищем err. Да, это многословно, но зато предсказуемо.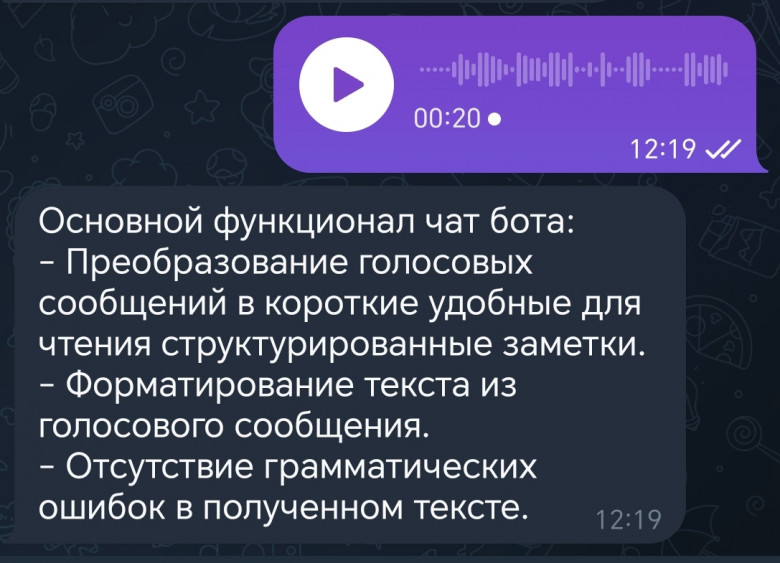
Вы когда-нибудь оказывались в ситуации, когда голова была полна идей, но записать их нет возможности? Тогда вы знаете, как бывает сложно быстро и качественно зафиксировать свои мысли. А может вам знакома ситуация, когда собеседник записывает голосовое сообщение на 5 минут с описанием какого-нибудь проекта, и вам приходится переслушивать его снова и снова, чтобы понять все детали. Столкнувшись с этим, я решил сделать Telegram-бота, который может превратить голосовое сообщение в структурированную заметку.
Объяснение того, как пользоваться моим очередным (возможно) бесполезным проектом-велопипедом.
В статье подробно объясняется большинство моментов и приннципов работы NTW3. я старался сделать создание сайтов больше похожим на создание обычным приложений, благодаря чему получился необычный подход. Надеюсь, будет интересно почитать!









Универсальные типы в python являются незаменимым инструментом, который позволяет выявлять множество ошибок на моменте написания кода, а также делает код чище и элегантнее.
Меня зовут Саша, и в своей работе часто сталкиваюсь с ситуациями, когда нужно создавать классы, работающие с различными типами, и при этом избегать дублирование кода, а также получать актуальные подсказки от type checker'а.
В этой статье я рассмотрю различные примеры использования универсальных типов и постараюсь доступно описать, в чем разница между инвариантностью, ковариантностью и контравариантностью.
Начнем с самого простого. Предположим, что у нас есть несколько типов документов: обычный и его расширение - складской. Ещё у нас есть реестр, который умеет работать с документами различных типов.

Сегодня все крупные компании сохраняют и обрабатывают большие объёмы информации, причём стремятся делать это максимально эффективным для бизнеса способом. Меня зовут Мазаев Роман и я работаю в проекте загрузки данных на платформу SberData. Мы используем PySpark, который позволяет очень быстро распределённо обрабатывать данные в оперативной памяти узлов нашего кластера на базе Hadoop. Я поделюсь способом, с помощью которого можно снизить потребление ресурсов кластера за счёт перезапуска PySpark-приложений между выполняемыми Spark-задачами, и расскажу, как это делать правильно.
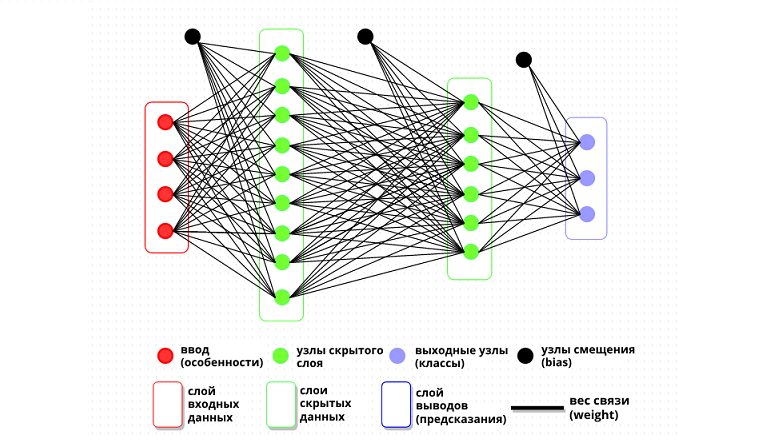
Это модное слово всё чаще используется в разговорной речи: обывателей плотнее окутывают угрозами бунта искусственного интеллекта и войны с роботами — с одной стороны, и рекламой нейросетевых продуктов — с другой. Отдельный котёл в аду — для тех, кто впаривает «курсы дата‑саентистов». А когда бедный юзернейм в поисках истины обращается к Гуглу своему любимому поисковику — то вместо простого ответа на простой вопрос, получает ещё больше вопросов — таких как тензорфлоу, сигмоида и, не дай Бог, линейная алгебра.
Здравствуй, дорогой читатель. В статье речь пойдет об обработке показаний с датчика с применением как простых алгоритмов, так и нейронной сети. Что проще – решай сам.
Во время бурения, в связи с низкой скоростью передачи данных, данные каротажа, условно говоря, неполные, и в случае ошибки передачи данных или сбоя прибора они правятся вручную. Впоследствии показания считываются с прибора. И зачастую этих данных, требующих обработки, десятки тысяч строк.

Как построить план роста? Как определить направление развития с пользой для себя и компании? Я Алексей Некрасов - лидер направления Python в МТС, программный директор по Python в Skillbox и автор канала Python — учим и работаем.
Расскажу свой кейс: рост зарплаты за год на ~100% и повышение с должности разработчика до TechLead’а.

Всем привет! Меня зовут Вячеслав Назаров, я лид аналитики промо в СберМаркете. В этой статье я расскажу, как оценивать маркетинговые кампании, если провести A/B- тесты нельзя. Еще обсудим логику в Propensity Score Matching (PSM), и то, какую пользу инструмент может принести вашему бизнесу. А в конце статьи покажу, как достаточно просто можно развернуть такую штуку у себя.

Всем привет! Случались ли у вас ситуации, когда количество DAG’ов в вашем Airflow переваливает за 800 и увеличивается на 10-20 DAG’ов в неделю? Согласен, звучит страшно, чувствуешь себя тем героем из Subway Surfers… А теперь представьте, что эта платформа является единой точкой входа для всех аналитиков из различных команд и DAG’и пишут более 50 различных специалистов. Подкосились ноги, холодный пот и желание уйти из IT?
Не спешите паниковать, под катом я расскажу о том, как контролировать потребление ресурсов DAG’ов Airflow для предупреждения неоптимально написанных DAG’ов и борьбы с ними.
Меня зовут Давид Хоперия, я Data Engineer в департаменте данных Ozon.Fintech и моим основным инструментом является Apache Airflow, поэтому настало время углубиться в детали его работы.