

В прошлом материале мы рассказали о типах файловых систем и подробно остановились на системе ZFS. В второй части подробно разберем BTRFS — файловую систему для Unix-подобных ОС.
В прошлом материале мы рассказали о типах файловых систем и подробно остановились на системе ZFS. В второй части подробно разберем BTRFS — файловую систему для Unix-подобных ОС.

cryptcrypt(3) до шестой редакции использовала код из эмулятора шифровальной машины M-209, которую американская армия использовала во время Второй мировой войны. В этой системе пароль использовался не в качестве шифротекста, а в качестве ключа, которым шифровалась константа. Кен Томпсон, Деннис Ритчи и другие создатели Unix думали, что это надёжный подход. Оказалось иначе.
С версией 1.19 в Gitea появился собственный Github-подобный CI/CD. Насколько же трудно будет прикрутить к уже работающему Gitea серверу CI/CD. Давайте проверим!
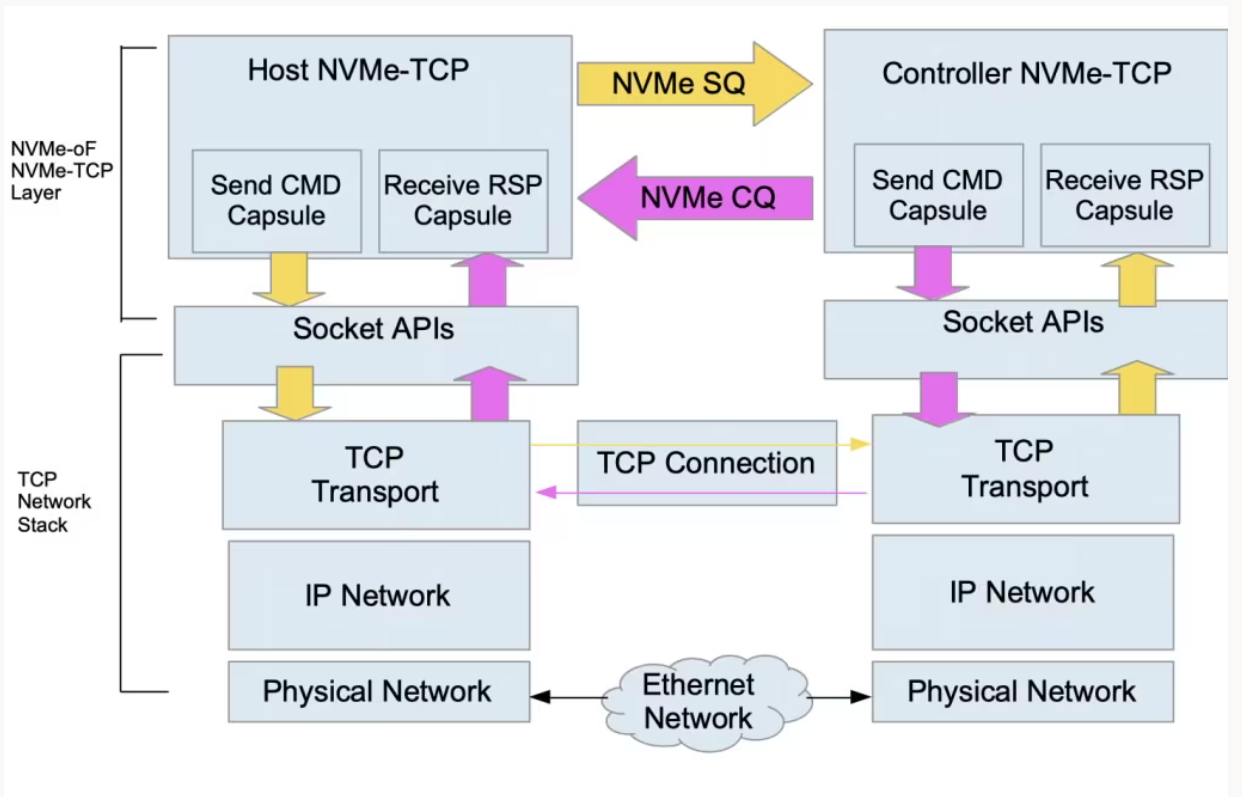
Технология NVMe через различные фабрики (далее NVMeOF) оформлена в качестве стандарта летом 2016 года, она была встроена в пятую ветку ядра Linux.
Поэтому, когда было решено мигрировать объемные базы данных с легаси-решений на общедоступные платформы, возник вопрос — можно ли применить эту технологию для увеличения дискового пространства для создания зеркал локальных дисков?
Чтобы все зеркала не вышли из строя сразу, принимать такие диски надо бы небольшими группами с нескольких машин из разных стоек. Идея показалась достойной рассмотрения, поэтому создали небольшой стенд.
Меня зовут Алексей Дрожжов, я старший инженер в билайне, и в этом посте расскажу, как мы решали эту задачу.
Задача: подключить много дисков с нескольких серверов

В современном мире, где время является ценным ресурсом, обеспечение доступности и надежности серверных решений становится ключевой задачей. В начале 2022 года, когда на рынке наблюдался дефицит полупроводников и чипов, мы поставили перед собой цель предложить качественное и эффективное серверное решение в кратчайшие сроки. И именно таким решением стали серверы из линейки vStack-R.

Привет, Хабр! На связи DevOps-инженер CarPrice Михаил Чешуин. Недавно я рассказал про переезд в новый ЦОД — а сегодня хочу немного подробнее поговорить о нашей инфраструктуре.

Ранее мы рассказали о том, как выполняется мониторинг Linux-систем. Теперь рассмотрим, как настроить Windows Server.
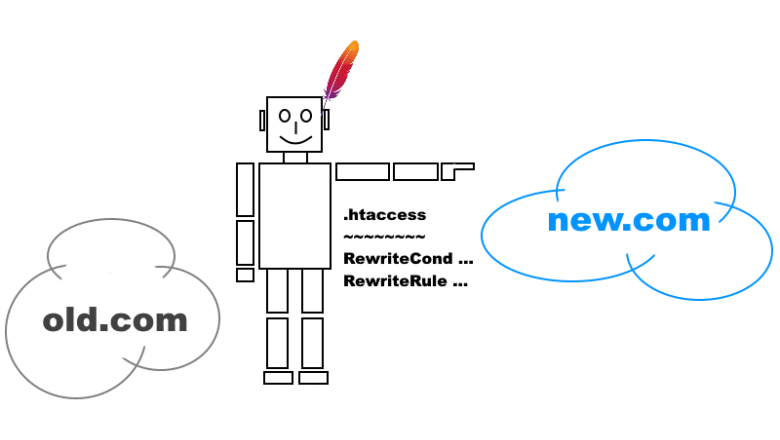
Иногда возникает необходимость в переносе сайта, обслуживаемого веб-сервером Apache, на новый домен. Снизить издержки такого переноса помогает настройка перенаправления HTTP-запросов к старому домену на новый.
Решение, описанное в этой статье:
• перенаправляет HTTP-запросы с домена old.com и всех его поддоменов на домен new.com и соответствующие его поддомены;
• исключает префикс www. путём перенаправления HTTP-запросов с доменов www.*.new.com на *.new.com;
• может использоваться для преобразования HTTP-запросов в HTTPS-запросы.

Разворачивая у нас в Туту Keycloak мы столкнулись с необходимостью создания отказоустойчивого кластера. И если с БД всё более менее понятно, то вот реализовать корректный обмен кэшами между Keycloak оказалось довольно непростой для настройки задачей.
Мы упёрлись в то, что в документации Keycloak описано как создать кластер используя UDP мультикаст. И это работает, если у вас все ноды будут находиться в пределах одного сегмента сети (например ЦОДа). Если с этим сегментом что‑то случится, то мы лишимся Keycloak. Нас это не устраивало.
Необходимо сделать так, чтобы ноды приложения были географически распределены между ЦОД, находясь в разных сегментах сети.
В этом случае в документации Keycloak довольно неочевидно предлагается создать свой собственный кастомный JGroups транспортный стэк, чтобы указать все необходимые вам параметры.
Бонусом приложу shell скрипт, написанный для Consul, который предназначен для снятия анонсов путём выключения bird и попытки восстановления приложения.

Привет, Хабр! Меня зовут Павел, я инженер по разработке инфраструктуры в компании YADRO. В апреле 2023 года разработчики Molecule представили мажорный релиз инструмента в версии 5.0.0. Помимо множества багфиксов и улучшений, пользователи получили возможность написать свой собственный драйвер, подключить его в уже существующие сценарии тестирования ролей и использовать как molecule.docker или molecule.openstack. Я не нашел или плохо искал статей об этом и решил написать поэтапное руководство по разработке собственного драйвера — от примитивного Hello world до работающего прототипа.
В статье вы найдете пример custom_docker доработки оригинального драйвера molecule.docker, описание базовых классов и методов из API Molecule, а также рассказ о нюансах разработки и эксплуатации.

Есть мнение, что Black Box подход к мониторингу хуже, чем White Box. Мол, мы получаем от него мало информации. Данных действительно немного, но мы можем развить нашу систему Black Box мониторинга и добиться довольно информативной системы контроля, которую мы условно назвали «внешнее observability».
В этой статье расскажем, как это сделать, и дадим несколько советов:
• Как поддерживать Black Box в актуальном состоянии;
• Использовать Black Box мониторинг как аудит безопасности;
• Как работать с алертами в Black Box;
• Как сделать геораспределённый мониторинг;
• Как использовать Black Box с кешированием.

В мире DevOps, где автоматизация играет ключевую роль, управление ресурсами и процессами обновления инфраструктуры в облаке является критически важной задачей. Во многих современных проектах, особенно тех, что развертываются в облачной среде AWS, используется механизм Auto Scaling Groups (ASG) с целью достижения трех основных задач: балансировки нагрузки, повышения надежности сервиса и оптимизации стоимости эксплуатации.
Представьте себе: вы работаете в компании, развертывающей свои приложения на ресурсах Amazon. Ваши приложения важны, поскольку они обслуживают тысячи пользователей ежедневно. Для этого часто используется механизм Auto Scaling Groups (ASG) с целью достижения трех основных задач: балансировки нагрузки, повышения надежности сервиса и оптимизации стоимости эксплуатации.
И чтобы ускорить процесс развертывания и упростить управление конфигурацией, вы используете предварительно подготовленные AMI образы. Эти образы создаются с помощью инструментов типа HashiCorp Packer (или других аналогичных) и содержат все необходимое для того, чтобы ваше приложение стартовало быстро и без сбоев. Для разворачивания самой инфраструктуры вы используете Terraform, который стал стандартом de facto во многих крупных компаниях, управляющих облачными ресурсами и использующими подход IaC (Infrastructure as Code).
К сожалению, ресурсы Terraform (например тот же aws_autoscaling_group) не позволяют отслеживать прогресс и успешность выполнения операции обновления ASG в рамках instance refresh, а могут лишь запустить его. Если какие-то другие части инфраструктуры (например, обновления сертификатов или dns-записей) каким-то образом зависят от состояния и версии запущенных инстансов, то желательно проконтролировать завершение процесса обновления для получения корректного состояния инфраструктуры после завершения работы terraform.
Чтобы решить данную проблему, вводим в игру Ansible...







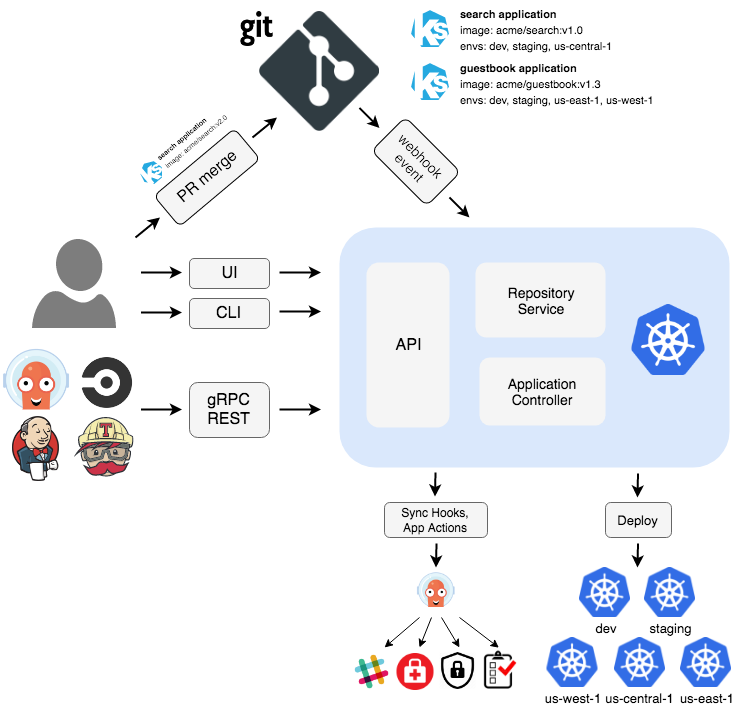
В серии статей по теме DevOps мы вместе с Lead DevOps инженером департамента информационных систем ИТМО Михаилом Рыбкиным рассказываем о проверенных инструментах выстраивания инфраструктуры, которыми с недавнего времени пользуемся сами. В предыдущих статьях мы уже рассмотрели предпосылки перехода на новую инфраструктуру и познакомились с азами Kubernetes, теперь пора перейти к следующему шагу – доставке кода. В рамках этой статьи мы подробно рассмотрим методологию GitOps и ее реализацию на примере ArgoCD.

Традиционно рынок серверов, систем хранения данных и сетевого оборудования в России был представлен зарубежными компаниями — Dell, HP, Cisco и другими. В 2022-2023 гг data-центры взяли активный курс на импортозамещение при поддержке государства и отечественных поставщиков, поэтому приходится менять устоявшиеся годами бизнес-цепочки. При этом цифровизация требует все новых и новых ресурсов. Сегодня мы заглянем на рынок ЦОДов и постараемся понять, какие у него перспективы, и как российские data-центры справляются с огромным спросом.

В работе с Incident Management-фреймворком мы в инжиниринге преследовали две основные цели: довести uptime до 99,99% (в API / SDK), и всегда знать о проблеме раньше пользователей.
В наши первые дни у нас не было всеобъемлющей системы оповещения и мониторинга. А если и была, то с кучей false-positive алертов и буквально одним-двумя графами в Kibana. Поэтому начать мы решили с создания команды Network Operations Center (NOC) - как стратегического базиса для работы с предотвращением и управлением инцидентами. Мы не только достигли показателя времени безотказной работы в 99,98%, но и увеличили нашу проактивность в выявлении инцидентов заранее: с 60% до впечатляющих 95% и выше. А все благодаря не только активному участию в улучшении платформы со стороны инженерки, но еще и благодаря метрикам First Time to Respond, Time to Acknowledge, Time to Assemble, Proactive Engineering Detection Rate, Number of Critical False Positives. В этом посте я расскажу про каждую из них, какие бывают антипаттерны, как измерять и как улучшать.
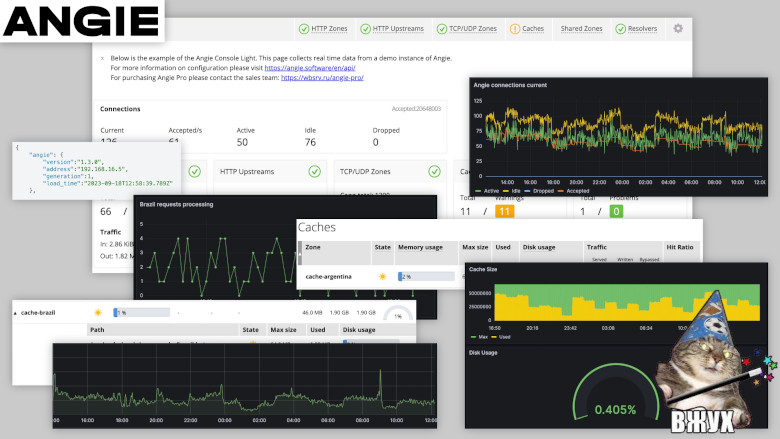
Здравствуй, дорогой читатель. Меня зовут Дмитрий. Я — системный инженер компании «Веб-сервер». На протяжении моего опыта оказания услуг технической поддержки сначала в компании Nginx, а теперь и в компании разработчика российского веб-сервера Angie, мы отвечаем на очень популярный вопрос: «Как организовать мониторинг состояния веб-сервера?». А вот так.

В компании Hostkeyв качестве основной системы виртуализации мы используем решения oVirt. При этом крайне важно поддерживать работу системы на высоком уровне, несмотря на постоянный рост инфраструктуры до десятков и сотен физических серверов. В этой статье мы кратко опишем подход к мониторингу сертификатов oVirt, реализованный в нашей компании.
В прошлых статьях мы описывали варианты использования Prometheus + Alertmanager + Node Exporter и HTTP и SSL через Prometheus blackbox_exporter.
Сегодня речь пойдет о мониторинге сертификатов в локальном хранилище двух основных компонентов oVirt: oVirt Engine и oVirt Node. Именно посредством этих сертификатов происходит взаимодействие между данными компонентами.
Почему важно следить за сертификатами: сертификаты – это канал доверия между вашими системами и пользователями. Если канал рушится, доверие пропадает. И это может привести к невиданным техническим и, что еще хуже, бизнес-проблемам.
Поэтому, поговорим о том, как сохранить репутацию, удержать клиентов и обезопасить свой бизнес от неожиданных "сюрпризов" с помощью мониторинга.
Добрый день уважаемые читатели!
Сегодня ко мне пришли с проблемой валидного сертификата для коллекции удаленных рабочих столов при подключении с macOS Ventura.
При подключении к коллекции через шлюз удаленных рабочих столов, приложением Microsoft Remote Desktop v 10.9.* теперь проверяется и FQDN имя брокера, может это было и раньше, точно не скажу, но о проблеме узнал только сейчас. В итоге, если не поставить галку доверять сертификату, подключится не получится.
Итак, избавляемся от лишних телодвижений пользователей, и присваиваем альтернативное имя брокеру.