

Читать далее
Привет, Хабр! Меня зовут Степан Родионов, я из Х5 Digital. Сегодня расскажу о поиске в интернет-магазине — типовой задаче для e-commerce, которая в теории имеет типовое решение, но на практике оказывается сложнее.
Я запускал около десятка e-commerce проектов, и в каждом из них делал поиск. Этот опыт постарался обобщить в инструкцию по созданию подобного рода систем.
Рассказывать буду на примере проекта Vprok.ru — это мой текущий, самый крупный проект. Он входит в Х5 Digital и занимает на российском рынке третье место: 10 регионов присутствия, более 72 тысяч товаров, примерно 300 RPS на товарные запросы и около 700 тысяч комбинаций товар+склад.

Знанием как искать информацию в интернете владеют многие люди. Но не все знают как делать это более эффективно. В этой статье я расскажу о том, как эффективнее работать в Google и DuckDuckGo.

Есть много причин почему доступ научным статьям и книгам должен быть свободным:
Во-первых, это прекрасно

Это третья и заключительная статья из цикла, в которой рассмотрим стандартную модель ранжирования документов в Elasticsearch.
После того как определено множество документов, которые удовлетворяют параметрам полнотекстового запроса, Elasticsearch рассчитывает метрику релевантности для каждого найденного документа. По значению метрики набор документов сортируется и отдается потребителю.
В Elasticsearch существует несколько моделей ранжирования документов. По умолчанию используется Okapi BM25.

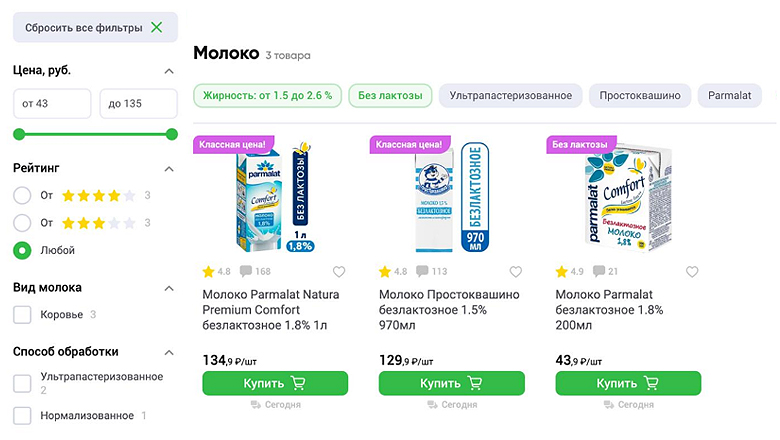
Любому сайту нужен поиск. Например, на Хабре сотни тысяч статей на самые разные темы. Чтобы отыскать ту самую через хабы и блоги, может потребоваться о-о-очень много времени. Без поиска пользователи могут не найти то, что им нужно, решить, что здесь этого нет и уйти в другой сервис.
В этой статье расскажу, через какие этапы обычно проходит внедрение поиска и как подход к нему меняется с ростом компании, какие задачи вам предстоит решить, а ещё — какие метрики помогут понять, что вы на верном пути.

Поскольку ChatGPT последних версий недосягаем для честной российской белошвейки, все мы возлагаем огромные надежды на отечественного производителя.

Это вторая статья из цикла. В первой части я рассказывал про самые базовые понятия Elasticsearch. В этом же посте разберем устройство анализа текста и немного пощупаем полнотекстовый поиск.
Несколько слов про анализ текста
Анализ текста — процесс преобразования оригинального текста в структурированный формат, оптимизированный под эффективное хранение и быстрый поиск.
Мы уже познакомились с некоторыми типами Elasticsearch, но в этом разделе будем рассматривать только два — keyword и text. Тип text анализируется для полнотекстового поиска. Тип keyword преимущественно остается без изменений для точного поиска, сортировки и агрегации.
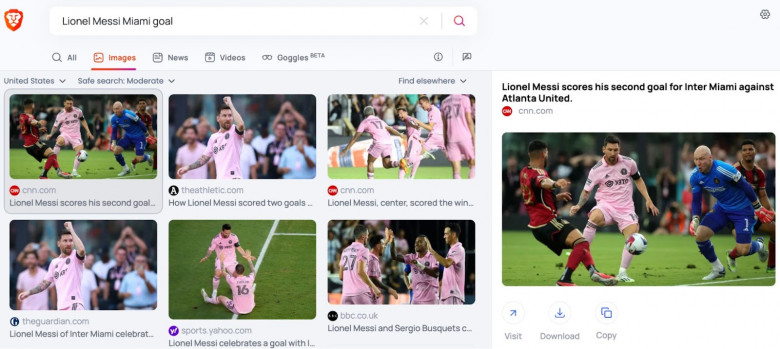
Теперь все результаты поиска по изображениям и видео в Поиске Brave обрабатываются исключительно Brave. Пользователям больше не нужно выбирать между Bing и Google для поиска по таким данным.
В мае этого года мы убрали все остававшиеся запросы к API поиска Bing для изображений и видео. На время переходного периода между удалением Bing (он применялся лишь для 7% запросов) и переходом на наше собственное решение, мы временно предоставили пользователям возможность альтернативного поиска по изображениям и видео через редирект на Bing и Google, что позволило сохранить поисковые привычки тех пользователей, которым это было важно. Теперь наш поиск независим от этих шпионящих корпораций.

Привет! Меня зовут Глеб, я разработчик команды продукта «Сервис персонализации» в SM Lab. В цикле из трех постов я расскажу про основы полнотекстового поиска в Elasticsearch.
Данный цикл статей предназначен для всех, но будет особенно актуальным для тех читателей, кто только начинает свое знакомство с Elasticsearch. Я надеюсь, каждый из вас найдет что-то полезное для себя.
В первой части обсудим самые базовые понятия Elasticsearch. Во второй части разберем механизмы анализа текста и полнотекстового поиска. В заключительной части взглянем на стандартную модель ранжирования документов в Elasticsearch.
Итак, начнём с самых базовых понятий.
В статье расскажем о ключевых аспектах SEO-продвижения нового сайта в 2023 году, обсудим важность планирования структуры сайта, эффективного исследования ключевых слов, создания ориентированного на пользователя контента и многое другое. Также рассмотрим последние тренды в SEO, такие как мобильная оптимизация, голосовой поиск, искусственный интеллект и машинное обучение, и их влияние на стратегии продвижения.
Неважно, являетесь ли вы опытным SEO-специалистом, который хочет обновить знания, или новичком, только начинающим путь в мире SEO, эта статья будет полезной для вас в любом случае. В ней вы найдете много ценных советов и рекомендаций, которые помогут увеличить эффективность ваших SEO-усилий в 2023 году.
Существует два основных фактора, определяющих специфику продвижения молодого сайта.








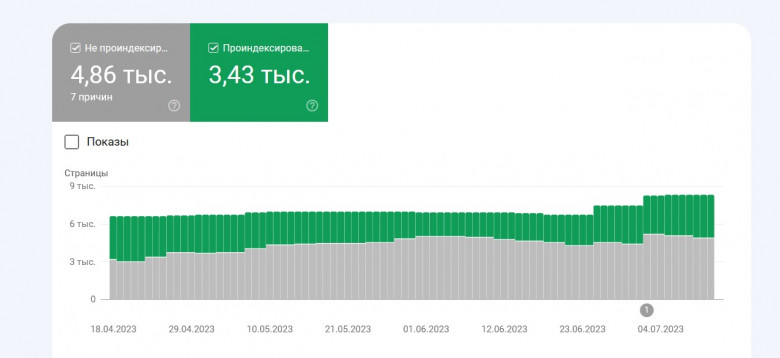
Почему некоторые молодые интернет магазины сразу получают хороший поисковый трафик, а другие не имеют результата даже через несколько лет? Все дело в индексации страниц поисковой системой Google. Если документы не попадают в индекс, то сайт не приносит трафик и клиентов.
Сегодня постараемся разобраться, что такое индексирование сайта, от чего оно зависит и как можно правильно применить бесплатный инструмент GPT3 для улучшения индекса интернет магазина.
Через несколько лет выражение «загугли это» может перестать быть актуальным. Google постепенно перестает ассоциироваться с поиском информации в Интернете. Вырастает целая категория пользователей, которая пользуется совсем другими методами поиска, и которых SEO-ссылками не проймешь.
Конечно, Google по-прежнему остается королем поиска. Платформа, по данным SimilarWeb, занимает 92% мирового рынка поисковых систем. На мобильных устройствах доминирование еще более существенное: 95%. Но все чаще пользователи публично жалуются на качество её работы, и есть немало признаков падения её качества.


Цифровой бум в поисках золота продолжается.
Мы активно стали применять метод обработки первичных растровых данных для последующего применения методов ML с целью индикации вероятной локализации оруденения. И даже есть отличные результаты.
История индикатора уходит в недалекий 2018 год, когда с развитием цифровых технологий многие разочаровались в этом, ожидая что‑то грандиозного, когда система сама покажет, где искать, где копать. Тогда и зародилась идея о том, что нужна не просто «указка», где искать, а индикатор, чтобы он как бы подсвечивал вероятные участки оруденения. В данной статье разберу пару успешных кейсов как следствие применения данной разработки.
Но сначала о самом методе...

UPD: Добавили записи докладов и слайды
Всем привет!
Меня зовут Алексей, я руководитель отдела по продукту и технологиям «Рекомендации и персонализация».
Мы уделяем много времени проектированию архитектуры, улучшению скорости и оптимизации алгоритмов:
• Ищем пути продукта и UX.
• Ускоряем рантайм поиска.
• Используем ML для рекламной платформы.
• Обучаем модели для наилучшего результата рекомендаций.
И со всем этим ещё и закапываемся в аналитику и проводим множество A/B-экспериментов.
Наша команда решает задачи, в которых используются интересные структуры данных и алгоритмы.

Лавка — сервис быстрой доставки продуктов. Один из важнейших сценариев использования сервиса для покупателя — это поиск. Примерно 30% товаров добавляются в корзину именно из его результатов. А ещё, если в пользовательской сессии был успешный запрос в поиск, вероятность совершения заказа вырастает на 10–15%. То есть, если клиенту нужен конкретный продукт и он его быстро находит через поиск, вероятность совершения заказа становится выше.
Корректная и качественная организация поиска — нетривиальная задача, поэтому иногда приходится придумывать нестандартные решения, чтобы всё работало как нужно. В этой статье я расскажу историю развития поиска в Лавке от самого начала до текущего момента. Нам пришлось объединить всю силу и мощь целых трёх движков, чтобы пользователи получали точный и актуальный результат. Параллельно погрузимся в различные технические детали, проблемы и прочие нюансы.

При построении прикладных систем, работающих с текстами, первая же задача — это отождествление слов друг с другом. Для большинства языков индо-европейской группы её решение не представляет большой сложности. И решений этих существуют сотни, а самые простые из них, как правило, дают вполне пригодные (в рамках решаемой задачи) результаты.
Английский, с его весьма условным делением на части речи и практически отсутствующим склонением/спряжением, вполне прилично описывается простыми моделями выделения неизменяемой основы слова (стеммерами) с небольшим словариком исключений буквально на сотню слов. Слова немецкого прекрасно бьются на части по формальным признакам, словарю корней и принципу «максимума суммы квадратов длин». Системы окончаний других европейских языков также достаточно просты.
Со славянскими языками сложнее из-за развитой грамматики и глубокой изменчивости — любое русское прилагательное, к примеру, имеет как минимум двадцать четыре разных грамматических формы: три рода и множественное число, да по шесть оставшихся на сегодня падежей. А то и все двадцать девять, если принять во внимание краткие формы (широк, широка, широки) и образуемое от многих прилагательных наречие.
Для решения задачи отождествления разных форм существует некоторое количество реализаций морфологических анализаторов русского. Но почти все они — во всяком случае, заслуживающие внимания — растут из одного корня...
(По материалам внутреннего семинара компании МойОфис)