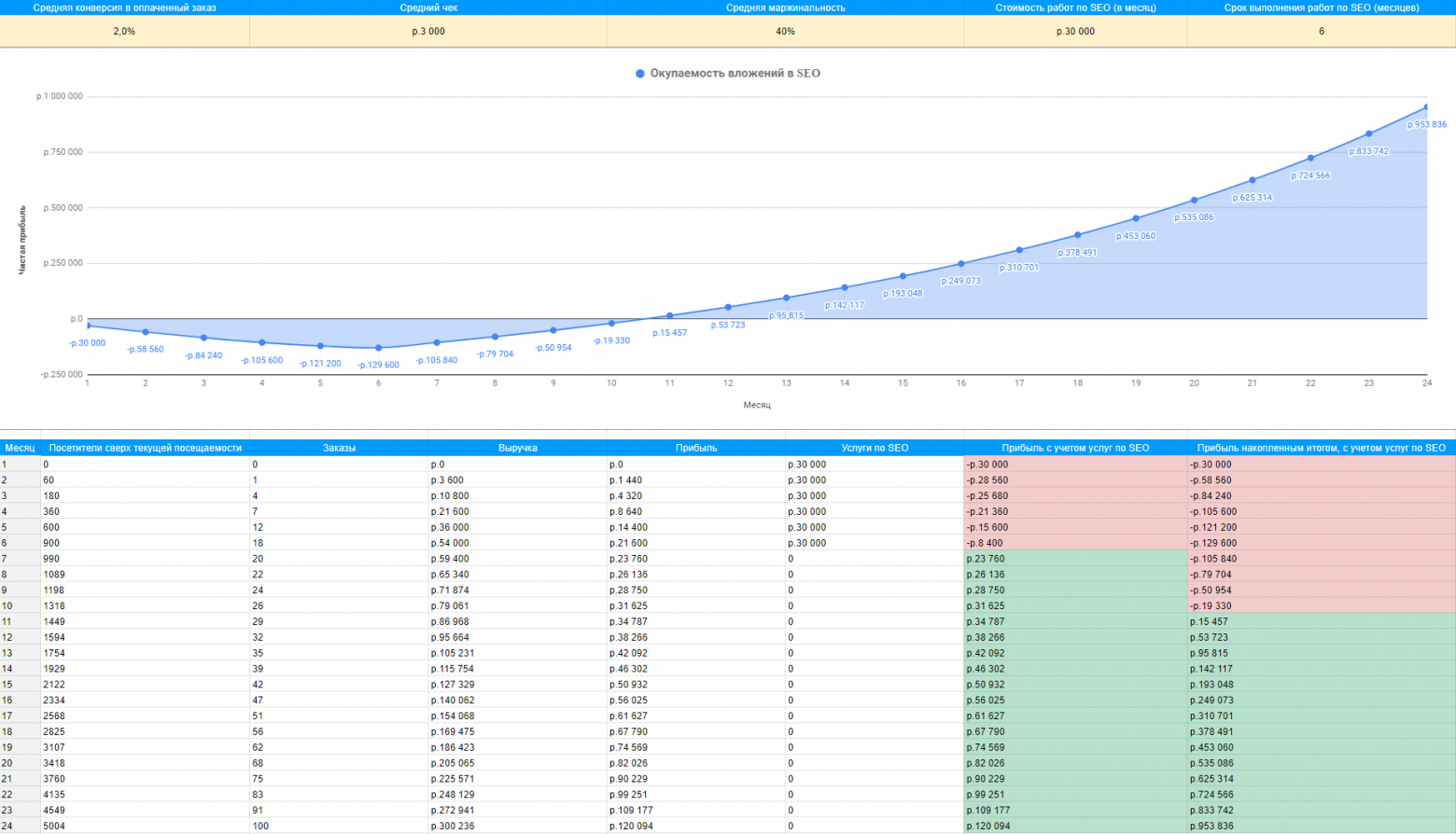
По запросу [форма] мы должны угадать, что именно нужно покупателю: выпечка, наращивание ногтей, косплеить медсестру или калибратор кубов бетона. Задача — быстро понять, кто перед нами и что сделает человека счастливым.
Я работаю над качеством поиска в Яндекс.Маркете. И качество поиска прямо связано с ощущением счастья пользователя от шопинга. Счастье нужно измерять. Самый очевидный способ — посмотреть, купил ли что-нибудь пользователь. Но мы не всегда приходим в магазин или на Маркет, чтобы взять что-то конкретное.
Человек может:
- Формулировать требования к покупке по мере сравнения вариантов.
Пример с соковыжималкойПредположим, он ищет соковыжималку, но ещё не знает, какие они бывают. По мере изучения товаров он примерно начинает понимать, что хочет. На старте у него нет ни фиксированного бюджета, ни требований, только мечта. Дальше нужно сопоставить мечту с конкретной карточкой товара. С точки зрения метрики покупки, пользователь будет довольно долго бесцельно бродить в начале — но мы понимаем, что эта часть была очень важна, там он изучал предложение и понимал, как устроен мир. - Приходить с примерным бюджетом и выбирать что-то под него, например, при поиске подарка. В этой ситуации у пользователя даже нет мечты, он ходит по категориям и ищет что-то, что его «зацепит».
- Более-менее точно понимать, что хочет купить (часто вплоть до модели товара), но искать лучшее предложение.
- Знать модель товара и проверять, насколько честна цена на неё, насколько хороши отзывы и так далее.
То есть с точки зрения человека покупка — далеко не единственная цель. Маркетплейс используется и для развлечения, и для изучения предложений, и даже для проверки цены, когда стоишь в очереди к кассе в реальном магазине.
Мы работаем над улучшением поиска по товарам. Поэтому нам нужна была метрика, которая показывает удовлетворённость людей тем, что мы показываем на выдаче. Мы искали её в несколько итераций, и сейчас я хочу рассказать о том, что мы уже придумали.