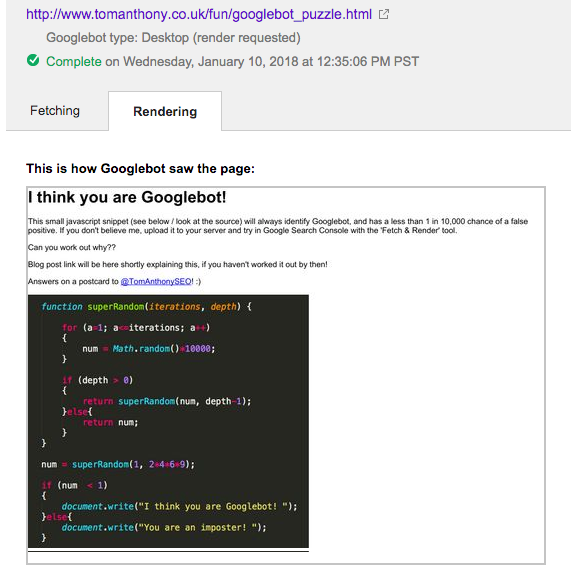
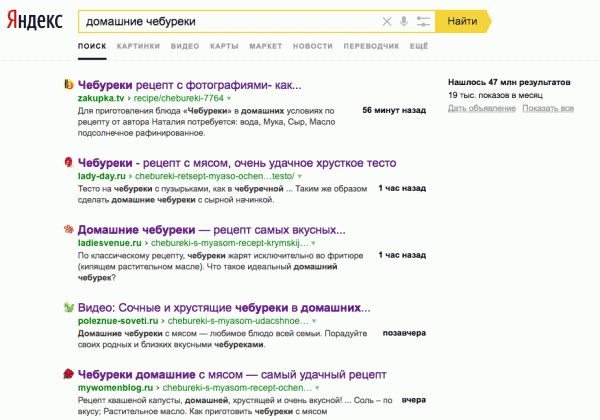
Представляем вашему вниманию перевод первой части материала, который посвящён поисковой оптимизации сайтов, построенных с использованием JavaScript. Речь пойдёт об особенностях сканирования, анализа и индексирования таких сайтов поисковыми роботами, о проблемах, сопутствующих этим процессам, и о подходах к решению этих проблем.
В частности, сегодня автор этого материала, Томаш Рудски из компании Elephate, расскажет о том, как сайты, которые используют современные JS-фреймворки, вроде Angular, React, Vue.js и Polymer, выглядят с точки зрения Google. А именно, речь пойдёт о том, как Google обрабатывает сайты, о технологиях, применяемых для анализа страниц, о том, как разработчик может проанализировать сайт для того, чтобы понять, сможет ли Google нормально этот сайт проиндексировать.

JavaScript-технологии разработки веб-сайтов в наши дни весьма популярны, поэтому может показаться, что они уже достигли достаточно высокого уровня развития во всех мыслимых направлениях. Однако, в реальности всё не так. В частности, разработчики и SEO-специалисты всё ещё находятся в самом начале пути к тому, чтобы сделать сайты, построенные на JS-фреймворках, успешными в плане их взаимодействия с поисковыми системами. До сих пор множество подобных сайтов, несмотря на их популярность, занимают далеко не самые высокие места в поисковой выдаче Google и других поисковых систем.







 Всем привет!
Всем привет!