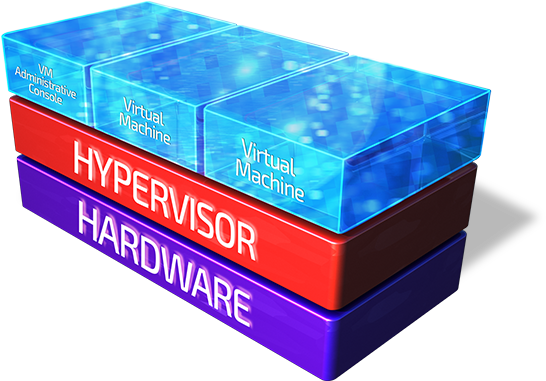
Системы хранения данных все чаще используются в IT-инфраструктуре сегмента малого и среднего бизнеса. Рабочие места мигрируют в виртуальную среду, а для хранения данных уже не достаточно обычной «файловой помойки» в виде старого железа набитого дисками. Поэтому для многих небольших компаний рано или поздно встаёт вопрос выбора Enterprise СХД начального уровня. Задачи перед системой хранения становятся типовые: обеспечить необходимую производительность, отказоустойчивость и совместимость с существующей IT-инфраструктурой. Но, к сожалению, решающим фактором выбора является обоснованность стоимости решения.
Системы хранения данных все чаще используются в IT-инфраструктуре сегмента малого и среднего бизнеса. Рабочие места мигрируют в виртуальную среду, а для хранения данных уже не достаточно обычной «файловой помойки» в виде старого железа набитого дисками. Поэтому для многих небольших компаний рано или поздно встаёт вопрос выбора Enterprise СХД начального уровня. Задачи перед системой хранения становятся типовые: обеспечить необходимую производительность, отказоустойчивость и совместимость с существующей IT-инфраструктурой. Но, к сожалению, решающим фактором выбора является обоснованность стоимости решения.У производителей первого эшелона есть подходящие продукты, отвечающие всем требованиям к функционалу и уровню сервиса. Но вот с совместимостью и стоимостью владения подобных решений есть определённые трудности. Поэтому данная статья посвящена альтернативе А-брендам — системе хранения данных Infortrend.
Infortrend — это представитель Тайваньских производителей с узкой специализацией на системы хранения данных. За более чем 20-летний период работы по проектированию и производству собственных СХД, Infortrend создал продукт, успешно конкурирующий с представителями крупных мировых брендов.








 Прежде всего, давайте договоримся: те, кому технология Intel vPro не в новинку, могут не тратить времени на всю вступительную часть статьи, сразу заказать Intel Core I7 7700 c 16 GB DDR4 240 SSD c защитой от DDOS за 3800руб в мес, без установочного платежа (ссылка в конце статьи). Но нам кажется, что пока не все оценили преимущества удалённого доступа при помощи Intel vPro – который в нашем дата-центре предоставляется ко всем выделенным серверам без серверных платформ. А значит, нужно разобраться: что это за технология такая, какая она реализовывается, и какие проблемы решает.
Прежде всего, давайте договоримся: те, кому технология Intel vPro не в новинку, могут не тратить времени на всю вступительную часть статьи, сразу заказать Intel Core I7 7700 c 16 GB DDR4 240 SSD c защитой от DDOS за 3800руб в мес, без установочного платежа (ссылка в конце статьи). Но нам кажется, что пока не все оценили преимущества удалённого доступа при помощи Intel vPro – который в нашем дата-центре предоставляется ко всем выделенным серверам без серверных платформ. А значит, нужно разобраться: что это за технология такая, какая она реализовывается, и какие проблемы решает.