
Хочу рассказать историю жизни сервера в кампусной сети Новосибирского университета, которая началась в далеком 2004 году, а так же этапы его оптимизации и даунгрейдинга.
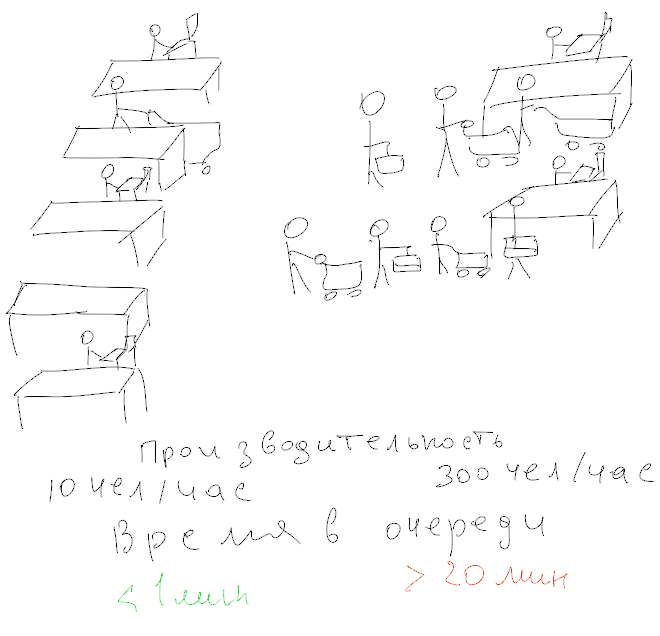
Многие вещи в статье покажутся общеизвестными хотя бы по той причине, что речь пойдет о событиях почти десятилетней давности, хотя на тот момент это были передовые технологии. По той же причине кое что вообще потеряло актуальность, но далеко не все, так как сервер до сих пор живет и обслуживает сетку из 1000 машин.
Многие вещи в статье покажутся общеизвестными хотя бы по той причине, что речь пойдет о событиях почти десятилетней давности, хотя на тот момент это были передовые технологии. По той же причине кое что вообще потеряло актуальность, но далеко не все, так как сервер до сих пор живет и обслуживает сетку из 1000 машин.

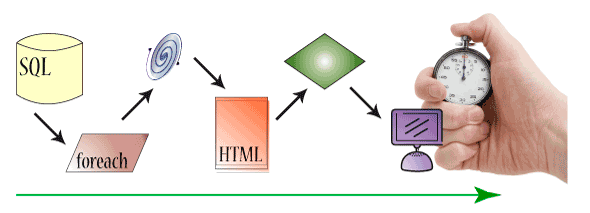
 Подробные инструкции, которые даются на
Подробные инструкции, которые даются на 










{kind=link}
{kind=link}